Error in tuneR_loader("resources/chaffinch.wav"): could not find function "tuneR_loader"
For some reason, tuneR_loader on this line in the wavelet code resulted in a could not find function error.
This line failed:
wav <- tuneR_loader("resources/chaffinch.wav")
The solution was to call the tuneR_loader function with ::::
wav <- torchaudio:::tuneR_loader("resources/chaffinch.wav")
Hi Nathan, thanks for pointing this out!
After the book release, there has been a major refactoring in torchaudio:
https://github.com/mlverse/torchaudio/blob/main/NEWS.md#breaking-changes
The only user-visible function is now torchaudio_load().
I see. That's because mono is from tuneR, and the default (as well as recommended) backend now is av.
You could either switch backends (using the un-exported set_audio_backend()), like so
wav_2chan <- "/tmp/chaffinch.wav"
torchaudio:::set_audio_backend("tuneR")
wav <-torchaudio_load(wav_2chan)
tuneR::mono(wav)
or do the conversion to mono using av, like this:
wav_1chan <- "/tmp/chaffinch_1.wav"
av::av_audio_convert(wav_2chan, channels = 1, output = wav_1chan)
wav <-torchaudio_load(wav_1chan)
attr(wav, "channels")
In both cases, you can then continue with transform_to_tensor().
Thank you. That worked on Linux. (Note, I had to install libavfilter-dev to get the second solution to work on Ubuntu). Unfortunately, I get different results for Windows. The code runs as expected, but I get this plot:
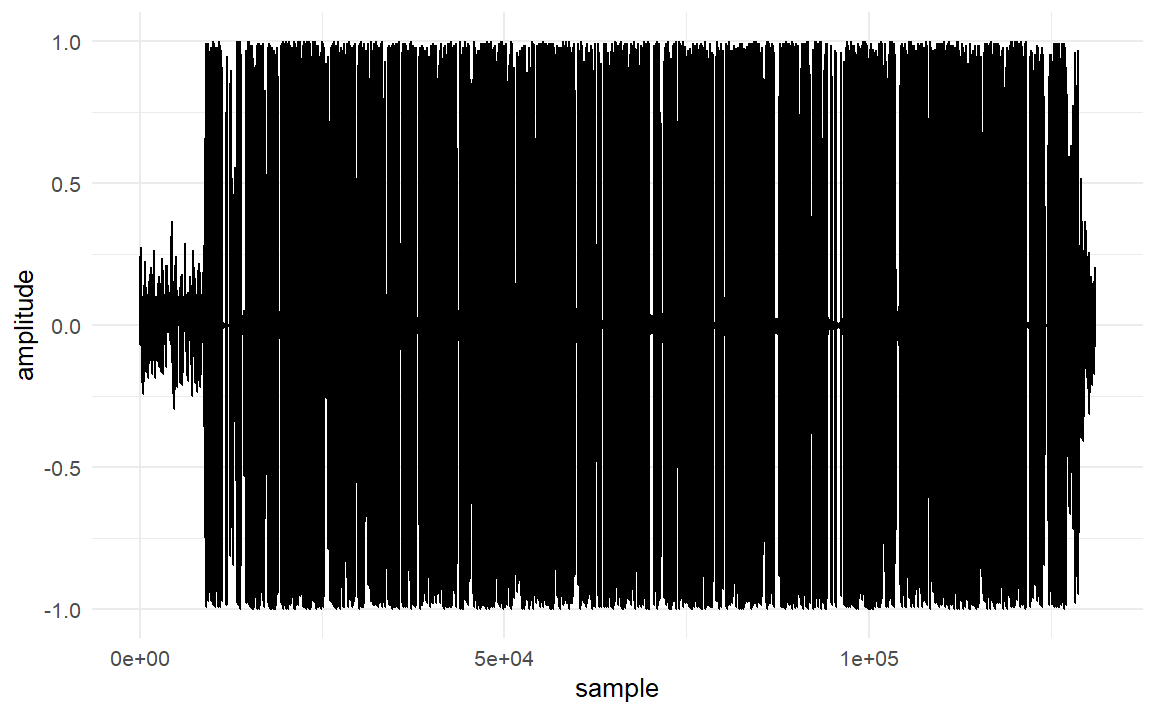
Instead of this one:
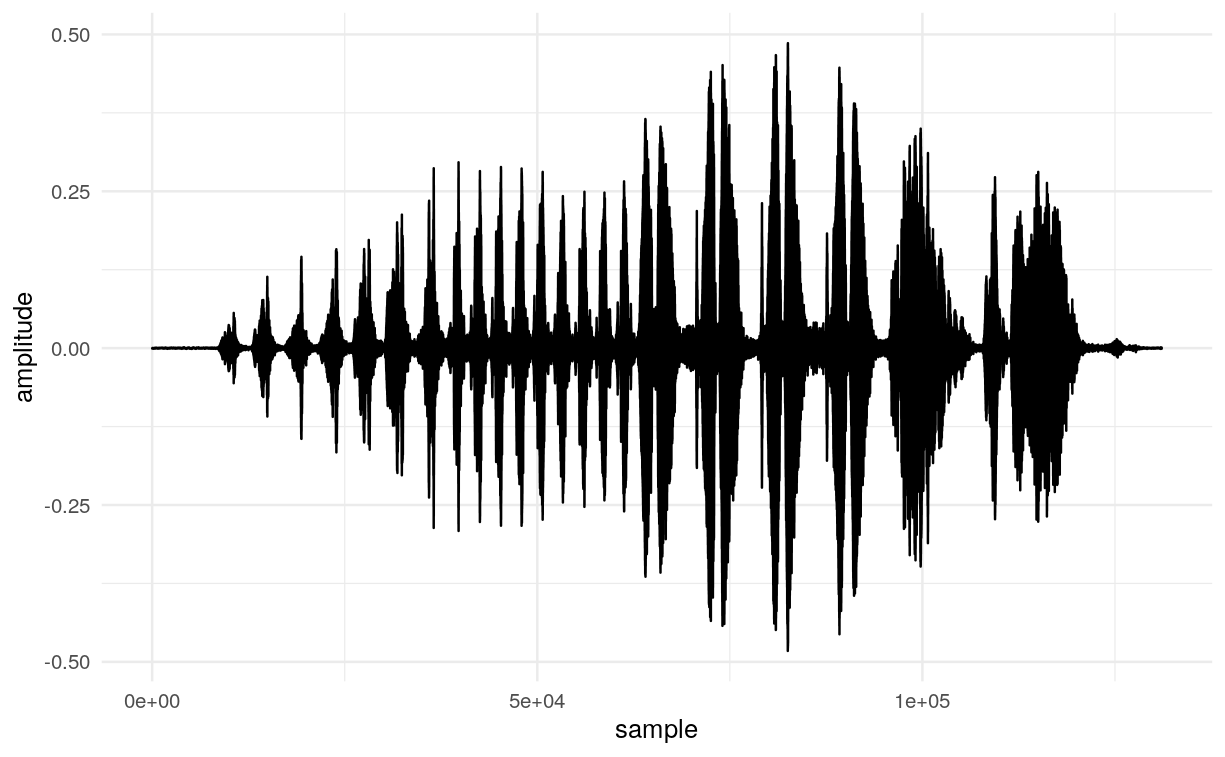
Hm, that is weird. Maybe it is just a matter of scaling.
Can you find out at which point the difference in the values is introduced?
Is it already present after conversion to single-channel, or after torchaudio_load(), or after transform_to_tensor()?
Then, can you provide a sample, so we can see if really it is a scaling effect?