a Schema Markup Validator: adopting SDTT to add validation to Schema.org site
In 2021 we should improve the schema.org by incorporating validation tooling. There are two broad categories here: syntactic parsing and shape-based checks.
Nearby:
- Google's blog post on future of SDTT
- my mail thread "a Schema Markup Validator: adopting SDTT for validator.schema.org"
- background document with a few more details
/cc @tmarshbing @scor @tilid @rvguha @nicolastorzec
See also https://developers.google.com/search/blog/2020/12/structured-data-testing-tool-update from Google on plans for SDTT (essentially to rework it as a tool for the schema.org community).
I have put a short document together at https://docs.google.com/document/d/1q8z_rRJepiz4Os_KcEs3NaCVEm3US5l-qYL14JmE0To/edit# that talks a bit more about the two kinds of validator and how we might proceed.
Email thread: https://lists.w3.org/Archives/Public/public-schemaorg/2020Dec/0002.html
Nearby discussion: https://searchengineland.com/google-to-move-the-structured-data-testing-tool-to-schema-org-344815
I have messed with the subject line after realizing on Twitter I had given the impression that "validator.schema.org" was already working. We are setting a direction here not announcing a finished thing.
@danbri This is very good news, as we (I and my colleagues from STI Innsbruck) have been working towards this topic for a long time. This is basically a vendor-independent implementation of SDTT with more advanced reporting features [1].
We have also a validator based on SHACL (a subset of SHACL) [2]. We have had very good experience with our approach in different sectors like tourism and public service (they are used as patterns for creating sdo annotations). See here for some shapes for tourism domain https://ds.sti2.org
Looking forward to a cooperation on this topic. I have dropped a similar comment on the GDoc document, the source code of the SDTT implementation will be open-sourced this week, I'll update it here again.
[1] https://sdocheck.semantify.it. [2] https://semantify.it/validator/
@sumutcan - that sounds like a useful tool to be opensourcing - let's investigate interop testing in 2021!
FWIW; resources for the background document:
re: book.validatingrdf.com, ShEx and SHACL:
Chapter 4 Shape Expressions (ShEx) http://book.validatingrdf.com/bookHtml010.html Chapter 5 SHACL http://book.validatingrdf.com/bookHtml011.html Chapter 7 Comparing ShEx and SHACL http://book.validatingrdf.com/bookHtml013.html
And then, practically, there are already many JSONschema validation tools (JS implementations that work in Node and in browsers): can we use those with SHACL?
https://github.com/mulesoft-labs/json-ld-schema ::
JSON Schema/SHACL based validation of JSON-LD documents
Use case:
- I want to add (e.g. bibliographic, document-level) metadata to a Jupyter notebook with a widget at the top that lets me append a new Person inline form in order to add another author and affiliated Organization; and it needs to let me edit the produced JSON-LD, which needs to be validated with appropriate feedback in the form.
If google/schemarama (mentioned in the linked gdoc) does not support dynamic forms-based validations, what would it take to support such an essential data data quality use case?
In regards to interactive data validation as a primary use case, What are these for:
- https://github.com/google/schema-dts
- https://github.com/google/react-schemaorg
Minimally, what's the form widget and client-side validators story for a ScholarlyArticle Thing with Person authors an Organization funders?
@westurner the library that should be used in Javascript is https://github.com/zazuko/rdf-validate-shacl/, if something is missing, it should be extended there.
It is an independent fork of the reference implementation in Javascript but on top of RDFJS. The modern RDF stack/standard for Javascript.
(Full disclosure: My colleagues wrote it)
Thank you for your services. Currently, I am awaiting the arrival of an important Google verification to ascend the self service worker to independently verify and attest the "multi user-agent" flowing editions which will adopt our new found glorious application servants within adoption.
You all will soon be very appropriate to instantiate. Something tells me the industry will be in demand to acquire this new sense "nuisance"(get it lol?) of fashion to implore our friends.
