siddhi
 siddhi copied to clipboard
siddhi copied to clipboard
Incremental aggregation with RDBMS store has a strange behavior in tables (may be a bug?)
Siddhi-tooling for docker v5.1.2
Hi, I've got an aggregation which calculate count of events per seconds, minutes..... and months. Sometimes when I send an event it creates a record in seconds AND minutes tables. Sometimes it creates records ONLY in seconds tables. My gut feeling is that it creates two records close to ending of minutes (on calculation edges, when 58,59 seconds).
The example: screenshot For the event which sent in the end of 40 minute two records were created. but for the next event which is sent almost right after the 1st one, only one record was created. I would expect consistent behavior. So whether always two records or only one record should be created.
This is important for me because I'm trying to calculate the count using tables and when it creates two records in seconds and in minutes, it increases the number and it's not trivial to write correct script. It seems to me that this behavior is not pretty consistent and nor reliable for calculation of a total count of events using such tables.
The code:
@App:name('test')
@App:statistics(enable='true', include='*.*')
-- SOURCES
define stream inp_flags (
customer string,
flag bool
);
-- AGGREGATIONS
@store(type = 'rdbms',
jdbc.url = "${POSTGRE_HOST}${POSTGRE_DB_DATASETS}",
username = "${POSTGRE_USER}",
password = "${POSTGRE_PASS}",
jdbc.driver.name = "org.postgresql.Driver")
@purge(enable='true', interval='1 second')
define aggregation flags_counts
from inp_flags
select
customer,
count() as cnt
group by customer
aggregate every seconds...months;
The problems which I try to solve: I need to calculate some aggregations (count, average, etc.) and produce a stream with latest values. This calculations should have a persistence, so after restart of the Siddhi application they should take the latest value and increment it. Also I want to have a storage which could be easy accessible, so I don't want to use some "internal" Siddhi persistence. If you know solution for this, please, share idea?
Siddhi incremental aggregations design is the following way,
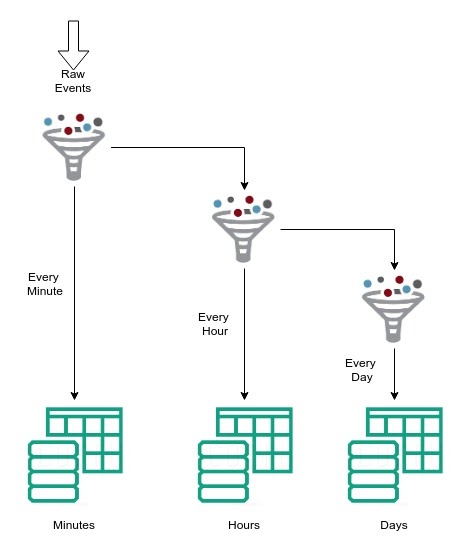
We will hold the events arrived in the last duration bucket, for instance, the last second, last-minute... in memory. The older calculations are moved to the table.
I need to calculate some aggregations (count, average, etc.) and produce a stream with latest values
What do you mean stream, is this aggregation never-ending? For instance, you want the count of customer events from the node start?
@niveathika Hi,
-
As to design of incremental aggregations. I understand that, but don't understand why two events with difference in several seconds were stored in DB differently. The 1st events has been stored in seconds and minutes. The 2nd event was stored only in seconds. With the time they were correctly purged and moved to respective tables.
-
As to the counts. Yes, I need to count from the very beginning, regardless if a node restarting. I found a solution with this incremental aggregations, using their tables, but because of the issue above it produces incorrect temporal results while values are duplicated in tables. Basically, I want to take records from each tables which are not included in another table. This should produce count for the whole existing data.
Why I need incremental aggregations? Because they are purging data, which allows store it in a compact way. And I don;t need to write it on my own, which is great.