malib
 malib copied to clipboard
malib copied to clipboard
3s5z in PyMARL can quickly reached to win_rate of 1 and where is the config for SMAC of malib?
Thanks for this nice repo. I'm interested in MARL for smac. I have some problem about this repo.
-
In the page 18 of your arxiv paper, you mentioned that "For the scenario 3s5z, however, both of MALib and PyMARL cannot reach 80% win rate." However, I run the PyMARL original code with his default config
python3 src/main.py --config=qmix --env-config=sc2 with env_args.map_name=3s5z, the win rate quickly reached 1 for these two smac versions (4.10 and 4.6.2).
-
I would like to use this repo to run smac, but I can't find the corresponding config in examples, will this section be opend source? Thank you.
Thanks for this nice repo. I'm interested in MARL for smac. I have some problem about this repo.
- In the page 18 of your arxiv paper, you mentioned that "For the scenario 3s5z, however, both of MALib and PyMARL cannot reach 80% win rate." However, I run the PyMARL original code with his default config
python3 src/main.py --config=qmix --env-config=sc2 with env_args.map_name=3s5z, the win rate quickly reached 1 for these two smac versions (4.10 and 4.6.2).- I would like to use this repo to run smac, but I can't find the corresponding config in examples, will this section be opend source? Thank you.
Thank you so much for your interest in us!
For question 1, during sc2 experiments on both malib and pymarl, we used training data (which is not greedy) instead of eval data (greedy) for statistics, but kept their randomness consistent during exploration. That is, we compared "battle won mean" instead of "test battle won mean". So, if you do a greedy evaluation, malib and pymarl should be on the same scale as well. Sorry for the confusion.
For question 2, we're still merging code from different branches, so this will be published soon.
Thanks again for your attention.
-
This is the corresponding "battle won mean" in PyMARL. However, it reaches 80% win rate for 3s5z.
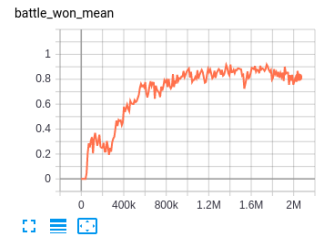
-
Why do you used training data (which is not greedy) instead of eval data (greedy) for statistics? In original smac paper, the authors mentioned that "with any exploratory behaviours disabled". If there are some papers using "training data", please share with me. Epsilon_finish is a super parameter that has a big impact on the results of "battle won mean". Therefore, what epsilon_finish do you use.

Thanks for your quick reply!
Sorry for so long time no response! We introduce the evaluation procedure under exploitation mode in our current version, but SMAC is still in refactoring because of API changes. The latest result will be published these days.