skypilot
 skypilot copied to clipboard
skypilot copied to clipboard
Published
20 hours ago •
 skypilot-org
skypilot-org
Add Imagenet Benchmark
To test out how well goofys performs for a real deep learning workload, I made this benchmark.
ImageNet Dataset Information
Stats
- 1M training images, and 50K val images
- Size: about 150 GB.
- S3 bucket in us-east-2 URL
Dataset hierarchy
| datasets/ | ILSVRC2012/ | imagenet/ | meta.bin | ||
|---|---|---|---|---|---|
| train/ | class0/ | ~1000 images (~150KB) | |||
| class1/ | ~1000 images (~150KB) | ||||
| class2/ | ~1000 images (~150KB) | ||||
| ... | |||||
| class999/ | ~1000 images (~150KB) | ||||
| val/ | class0/ | 50 images (~150KB) | |||
| class1/ | 50 images (~150KB) | ||||
| ... | |||||
| class1000/ | 50 images (~150KB) |
Resnet-18
It is possible to reach a reasonable speed with s3 (image-based) training as the EBS by increasing the number of data load workers.
- 1.4x slower than the same number of loaders on EBS.
- 64 workers on S3 get a similar speed with 4 load workers on EBS.
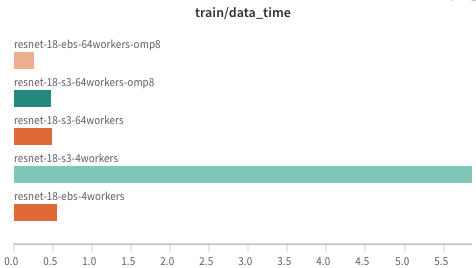
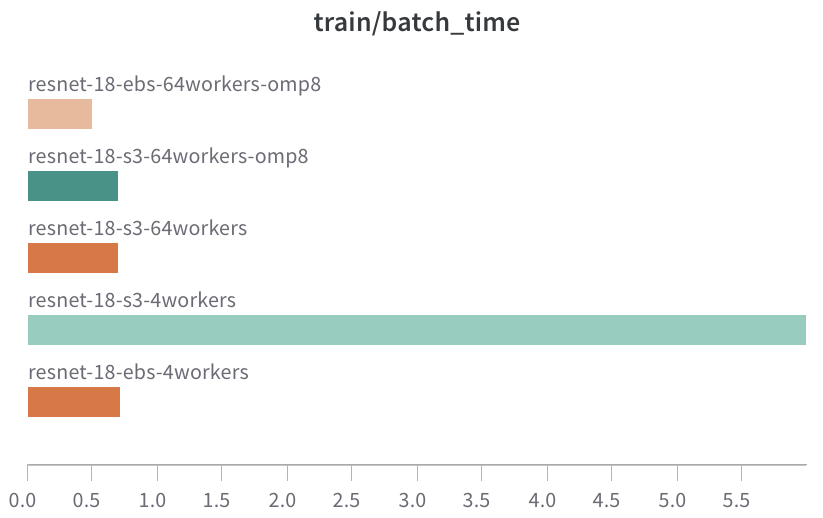
More details can be found in result sheet / Wandb.
This is awesome, thanks for running this! Two thoughts:
- Could you also post some stats on the dataset? Number of files, size of each file, directory hierarchy (if possible)?
- Can we run a similar benchmark on a dataset which uses large binary files to store the dataset? Curious to see the numbers there..
- Could you also post some stats on the dataset? Number of files, size of each file, directory hierarchy (if possible)?
Great suggestions! Added the information about the dataset in the description, with the link to the publicly accessible s3 bucket.
- Can we run a similar benchmark on a dataset which uses large binary files to store the dataset? Curious to see the numbers there.
I think @michaelzhiluo has the ImageNet bucket with tf-records in it. Will figure out if we can run the PyTorch code with it later.