scylla-operator
 scylla-operator copied to clipboard
scylla-operator copied to clipboard
Operator deletes Scylla pod scheduled for removal before nodetool does it making Scylla cluster think there is dead node
Describe the bug Running QA functional tests we get flaky (90% fail / 10% pass) failure that in test with decommission of a Scylla node/pod the new one cannot be added to a cluster with the following error (recurring):
Starting the JMX server2022-05-18 20:43:06,701 INFO success: rsyslog entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2022-05-18 20:43:06,702 INFO success: scylla entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2022-05-18 20:43:06,702 INFO success: scylla-housekeeping entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2022-05-18 20:43:06,702 INFO success: scylla-jmx entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2022-05-18 20:43:06,702 INFO success: scylla-node-exporter entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2022-05-18 20:43:06,702 INFO success: sshd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
JMX is enabled to receive remote connections on port: 7199
E0518 20:43:21.051159 1 sidecar/probes.go:109] "readyz probe: can't get scylla native transport" err="giving up after 1 attempts: agent [HTTP 404] Not found" Service="scylla/sct-cluster-dc-1-kind-2" Node="10.96.52.154"
E0518 20:43:31.050803 1 sidecar/probes.go:109] "readyz probe: can't get scylla native transport" err="giving up after 1 attempts: agent [HTTP 404] Not found" Service="scylla/sct-cluster-dc-1-kind-2" Node="10.96.52.154"
E0518 20:43:41.050832 1 sidecar/probes.go:109] "readyz probe: can't get scylla native transport" err="giving up after 1 attempts: agent [HTTP 404] Not found" Service="scylla/sct-cluster-dc-1-kind-2" Node="10.96.52.154"
E0518 20:43:51.050539 1 sidecar/probes.go:109] "readyz probe: can't get scylla native transport" err="giving up after 1 attempts: agent [HTTP 404] Not found" Service="scylla/sct-cluster-dc-1-kind-2" Node="10.96.52.154"
2022-05-18 20:43:58,243 INFO exited: scylla (exit status 1; not expected)
2022-05-18 20:43:59,245 INFO spawned: 'scylla' with pid 111
List of services after attempt to add new node:
ubuntu@ip-10-0-1-253:~/sct-results/latest$ kubectl get svc -n scylla
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sct-cluster-client ClusterIP None <none> 9180/TCP,5090/TCP 13h
sct-cluster-dc-1-kind-0 ClusterIP 10.96.39.7 <none> 7000/TCP,7001/TCP,7199/TCP,9042/TCP,9142/TCP,19042/TCP,19142/TCP,10001/TCP,9160/TCP 13h
sct-cluster-dc-1-kind-1 ClusterIP 10.96.154.187 <none> 7000/TCP,7001/TCP,7199/TCP,9042/TCP,9142/TCP,19042/TCP,19142/TCP,10001/TCP,9160/TCP 13h
sct-cluster-dc-1-kind-2 ClusterIP 10.96.52.154 <none> 7000/TCP,7001/TCP,7199/TCP,9042/TCP,9142/TCP,19042/TCP,19142/TCP,10001/TCP,9160/TCP 13h
nodetool status output at that moment is following:
root@sct-cluster-dc-1-kind-0:/# nodetool status
Datacenter: dc-1
================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
DL 10.96.114.64 1.08 MB 256 ? 1a6ab28c-91c8-45df-92c5-d7e9960e6189 kind
UN 10.96.39.7 1.12 MB 256 ? 820874fc-e03e-44b2-b556-ee6534a9295b kind
UN 10.96.154.187 1.04 MB 256 ? dc974567-581c-4404-b612-137847e78920 kind
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
So, as we can see, nodetool didn't remove the previous decommissioned Scylla node. And, according to the Scylla docs, we know that we should add new nodes to a Scylla cluster only when there are no dead nodes. So, this is the reason new pod cannot join the cluster.
Such problem started being observed using Scylla 4.5.x and newer.
To Reproduce Steps to reproduce the behavior:
- Deploy operator v1.7.2 (actually 1.7.0 and 1.7.1 must be affected too)
- Deploy Scylla cluster with 3 members
- Drain a Scylla pod which is last member of a Scylla cluster
- Reduce number of pods in the scyllacluster CR instance
- See error that the pod is removed having it be tracked in nodetool.