The salutation should greet: whom which have applied passion"allocating outliers'"correcting mistakes (even noticing corrections after the fact SPACE BAR HIJACKED)the punctuation being online with autocorrect*
hang in there ladies and gentlemen
respectfully concerned with the internet___
Christopher M. SpradlingScheme check Front0-end-Front https://sdocheck.semantify.it/?url=https://independent-consulting.business.site/?m=true-verified
On Tue, Dec 15, 2020 at 10:10 AM Dan Brickley [email protected] wrote:
I have messed with the subject line after realizing on Twitter I had given the impression that "validator.schema.org" was already working. We are setting a direction here not announcing a finished thing.
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-745393144, or unsubscribe https://github.com/notifications/unsubscribe-auth/ADFVNUQYFTQMNGYHC2EWT7DSU6DAXANCNFSM4U4K2D4A .
{ "@context": "https://schema.org/", "@type": "LocalBusiness", "name": "Independent Consulting Services", "description": "Research And Product Development" }
@ktk As a user, I can click '+' next to 'author', fill out the Person form that appears, and have that email address column validated client-side and serverside.
Things to add to https://www.w3.org/community/rdfjs/wiki/Comparison_of_RDFJS_libraries :
- react-schemaorg
- rdf-validate-shacl
Which of these RDFJS libraries have been evaluated for e.g. appropriate query parameterization (and string concatenation removal)? Are backticks in react JSX fine?
Welcome to greatness Wes.
Gratefully, Christopher M. Spradling
On Wed, Dec 16, 2020 at 3:51 PM Wes Turner [email protected] wrote:
@ktk https://github.com/ktk As a user, I can click '+' next to 'author', fill out the Person form that appears, and have that email address column validated client-side and serverside.
Things to add to https://www.w3.org/community/rdfjs/wiki/Comparison_of_RDFJS_libraries :
- react-schemaorg
- rdf-validate-shacl
Which of these RDFJS libraries have been evaluated for e.g. appropriate query parameterization (and string concatenation removal)? Are backticks in react JSX fine?
— You are receiving this because you commented. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-747062633, or unsubscribe https://github.com/notifications/unsubscribe-auth/ADFVNUR6RAPU7IK6EJ7M23TSVETWLANCNFSM4U4K2D4A .
@sumutcan - that sounds like a useful tool to be opensourcing - let's investigate interop testing in 2021!
here is the source code of our SDTT clone. The tool works more with a syntactic focus, so annotations are treated as JSON(-LD) documents rather than RDF graphs. We have not, for example, recognize expanded and flattened JSON-LD syntax as they throw errors in SDTT.
ok, as discussed earlier here:
http://blog.schema.org/2021/05/announcing-schema-markup-validator.html
From http://blog.schema.org/2021/05/announcing-schema-markup-validator.html ::
This is the focus of the new Schema Markup Validator (SMV). It is simpler than its predecessor SDTT because it is dedicated to checking that you're using JSON-LD, RDFa and Microdata in widely understood ways, and to warning you if you are using Schema.org types and properties in unusual combinations. It does not try to check your content against the information needs of specific services, tools or products (a topic deserving its own blog post). But it will help you understand whether or not your data expresses what you hope it expresses, and to reflect the essence of your structured data back in an intuitive way that reflects its underlying meaning.
The https://validator.schema.org service is powered by Google's general infrastructure for working with structured data, and is provided to the Schema.org project as a Google-hosted tool. We are also happy to note that many other schema.org-oriented validators are available, both commercial (e.g. Yandex's) and opensource. For example, the Structured Data Linter, JSON-LD Playground, SDO-Check and Schemarama tools. We hope that the new Schema Markup Validator will stimulate collaboration among tool makers to improve consistency and developer experience for all those working on systems that consume Schema.org data.
Where is the source for this?
How do I run Schema Markup Validator (SMV) in an e.g. GitHub Action CI task?
As the blog post explains it is not a standalone opensource toolkit but a service implemented as a part of Google’s general structured data infrastructure.
