pdfparser

pdfparser copied to clipboard
Is there preferences, that detect this text as separate fragments?
http://www.eurasiancommission.org/ru/act/trade/catr/ett/Documents/ru.38_2022.pdf on 4th page
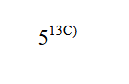
This great lib parse this fragment like 513C), but I need to parse it with some delimiter, like "5 13c)" or something like this.