Expected behavior Scylla pod gets removed only when nodetool doesn't track it.
Logs kubernetes-ec2f57f5.tar.gz
Environment:
- Platform: KinD
- Kubernetes version: v1.21.1
- Scylla version: 4.6.3 , 5.0.rc3 , 2022.1.rc3
- Scylla-operator version: 1.7.2
Additional context There is issue in the qa automation tool with some useful info: https://github.com/scylladb/scylla-cluster-tests/issues/4404
@vponomaryov can you try with master branch? there was https://github.com/scylladb/scylla-operator/pull/967
@vponomaryov can you try with master branch? there was #967
Ok, will do.
@vponomaryov can you try with master branch? there was #967
Ok, will do.
The problem remains.
Ran it several more times and can say that probability to hit the race decreased. Now there are more successful runs than failed.
Discussed offline with @vponomaryov. Leaving a comment just for the record.
The failing functional test test_drain_terminate_decommission_add_node_kubernetes doesn't logically align with the behaviour expected from Scylla Operator. After one of the k8s nodes has been drained, the operator wouldn't be able to decommission the Scylla node as it wouldn't be available any longer. The Pod corresponding to the missing node would enter a "Pending" state. Since we're using local disks for Scylla nodes, and, hence, also setting up NodeAffinities on their corresponding PVs, such Pod couldn't be scheduled on a different node added to the cluster later on.
Why hasn't this been observed before Scylla 4.5.x? Our guess is that graceful termination takes longer now, and so the test started hitting a race condition between the k8s node drain and Scylla node decommission. @zimnx thanks for your help!
In the follow-up discussion, after making sure that uncordon operation gets run, @zimnx assumed that such problem may be if we lose storage.
So, I tested the situation with PVs on the KinD tool which was used, where the problem appeared.
I created separate storage class with the Retain reclaimPolicy and specified it in the scyllacluster CR.
But after pod recreation I saw just appearance of the PV duplicates like this:
$ kubectl get pv | grep " scylla "
pvc-56b64058-6c66-4b25-97c7-7053239695db 5Gi RWO Retain Released scylla/data-sct-cluster-dc-1-kind-2 scylla 31m
pvc-73914f28-7c44-4a0c-87e5-bf744ce238a6 5Gi RWO Retain Bound scylla/data-sct-cluster-dc-1-kind-1 scylla 35m
pvc-81e130f2-8b92-4f07-a0ac-db48f36a0a98 5Gi RWO Retain Released scylla/data-sct-cluster-dc-1-kind-0 scylla 38m
pvc-c7547de6-19cb-40ec-aa34-040cc18b37a2 5Gi RWO Retain Bound scylla/data-sct-cluster-dc-1-kind-0 scylla 21m
pvc-ff4a8d73-6fc6-46df-ae4e-c071ad0dac41 5Gi RWO Retain Bound scylla/data-sct-cluster-dc-1-kind-2 scylla 11m
So, it means that the storage gets lost for sure from the Scylla point of view and the reason for it is the dynamic storage provisioner used by default in the KinD tool.
So, the next step I am going to try out is the usage of the static provisioner in KinD the same way as it is done in EKS and GKE. Will see what changes.
Ran functional tests the same way as before only changing the storage provisioner to be the static one like in the EKS and GKE backends. The bug got reproduced in 6 cases from 6 (100%). Proofs and logs are here:
- https://jenkins.scylladb.com/view/staging/job/scylla-staging/job/valerii/job/vp-functional-k8s-local-kind-aws/151/console
- https://jenkins.scylladb.com/view/staging/job/scylla-staging/job/valerii/job/vp-functional-k8s-local-kind-gce/99/console
I went ahead and dug deeper into the issue. Below is the brief description of the efforts.
Let's start with trying to better understand what test_drain_terminate_decommission_add_node_kubernetes does. The scenario needed to reproduce this test goes as follows:
1. Deploy the Scylla Operator
2. Deploy a single rack, 3 member Scylla Cluster
3. Drain the node that the last Scylla node (member) was deployed on with `kubectl drain`
4. Uncordon that node with `kubectl uncordon`
5. Scale the cluster to 2 members (decommission the last Scylla node)
6. Scale the cluster back up to 3 members
Going through kubectl drain proves that it only deletes/evicts the pods deployed on the chosen node.
kubectl uncordon can be omitted, as it only patches the node with spec.unschedulable = false, which in this case is redundant.