The post does link to some opensource validation tools which may be of interest- and it would be good to collaborate on interop amongst these
On Tue, 11 May 2021 at 20:55, Wes Turner @.***> wrote:
Where is the source for this?
How do I run Schema Markup Validator (SMV) in e.g. GitHub Action CI task?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-839078984, or unsubscribe https://github.com/notifications/unsubscribe-auth/AABJSGKKCTQNS4ACMVEU4ATTNGDSBANCNFSM4U4K2D4A .
Is there an acceptable or tutorial-documented way to use curl or e.g. requests/httpx to submit data to this new https://schema.org/WebAPI service?
You must understand that in order to add schema.org output validation to a quality-assured application, there need to be [build-] locally-executed tests for each commit/PR and/or API service request quotas; an external (manual?) dependency in my build is an anti-pattern.
Perhaps there's some combination of e.g. https://github.com/google/schema-dts and ( https://github.com/vazco/uniforms , https://github.com/rjsf-team/react-jsonschema-form ) or https://github.com/mulesoft-labs/json-ld-schema that would be usable offline in frequent, automated builds?
JSON Schema/SHACL based validation of JSON-LD documents
Wes - it is not an API. It is not opensource.
For opensource shacl/shex graph validation look at Schemarama, which integrates existing opensource code.
For opensource syntax validation reporting why don’t you see what you can find and report back to the community when you have tested what’s out there?
On Wed, 12 May 2021 at 00:03, Wes Turner @.***> wrote:
Is there an acceptable or tutorial-documented way to use curl or e.g. requests/httpx to submit data to this new https://schema.org/WebAPI service?
You must understand that in order to add schema.org output validation to a quality-assured application, there need to be [build-] locally-executed tests for each commit/PR and/or API service request quotas; an external (manual?) dependency in my build is an anti-pattern.
Perhaps there's some combination of e.g. https://github.com/google/schema-dts and ( https://github.com/vazco/uniforms , https://github.com/rjsf-team/react-jsonschema-form ) or https://github.com/mulesoft-labs/json-ld-schema that would be usable offline in frequent, automated builds?
JSON Schema/SHACL based validation of JSON-LD documents
—
You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-839263042, or unsubscribe https://github.com/notifications/unsubscribe-auth/AABJSGMGM3BHA3ZBFDSVXEDTNGZVHANCNFSM4U4K2D4A .
Presumably, underneath all of this new magic is an HTTP POST to an HTTP API. I'll see what I can do.
Maybe I haven't been clear in specifying the automated testing use case?
As a developer, I want to - on every commit/PR - check/validate/report_on the schema of the markup that my application produces in order to continuously assure quality. If I want to submit one or more application outputs to Schema Markup Validator (DMV; https://validator.schema.org/) in my test run - which runs for like every commit and pull request - is using a headless browser (like requests-html, puppeteer, playwright) the only option? Must end users run a Chromium instance to submit an HTTP POST to the SMV HTTP API? Presumably that re-requests the whole HTML page and it's associated assets and then makes an 'AJAX' request to a route in the SMV application which calls a function which generates output that end users want to optimize. Is it possible to simply Oauth and hit a request limit for that potentially serverless function? Who in Google could help add auth and quotas (and headless browser tests) to this new webform-based API?
- edit:
- how to [monetize a freemium] rate-limited [serverless] [webform-fronted] API with Apigee and Google Cloud Platform: https://cloud.google.com/apigee/docs/api-platform/get-started/what-apigee
If that's not in scope, I understand and no further communications in regards to this are necessary.
Hi Wes,
At the bottom of the announcement blog post, there is a list of tools with the same or similar purpose, which I think you can integrate into your workflow quite easily. I can talk for sdo-check for example (as a part of the team developing it): we provide a web interface (see my posts above) if you want to try it but also we provide the source code [1] if you would like to deploy it for your applications. We are of course open to any suggestions and pull requests.
[1] https://github.com/semantifyit/sdo-check
Wes - don’t try to screenscrape it. If it was suited for an API we would say so enthusiastically. I know why people want APIs, and I have done my best here to explain some other options. Try the opensource stuff and report back!
