shouldsee
shouldsee
Is there a hidden relation between these two modules? Seems like `torch.utils.tensorboard` was based on tensorboardX code as indicated by its [early commits](https://github.com/pytorch/pytorch/commit/98e312cf96f6a5e23933cd8794097063ee3cbc8c)
On a closer inspection, it seems pcolormesh() the one missbehaving and rasterplot() looks fine. 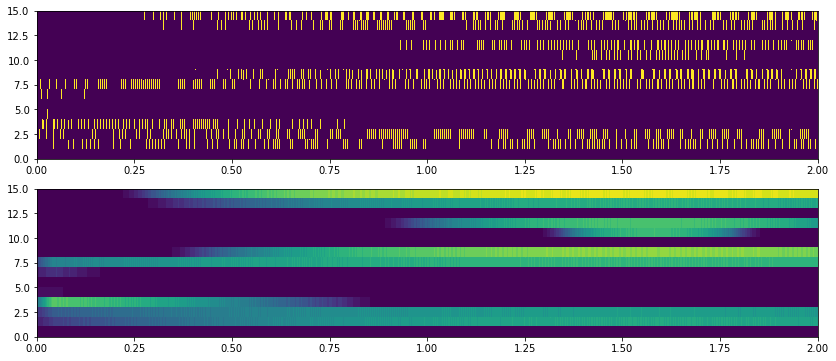 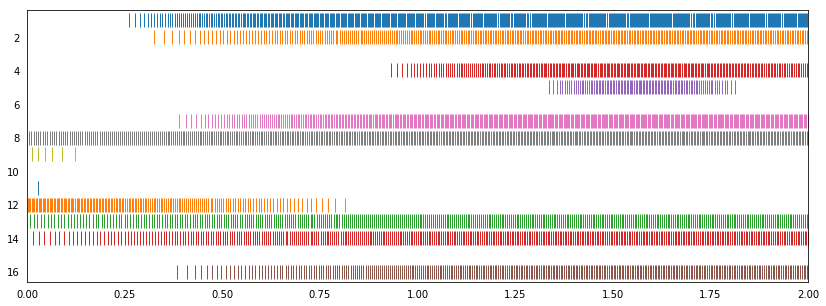 And I feel a time-average may be helpful for dense spike trains (plot 2)....
@jgosmann Thanks for the tip. I will try plot_spikes when have time.
Is there a way of passing y.scale through GET param at the moment?
is there any update of this?
自定义字典新增的行贴出来看看?
这个关键词被占用问题,是任何语言都要面临的问题,通常来讲有几种可能做法. 1. 在给定结构的情况,用左右括号语法进行引用生成更大的token,使得特殊字符失效 2. 选择另一个token为正交的关键词,避免冲突. 方案1就是一个Tokenization问题,所以原则上来讲jieba就是为了解决此类问题而设计的,如果待切分的Token序列中存在特殊字符,jieba应该根据词语频率来进行切分.如果是错误拼写的词语,应有机制发现错误. 实际运用中,方案2会更迅速一些,但通常涉及到一整套的数据格式的改动.
可以,PR没人test merge啊.. > 。。。。为啥要改分切符号。。。不可以反向切割吗?从右边切割两刀这不就避开了word里的空格了吗?如下: > > ``` > word, _, tag = line.rsplit(' ', 2) > ```
个人经验,win上面打包的话用pyinstaller比较简单一些,py2exe和cxfreeze我都没太学会.
`Can not execute `setup.py` since setuptools is not available in the build environment.` 检查一下`pip show setuptools`吧,可能要先`pip install setuptools`