Knowing that the scenario can be simplified:
1. Deploy the Scylla Operator
2. Deploy a single rack, 3 member Scylla Cluster
3. Delete the Pod of the last Scylla node (member) and wait for the deletion to complete
4. Scale the cluster to 2 nodes (decommission the last Scylla node)
5. Scale the cluster back up to 3 nodes
So I went ahead and reproduced the above with an e2e test in our test suite while also extending our framework with collecting Scylla logs throughout the entire run (instead of just before deleting the namespace) and gathering packet captures from tcpdump as well.
Below are the manifests, logs and packet captures from an example run on an exemplary Kind cluster, defined as follows:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
EphemeralContainers: true
nodes:
- role: control-plane
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "minimal-k8s-nodepool=scylla-pool"
register-with-taints: "role=scylla-clusters:NoSchedule"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "minimal-k8s-nodepool=scylla-pool"
register-with-taints: "role=scylla-clusters:NoSchedule"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "minimal-k8s-nodepool=scylla-pool"
register-with-taints: "role=scylla-clusters:NoSchedule"
- role: worker
e2e-test-scyllacluster-7w22b-5xnct.tar.gz
Using this example let's now analyze what happens. I'll focus on Pods basic-xc8h4-us-east-1-us-east-1a-0, hereafter referred to as node 0 and basic-xc8h4-us-east-1-us-east-1a-2, hereafter referred to as node 2, because the case for the other node is analogous.
The static ClusterIPs used as rpc addresses of these Scylla nodes are:
node 0: 10.96.95.63
...
node 2: 10.96.165.158 -> 10.96.103.48
Node 2 has multiple addresses because it gets a new one after its decommissioned and recreated.
The PodIPs are:
node 0: 10.244.3.6
...
node 2: 10.244.4.6 -> 10.244.4.7 -> 10.244.4.10
Again, node 2 has multiple addresses because it gets a new PodIP assigned after it's been deleted and then again after its been scaled down and up again.
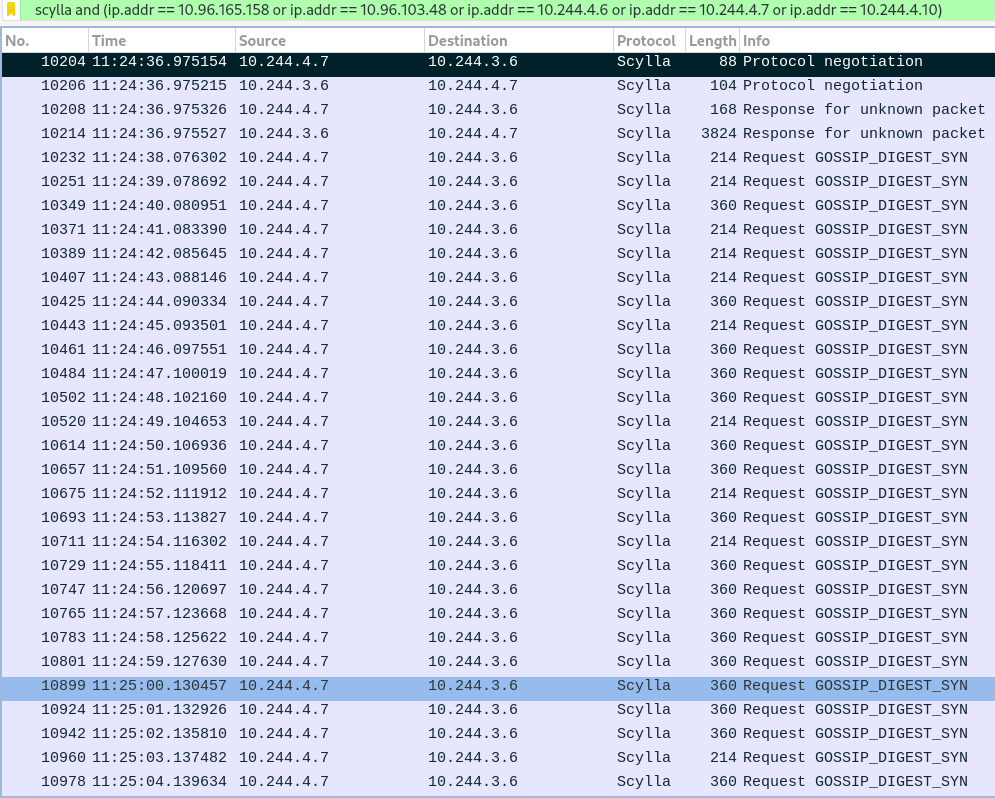
With the above we can look at the corresponding packet captures with Wireshark. To only see the communication between node 0 and node 2, I'm applying the following filters:
node 0: scylla and (ip.addr == 10.96.165.158 or ip.addr == 10.96.103.48 or ip.addr == 10.244.4.6 or ip.addr == 10.244.4.7 or ip.addr == 10.244.4.10)
...