On Wed, 12 May 2021 at 13:46, Umutcan Şimşek @.***> wrote:
Hi Wes,
At the bottom of the announcement blog post, there is a list of tools with the same or similar purpose, which I think you can integrate into your workflow quite easily. I can talk for sdo-check for example (as a part of the team developing it): we provide a web interface (see my posts above) if you want to try it but also we provide the source code [1] if you would like to deploy it for your applications. We are of course open to any suggestions and pull requests.
[1] https://github.com/semantifyit/sdo-check
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-839742798, or unsubscribe https://github.com/notifications/unsubscribe-auth/AABJSGPH2Q7XULU73VCI67TTNJ2D5ANCNFSM4U4K2D4A .
SMV is a closed source, manual copy-and-paste only markup validator for the schema.org open schema specification effort. I would consider taking a look at Apigee for this new closed source service for the open schema schema.org project.
- edit: how to [monetize a freemium] rate-limited [serverless] [webform-fronted] API with Apigee and Google Cloud Platform: https://cloud.google.com/apigee/docs/api-platform/get-started/what-apigee
Are there other value-added closed source services developed by the schema.org project? Is closed source a new direction for the schema.org project? Is there intent to monetize this service? Apigee appears to be the best way for a new external customer to offer an API (a function made available over HTTP) using GCP.
I'm already out of time for good luck with this closed source service for an otherwise open specification effort from the start.
@westurner - I hear your frustration, but encourage you to think of it another way:
The Google SDTT tool was originally designed to help publishers check their markup meet eligibility requirements of Google search features. As the number of such features grew, the tool issued more and more errors and warnings - creating avoidable frustration. This validator.schema.org version is a very lightweight adaptation of that original system, and was only possible because it builds on the existing common infrastructure from Google Search which supports its other validation systems too (Rich Results Test, Search Console etc.). It is not a standalone software project developed for this purpose. It is SDTT with the page template changed and some Google-oriented validations turned off, approximately.
There is an analogy with the 'search' box you see on the schema.org site. Similarly, the Schema.org project has not developed or integrated an opensource search facility for its content; the "search" box you see on the site is provided via Google Custom Search, since 2011. The site's hosting is via Google AppEngine, etc. If someone contributed an opensource search feature, that could be great; but lots of great things don't always happen, so we have to be pragmatic.
I love opensource. I work in the Google Open Source Programs Office (OSPO). Last year I was delighted that we shared https://github.com/google/schemarama/ for graph shape validation, and which is entirely built on opensource RDF tooling (Microdata, RDFa, JSON-LD, ShEx, SHACL) plus other opensource libraries. However it does not currently do any syntax-level validation. In a previous life I built a proof of concept opensource Open Graph Protocol checker for Facebook (https://github.com/danbri/Pogo).
In the specific case of JSON-LD, RDFa and Microdata syntax validation, Schema.org had the opportunity to integrate a popular, very heavily used and tested structured data syntax checker. A tool that 1000s of publishers in the schema.org ecosystem already knew very well how to use. If there was a drop-in replacement that was 100% opensource, we could explore using that instead. But right now this is progress and useful and helpful for markup publishers, and it is opening a conversation around interoperability and testing. All of the development work was conducted by Google engineering, rather than as a part of the Schema.org project. I advised on integration to the schema site, documentation, and arranged for the guest blog post from Ryan, but it is best thought of as a contribution to Schema.org than a closed source system developed by schema.org. The responses from e.g. SEOs who work with schema.org daily suggest that it is widely appreciated as a helpful thing to have done.
I'll answer these explicit questions with explicit answers, but I don't think continuing this conversation is helpful to anyone here. Feel free to drop me a direct email ([email protected]) if you feel the need to talk more.
Q: Are there other value-added closed source services developed by the schema.org project? A: The Schema.org site is made possible thanks to a variety of systems. The core site is opensource (Python, rdflib, markdown, etc.), with data in RDFS/Turtle. However its blog is currently provided using Google Blogger, the site hosting on Google AppEngine, its website search function using Google Custom Search, and the markup validator is a Google-provided customization of Google's earlier SDTT service.
