Fix cluster memory leak
We currently have a situation where kubernetes nodes will crash at least once a week due to running out of memory. They appear to eventually reboot, but this is a problem.
We should identify the cause of this memory leak and correct for it.
Area Used Cache Noncache
firmware/hardware 0 0 0
kernel image 12629 0 12629
kernel dynamic memory 24104020 1735176 22368844
userspace memory 1017764 318360 699404
free memory 171566560 171566560 0
root@magnesia:~#
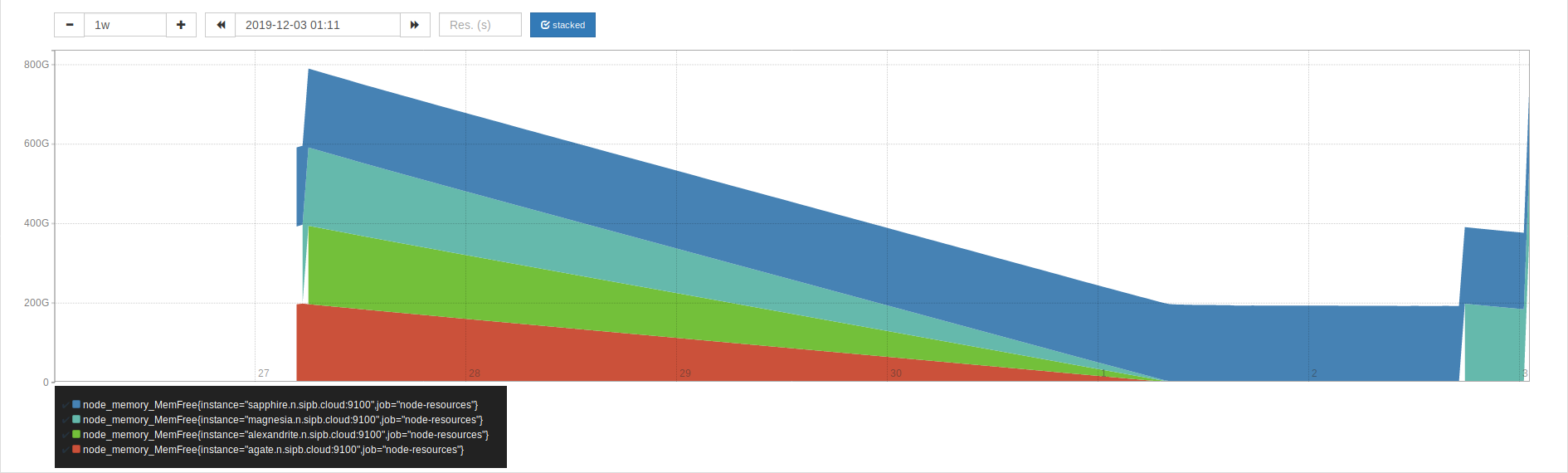
It's... something in the kernel? (The 22368844 is increasing.)
I'm hypothesizing that it's something relating to pull-monitor, which is constantly trying to launch containers. I've stopped pull-monitor on magnesia, and we'll see if there's any effect from that.
Yyyyeah, pull-monitor was it. On this graph, 0415 GMT was the approximate time when I turned off pull-monitor.
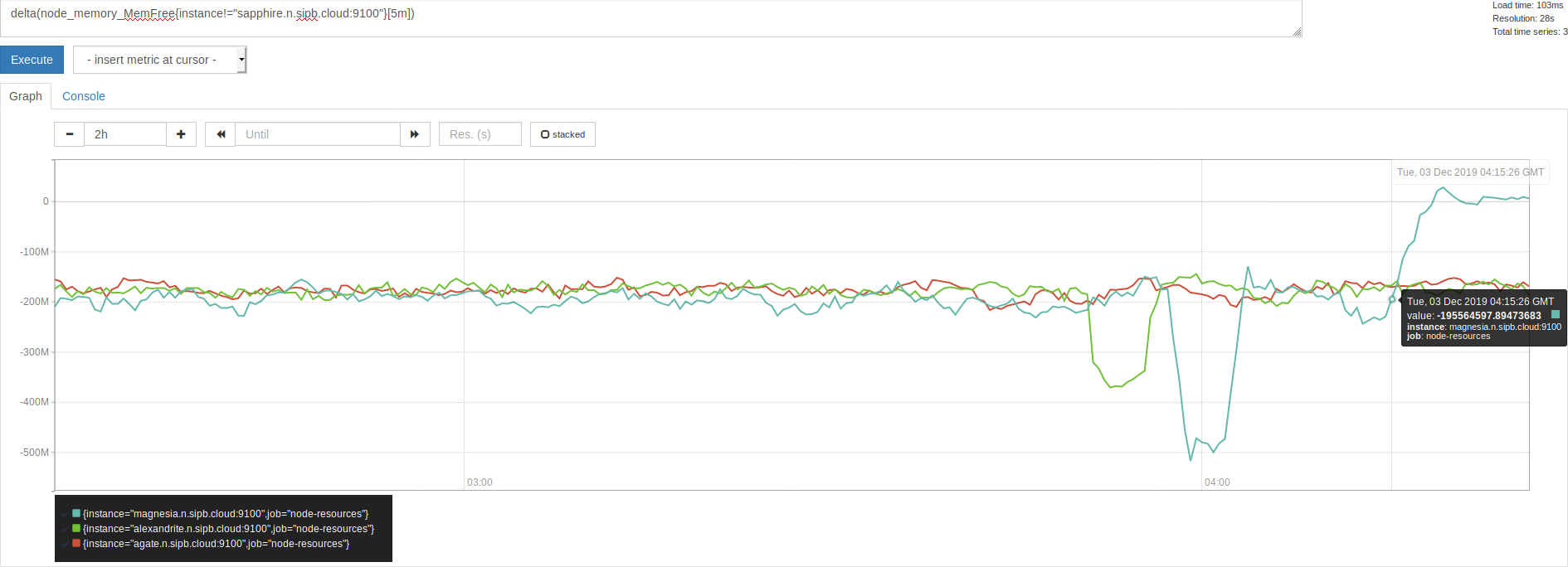
So that means we've got overhead of some sort leaking on every container creation, in some sort of kernel resource. Maybe something around cgroups or namespaces? I'm not really sure. But I don't think that pull-monitor touches kubernetes, so this is entirely a CRI-O or runc problem, then.
Restarting CRI-O did not help, so it's probably a legitimate logic flaw in something not getting deleted or torn down properly when it should have been.
This seems to be (at least partially) caused by a bug involving exit files. There's a fix at https://github.com/cri-o/cri-o/pull/2854, with more detailed description at https://github.com/containers/libpod/pull/3551/commits/ebacfbd091f709d7ca0b811a9fe1fee57c6f0ad3. I've confirmed that the number of files in /run/crio/exits continuously increases, and doing rm -f /run/crio/exits/* does free a sizeable chunk of memory (after running the cluster for a while).
Patching the fix in directly didn't seem to clear the exit files, however, so I'll try a full upgrade to 1.16.7 (see #490, upgrading CRI-O will also require upgrading Kubernetes).