node 2: scylla and (ip.addr == 10.96.95.63 or ip.addr == 10.244.3.6)
The issue essentially comes down to this: after node 2 is deleted, the other 2 nodes mark it as DN. After it's recreated it stays that way and, correspondingly, it sees the other two nodes as DN as well. So at this moment we have a split-brain cluster.
Node 0 and 1's status:
0: UN
1: UN
2: DN
Node 2 status:
0: DN
1: DN
2: UN
Looking at Scylla logs and packet captures, we can observe that after node 2 is recreated, it starts sending GOSSIP_DIGEST_SYN packets to node 0.
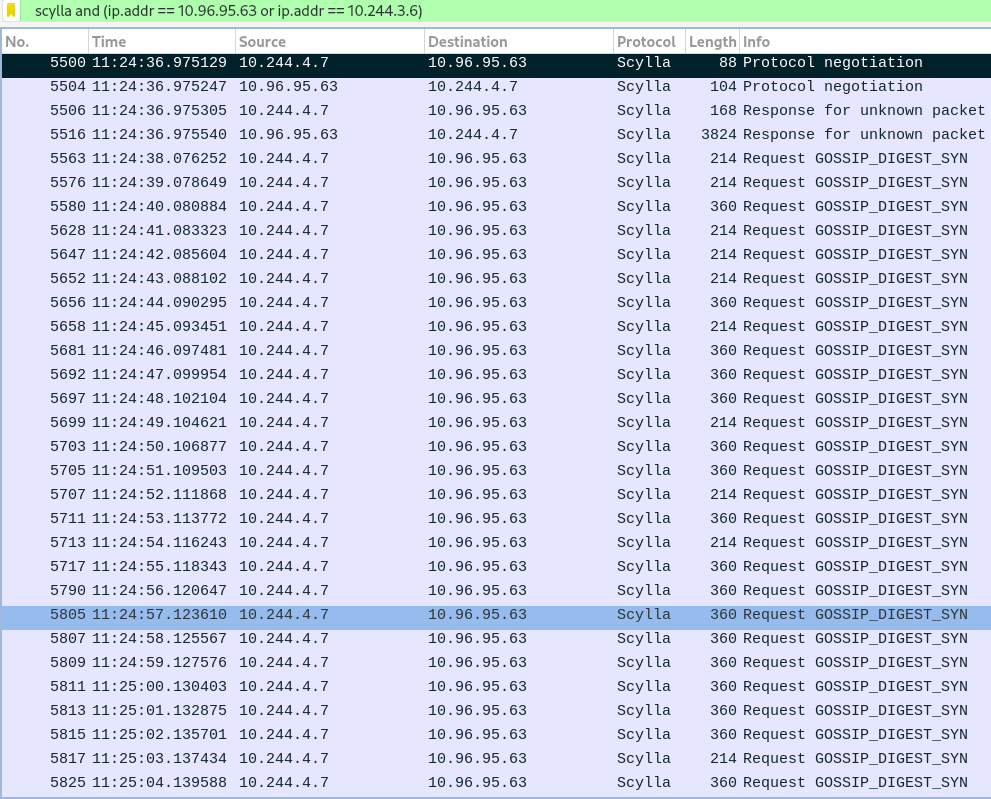
To which node 0 never replies, even though its logs claim so
DEBUG 2022-08-04 11:24:38,076 [shard 0] gossip - Calling do_send_ack_msg to node 10.96.165.158:0 ...