Q: Is closed source a new direction for the schema.org project? A: No. The project is pragmatic, and uses a variety of tools but does not itself develop closed source software.
Q: Is there intent to monetize this service? A: No.
BTW the first few years of Schema.org the entire site was generated as part of google.com's infrastructure, until Guha rewrote it in Python and we opensourced it.
I'm already out of time for good luck with this closed source service for an otherwise open specification effort from the start.
You might find it more rewarding to help at https://github.com/structured-data/linter
Speaking of the SDL, it is entirely open source and the components on which it is built could easily be used as part of a CI for any project (see github.com/ruby-rdf/rdf-reasoner). It is used as part of the scheme.org CI process, itself, to validate examples.
@thanks @gkellogg - we also had useful discussions a while back about sharing the opensource code (or at least UI style) that we have in schema.org (inspired by SDTT), that Anastasiia and Richard integrated into the "Structure" view next to our examples. Can you say anything here about SDL plans around UI?
It is SDTT with the page template changed and some Google-oriented validations turned off, approximately.
Thanks
If someone contributed an opensource search feature, that could be great; but lots of great things don't always happen, so we have to be pragmatic.
- Sphinx searchtools.js
- There may already be an issue for clientside search box autocomplete from the now-kept-current JSON-LD representation of the schema.org RDFS vocabulary?
- Is schema.org/Dataset search a custom search engine? Could there be a similar search engine that indexes RDFS vocabulary classes and properties? Like Google Scholar (which still only uses meta tags and wild PDF parsers not yet ScholarlyArticle, FWIU)
Last year I was delighted that we shared https://github.com/google/schemarama/ for graph shape validation, and which is entirely built on opensource RDF tooling (Microdata, RDFa, JSON-LD, ShEx, SHACL) plus other opensource libraries. However it does not currently do any syntax-level validation
A usage example just in the README would be helpful.
FWIU, Apigee can easily combine multiple functions into one API response; so you could also do syntax-level validation and just add that output to the SMV+validator endpoint.
People might pay for more than a reasonable free quota of SMV and/or e.g. structuredata/linter API requests, if ongoing costs are a real concern? E.g. SEOs and people with hundreds of daily CI jobs who recognize that optimizing the structured data (Linked Data) that their applications produce is in their interest: you want to make sure that your marked-up content is found, so checking output every time is a worthwhile cost.
The core site is opensource (Python, rdflib, markdown, etc.), with data in RDFS/Turtle. However its blog is currently provided using Google Blogger, the site hosting on Google AppEngine, its website search function using Google Custom Search,
- Looks like the site has evolved toward a JAM stack site that - because it doesn't depend upon any (?) AppEngine services really - could also be built with Cloud Build and hosted with Cloud Run. (LXC containers weren't quite merged into the kernel when AppEngine was started).
Q & A
Thanks, that restores confidence.
BTW the first few years of Schema.org the entire site was generated as part of google.com's infrastructure, until Guha rewrote it in Python and we opensourced it.
-
https://lov.linkeddata.es/dataset/lov/ still appears to be far too formidable, though 'schema' looks pretty big on the chart there
-
Are Bind, Yandex, Yahoo, or DuckDuckGo currently contributing resources to the schema.org open specification project? (Why haven't others implemented e.g. schema.org JSON-LD actions in email?)
@thanks @gkellogg - we also had useful discussions a while back about sharing the opensource code (or at least UI style) that we have in schema.org (inspired by SDTT), that Anastasiia and Richard integrated into the "Structure" view next to our examples. Can you say anything here about SDL plans around UI?
For those interested, the Structured-Data Linter emerged quite some time ago now, by people (me included) involved in the RDFa work, and later JSON-LD, as there was quite a lot of FUD on how schema.org and Google might work with Microdata or RDFa (now also JSON-LD) to create rich snippet output, and incidentally perform syntactic and semantics validation of the input. The rich snippet bits has languished, but the validation is very much quite useful, and has undergone surprisingly little change since it was first conceived (the power of simple/consistent RDFS inference coupled with update specific to schema.org.