Node 0's logs also repeatedly claim it's been sending GOSSIP_DIGEST_SYN packets to node 2
TRACE 2022-08-04 11:24:38,649 [shard 0] gossip - do_gossip_to_unreachable_member: live_endpoint nr=1 unreachable_endpoints nr=1
TRACE 2022-08-04 11:24:38,649 [shard 0] gossip - Sending a GossipDigestSyn to 10.96.165.158:0 ...
...
TRACE 2022-08-04 11:24:39,651 [shard 0] gossip - do_gossip_to_unreachable_member: live_endpoint nr=1 unreachable_endpoints nr=1
TRACE 2022-08-04 11:24:39,651 [shard 0] gossip - Sending a GossipDigestSyn to 10.96.165.158:0 ...
...
TRACE 2022-08-04 11:24:39,651 [shard 0] gossip - do_gossip_to_unreachable_member: live_endpoint nr=1 unreachable_endpoints nr=1
TRACE 2022-08-04 11:24:39,651 [shard 0] gossip - Sending a GossipDigestSyn to 10.96.165.158:0 ...
...
yet it is never seen in packet capture.
The current hypothesis is that after the rpc connection from node 0 to node 2 has been dropped, it was never reestablished - which doesn't mean it wouldn't later on, it just doesn't happen in the 30 seconds that the decommissioning allows.
And here is the interesting part: the node ops, used to broadcast the information about decommissioning of node 2 propagate both ways without any issues. It can be confirmed by looking at node 2's logs:
INFO 2022-08-04 11:25:17,453 [shard 0] storage_service - DECOMMISSIONING: starts
INFO 2022-08-04 11:25:17,453 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Started decommission operation, removing node=10.
96.165.158, sync_nodes=[10.96.165.158, 10.96.95.63, 10.96.159.117], ignore_nodes=[]
DEBUG 2022-08-04 11:25:17,454 [shard 0] storage_service - node_ops_cmd_handler cmd=11, ops_uuid=a515e718-feb6-4439-8211-940373dcc15c
INFO 2022-08-04 11:25:17,454 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Added node=10.96.165.158 as leaving node, coordinator=10.96.165.158
...
DEBUG 2022-08-04 11:25:17,516 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Got prepare response from node=10.96.165.158
DEBUG 2022-08-04 11:25:17,517 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Got prepare response from node=10.96.159.117
DEBUG 2022-08-04 11:25:17,587 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Got prepare response from node=10.96.95.63
INFO 2022-08-04 11:25:17,587 [shard 0] storage_service - decommission[a515e718-feb6-4439-8211-940373dcc15c]: Started heartbeat_updater
How? Node ops and gossip use separate rpc connections: see scylla/message/messaging_service.cc#L452.
This allows node 2 to be decommissioned successfully, which leads to it staying in the other nodes' system.peers tables as DL. This, in turn, prohibits the newly created (after scaling back up) node to join the cluster.
I was able to reproduce this issue on kind with two different setups: separate k8s node for each Scylla node and one k8s node shared between all Scylla nodes. I wasn't able to reproduce it on any other K8s distribution than Kind though. I've tried minikube and gke, around 10 runs each, to no avail. With Kind, the reproduction rate was roughly 90%. At the moment I'm not able to determine why this only happens on Kind.
I believe that the missing gossip packets going from node 0 to node 2 after node 2's deletion are essential for reproducing this issue. We could try blocking them explicitly with some sort of packet filtering to test whether it's a Scylla bug outside of K8s.
fyi @vponomaryov @roydahan @tnozicka @zimnx @slivne
@slivne you wanted a reproducer, here it is: https://gist.github.com/fruch/b3623f68bf8dba65c44133ba1288f418
It started happening, once I've changed node3 address... I think this can explain the network not connecting, since the other nodes aren't aware there's a new address to connect
@rzetelskik IIUC and it also came up in my discussion with @fruch after reviewing the test, after you drain/delete a pod, the new pod that is added instead of it, changes the IP (I don’t know what happens to the data).
If this is the case, scylla needs to be aware of that by either using “replace_node” or by using “remove node”. What happens afterwards doesn’t really matter here (not the decommissioning and not adding node). Now, I don’t know understand what happens to the data, but I guess/hope there is something that takes care of it, otherwise it’s a data loss for sure.
I think this can explain the network not connecting, since the other nodes aren't aware there's a new address to connect
It's not what happens. Scylla node comes back up with the same rpc-address and broadcast-rpc-address. Node ops packets are reaching the right node, and they are sent to the exact same ip address and port as the gossip packets - it's just a separate connection. Yet we can't see any gossip traffic flowing from node 0 to node 2.
the new pod that is added instead of it, changes the IP (I don’t know what happens to the data)
Only the PodIP changes. The ClusterIP, which we use for rpc-address and broadcast-rpc-address, stays the same. The data isn't getting lost either.
ClusterIP is the IP of a service serving as a load balancer. PodIP is the endpoint behind it.
What happens afterwards doesn’t really matter here (not the decommissioning and not adding node).
Agreed. The following steps are sufficient to observe the issue with lack of gossip exchange on Kind:
1. Deploy the Scylla Operator
2. Deploy a single rack, 3 member Scylla Cluster
3. Delete the Pod of the last Scylla node (member) and wait for the deletion to complete
After that you'll be able to observe node 2 and the other nodes seeing each other as DN for quite a while - from what I've seen up to a couple of minutes. Bare in mind I was only able to observe it on Kind.
The decommissioning step only highlights this issue because node 2 is removed after 30s, which means its stays as DL in other nodes' peers tables.
I confirm that when I add waiter for UN states for all nodes after drain operation and before the decommission one everything succeeds.
And that waiter takes about 2 minutes.
So, I would say that we have 2 following Scylla bugs here which are caused by the specific (slow?) behavior of the "KinD" (K8S in Docker) tool:
- The one highlighted by @rzetelskik where we have discrepancy between Scylla's statements in logs and real network behavior.
- Decommission operation must not succeed having other approving nodes as "DN".
And yes, @fruch 's scenario is not the same. If it was the same then simple waiter for UN state would not change anything. Also, the knowledge that it happens not in 100% cases of test runs on KinD proves it one more time, because pod IP, which is not involved in Scylla configuration, changes almost always.
@rzetelskik @vponomaryov @slivne, here's a dtest that reproduces it with blocking gossip traffic TO the node being decommissioned
https://gist.github.com/fruch/7487febf59afd60a7972a08e4ef44daf
the decomission starts on node 127.0.77.3 when it's doesn't see the other nodes as UP
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
DN 127.0.77.1 ? 256 ? f5a7d0fa-4349-47a6-9980-bfd69628d816 rack1
DN 127.0.77.2 ? 256 ? 1c4bd294-7304-4e52-b6d2-38aecd733d00 rack1
UN 127.0.77.3 247.74 KB 256 ? 1f33af13-e8ba-48f0-a942-79feed67cdb4 rack1
next node being added fails with:
ERROR 2022-08-07 18:40:16,253 [shard 0] init - Startup failed: exceptions::unavailable_exception (Cannot achieve consistency level for cl ALL. Requires 3, alive 2)
I think that the wait that was added, is what let gossip to notice the changes (ring_delay?). @asias can shed more light here.
Regarding the decommission that shouldn't succeed, I agree, but I think with RBNO it won't succeed. @asias can also advise here.
@rzetelskik @vponomaryov @slivne, here's a dtest that reproduces it with blocking gossip traffic TO the node being > decommissioned
https://gist.github.com/fruch/7487febf59afd60a7972a08e4ef44daf
@fruch does the decommissioning actually succeed? Because that iptables rule will also drop packets from other rpc clients, not just the one used for gossip. That includes the node ops commands.
I think that the wait that was added, is what let gossip to notice the changes (ring_delay?).
Ring delay is taken into account either way (https://github.com/scylladb/scylladb/blob/ba42852b0e1d2bec677e60a863c505a637884e04/service/storage_service.cc#L2974) when decommissioning, so it's not just that.
I think that the wait that was added, is what let gossip to notice the changes (ring_delay?).