The UI of the structured view, which is essentially the same as what @danbri described) is actually based on a generic RDFa serializer, which uses some heuristics to order and nest the entities found on the page. It uses a Haml template common to generic RDFa output, to generate the tabular result. Recently, I added this to the linter's example source as a "structured" representation (e.g., eg-0001). The details of how the RDFa serializer are win the Ruby RDFa writer, but the logic for ordering and nesting the results is largely shared with other writers/serializers such as the Turtle writer.
Work is going on to improve the UI and re-host on AWS which @jaygray0919 is leading, and may say more about it. Some of the ideas for an updated UI were proposed by @jvandriel marked up and suggested. These are captured in https://github.com/structured-data/linter/issues/40.

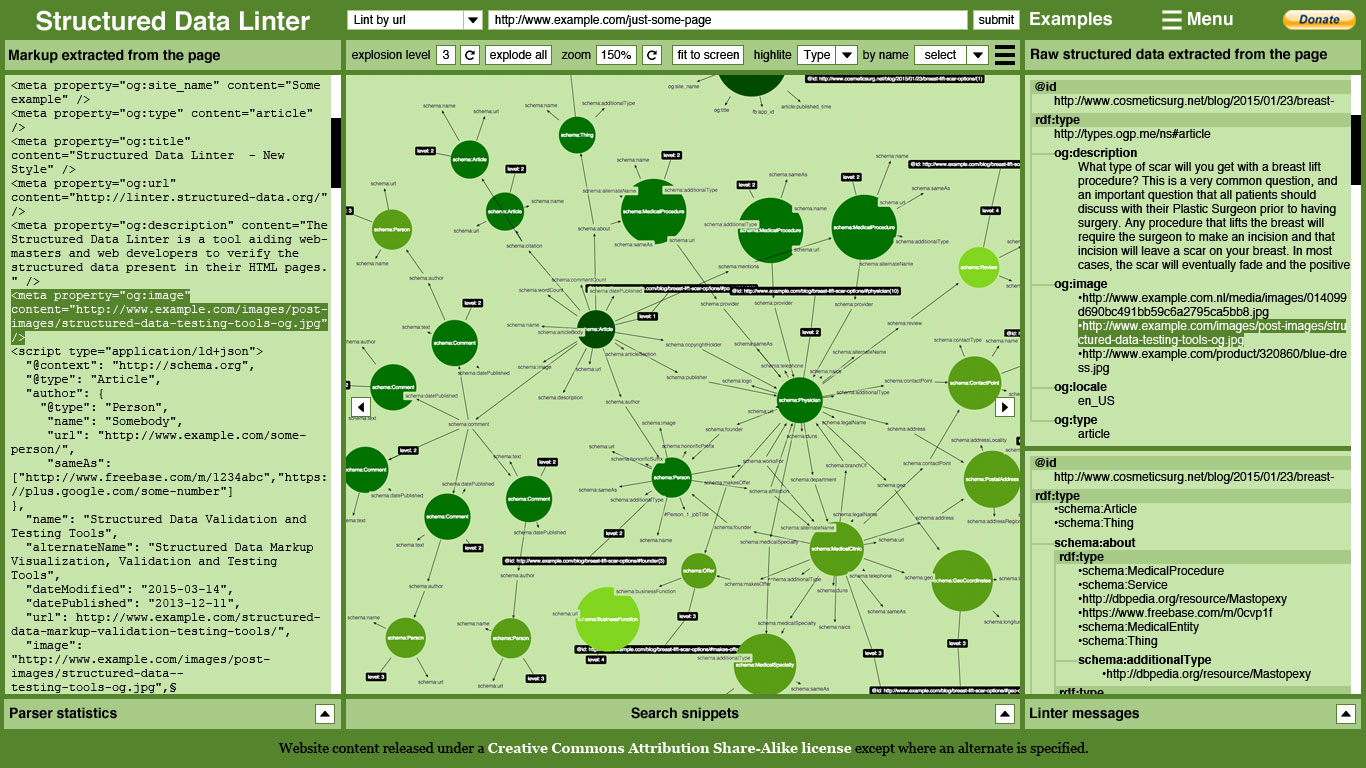
Speaking of the SDL, it is entirely open source and the components on which it is built could easily be used as part of a CI for any project (see github.com/ruby-rdf/rdf-reasoner). It is used as part of the scheme.org CI process, itself, to validate examples.