Ring delay is taken into account either way (https://github.com/scylladb/scylladb/blob/ba42852b0e1d2bec677e60a863c505a637884e04/service/storage_service.cc#L2974) when decommissioning, so it's not just that.
When this problem appears we see this:
WARN 2022-06-10 09:53:31,712 [shard 0] seastar - Exceptional future ignored: seastar::sleep_aborted (Sleep is aborted), backtrace:
0x4161c3e
0x4162130
0x4162438
0x3d9294b
0x1bf6a79
0x3dd0cc4
0x3dd20b7
0x3dd12fc
0x3d7aaae
0x3d79e26
0xf41135
/opt/scylladb/libreloc/libc.so.6+0x27b74
0xf3e2ed
Scylla version for the backtrace: 4.6.3-0.20220414.8bf149fdd with build-id 8d16d8972498cc769071ff25309b009eb77bf77a
@fruch to further specify my comment above - I don't think it's enough to introduce such iptables rule to reproduce this exact issue. I don't have enough expertise to say that for sure but I doubt the decommissioning will succeed if you drop all packets on this address:port, since the node ops command will get dropped as well. I believe that to reproduce this issue, in which the gossip commands are not going through while the node ops commands do, you'd have to filter packets based on the message type, which won't be as easy as adding an iptables rule. So, again, are you sure that the decommissioning actually succeeds in the above reproducer?
@fruch to further specify my comment above - I don't think it's enough to introduce such iptables rule to reproduce this exact issue. I don't have enough expertise to say that for sure but I doubt the decommissioning will succeed if you drop all packets on this address:port, since the node ops command will get dropped as well. I believe that to reproduce this issue, in which the gossip commands are not going through while the node ops commands do, you'd have to filter packets based on the message type, which won't be as easy as adding an iptables rule. So, again, are you sure that the decommissioning actually succeeds in the above reproducer?
The decommission did succeed, and I've blocked the communication only in one direction, to the node being decommissioned. i.e. that node can send gossip requests to other, but other can't send gossip request to it.
I don't understand what do you mean by nodes ops commands ? you are talking about repair-based-operations ?
anyhow what I've did, did reproduced the issue (same side effect when adding the 4th node), and the decommission was successful.
I don't understand what do you mean by nodes ops commands ? you are talking about repair-based-operations ?
see https://github.com/scylladb/scylladb/blob/afa7960926f15566029d5e0ed20a00a15da70b28/idl/partition_checksum.idl.hh#L74
The decommission did succeed, and I've blocked the communication only in one direction, to the node being decommissioned. i.e. that node can send gossip requests to other, but other can't send gossip request to it.
When you decommission a node, it sends decommission_prepare message to its peers. You won't get any responses with this iptables rule and I believe you should see this error https://github.com/scylladb/scylladb/blob/afa7960926f15566029d5e0ed20a00a15da70b28/service/storage_service.cc#L1950
anyhow what I've did, did reproduced the issue (same side effect when adding the 4th node)
It doesn't necessarily mean that it reproduced the issue. You'll see that exact same message if you stop one of the nodes and add a new one.
Anyway I think we can all agree this isn't an Operator bug but an issue in Scylla, so I'll open an issue with core.
@rzetelskik I was blocking only packet targeting the gossip port on the node being decommissioned, meaning all other communication from that node to the other node is working. so nodes ops commands you mentioned are being sent, while the other nodes are not getting gossip update, since they aren't connected to the node being decommissioned.
this also explains why I don't get into the error you refer, since that node see and communicate with the other nodes (they can't communicate with it)
So I think it matches your findings.
I was blocking only packet targeting the gossip port on the node being decommissioned, meaning all other communication from that node to the other node is working. so nodes ops commands you mentioned are being sent
Afaik all rpc connections are using the same ip address and port. It's just different clients. (https://github.com/scylladb/scylladb/blob/785ea869fb3c440bf791c6940ed29339cc98ed38/message/messaging_service.cc#L452) Specifically node_ops and gossip messages use different ones. There isn't enough granularity in iptables rules to make that distinction.
I was blocking only packet targeting the gossip port on the node being decommissioned, meaning all other communication from that node to the other node is working. so nodes ops commands you mentioned are being sent
Afaik all rpc clients are using the same ip address and port. It's just different clients. (https://github.com/scylladb/scylladb/blob/785ea869fb3c440bf791c6940ed29339cc98ed38/message/messaging_service.cc#L452) Specifically node_ops and gossip messages use different ones. There isn't enough granularity in iptables rules to make that distinction.
again you are missing the direction I'm blocking, I'm block only in one direction.
I'm blocking node1, node2 --> 7000 node3 while node3 --> 7000 node1, node2 is open.
so the node_ops command can go from node3 to node1 and node2, while node1 and node2 gossip can't communicate with node3, hence left with the information it is still in the cluster
I'm blocking node1, node2 --> 7000 node3 ... so the node_ops command can go from node3 to node1 and node2,
Yes, node_ops can go from node3 to node1 and node2. But node3 won't receive any responses, since as you just said, you're blocking all traffic going from node1 and node2 to node3 at port 7000. Which is used by both gossip and node_ops.
I'm blocking node1, node2 --> 7000 node3 ... so the node_ops command can go from node3 to node1 and node2,
Yes, node_ops can go from node3 to node1 and node2. But node3 won't receive any responses, since as you just said, you're blocking all traffic going from node1 and node2 to node3 at port 7000. Which is used by both gossip and node_ops.
node3 would receive the answers on the nodes_ops, since the target port of that communication isn't targeting port 7000
node3 -----> 7000 node1 response are on the same connection like: node1 -----> (random_port) node3
so that explains why the decommission succeed, cause from node3 POV everything is o.k.
@fruch you're right. And that also leads me to believe my initial hypothesis ("[...] the node ops, used to broadcast the information about decommissioning of node 2 propagate both ways without any issues") was nonsense. It's just that node_ops responses are received on the same connection, while gossip exchange requires connections going both ways. That'd also mean your reproducer is viable.
I ran the test again and dumped conntrack entries every 10s. After it's been removed, node2 started again at 11:38:49. Yet the stale conntrack entry with the old PodIP (10.244.3.3) stays for another 2 minutes. Only then it is removed and a new entry with new PodIP (10.244.3.4) is created.
2022-08-17T11:38:51.074749061Z 43: Wed Aug 17 11:38:51 UTC 2022
2022-08-17T11:38:51.079102330Z tcp 6 102 SYN_SENT src=10.244.4.3 dst=10.96.27.34 sport=51626 dport=7000 [UNREPLIED] src=10.244.3.3 dst=10.244.4.3 sport=7000 dport=51626 mark=0 use=1
...
2022-08-17T11:40:31.163825549Z 53: Wed Aug 17 11:40:31 UTC 2022
2022-08-17T11:40:31.169809634Z tcp 6 2 SYN_SENT src=10.244.4.3 dst=10.96.27.34 sport=51626 dport=7000 [UNREPLIED] src=10.244.3.3 dst=10.244.4.3 sport=7000 dport=51626 mark=0 use=1
...
2022-08-17T11:40:41.171517832Z 54: Wed Aug 17 11:40:41 UTC 2022
...
2022-08-17T11:40:51.177311045Z 55: Wed Aug 17 11:40:51 UTC 2022
2022-08-17T11:40:51.181337883Z tcp 6 86398 ESTABLISHED src=10.244.4.3 dst=10.96.27.34 sport=50234 dport=7000 src=10.244.3.4 dst=10.244.4.3 sport=7000 dport=50234 [ASSURED] mark=0 use=1
So it looks like after all iptables/conntrack might be behind the issues we've hit in kind.
The issue seems very similar to https://github.com/scylladb/scylla-operator/issues/971. The difference is the conntrack entry is removed after roughly 2 minutes, and the root cause has to be something else, since it's been fixed in linux-5.14, and kind nodes I've been running the tests against run linux-5.18. Maybe it's just different configuration, especially given that it takes 2 minutes to replace the entries, which is the default for most of conntrack's options.
@rzetelskik question is, if scylla-core going to be handling this, or operator would need to wait for cluster fully up (i.e. all nodes see each other) before issuing a decommission (as what the guidelines says)
https://github.com/scylladb/scylladb/issues/11302 has now been closed as completed in https://github.com/scylladb/scylladb/commit/58c65954b8cedc498678e97027885aea1cad24f3