I haven't worked up a specific GitHub Action specifically for linting a file, and a package would be useful, if someone were interested in working together to create one. Basically, it might look something like the following:
name: CI
on:
push:
branches: [ '**' ]
pull_request:
branches: [ main ]
jobs:
lint:
name: Validate dataset in examples/example.html
runs-on: ubuntu-latest
steps:
- name: Clone repository
- uses: actions/checkout@v2
- name: Set up Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: 3.0.0
- name: Install dependencies
run: bundle install --jobs 4 --retry 3
- name: Validate example.html
run: bundle exec rdf lint examples/example.html
Of course, there are other options.
The bundle install command expects a Gemfile containing the basic dependencies, and these could be packaged in different ways. At a minimum, it would look like the following:
source 'http://rubygems.org'
gem "linkeddata"
The basic idea is to parse the HTML, which will extract the appropriate markup from the file, into an RDF Graph. The reasoner is used to detect perceived or actual incompatibilities and to expand the graph based on basic class/property descriptions. Any error messages are put into a simple JSON format for presentation, and the resulting graph is fed back to the RDFa writer to generate both Rich Snippets and the structured representations. The rdf lint ... command just does the inference and error/warning generation parts of this.
The basic idea is to parse the HTML, which will extract the appropriate markup from the file, into an RDF Graph. The reasoner is used to detect perceived or actual incompatibilities and to expand the graph based on basic class/property descriptions. Any error messages are put into a simple JSON format for presentation,
- W3C EARL may or may not be of value; particularly for comparing implementations:
-
Here's an example of a WCAG (Web Content Accessibility Guidelines) report in W3C EARL (Evaluation and Reporting Language): https://github.com/w3c/wcag-em-report-tool/blob/master/docs/EARL%2BJSON-LD.md
-
The JSON-LD test suite EARL reports: https://json-ld.org/test-suite/reports/
- https://json-ld.org/test-suite/reports/earl.jsonld
- https://json-ld.org/test-suite/reports/earl.ttl
-
and the resulting graph is fed back to the RDFa writer to generate both Rich Snippets and the structured representations. The rdf lint ... command just does the inference and error/warning generation parts of this.
DVC tracks output hashes from each stage of the data pipeline in dvc.lock files. FWIU, there's not yet any support for e.g. (schema.org) Linked Data in general and/or W3C PROV for tracking the provenance of each output from each necessary container image and command.
- https://dvc.org/doc/user-guide/project-structure/pipelines-files#dvclock-file
- https://www.w3.org/TR/prov-primer/#introduction
I haven't worked up a specific GitHub Action specifically for linting a file, and a package would be useful, if someone were interested in working together to create one.
A pre-commit hook for linting and validating with locally-installed tools (and/or hosted [validator,] APIs that already have the container built and a port mapped and SSL) might be useful as well? https://pre-commit.com/#new-hooks
- AppEngine
- Managed Runtime instead of a container with an SBOM to lifecycle as well, Managed metered services
[The site] could also be built with Cloud Build and hosted with Cloud Run.
- Google Cloud Build:
- build static schema.org pages
- build JSON for clientside autocomplete of schema.org [classes, properties,]
- build TypeScript with https://github.com/google/schema-dts
- (edit) build validating forms for each class and property
- only initialize and display the form+textarea on click (below the existing examples)
- display the JSON-LD, Microdata, RDFa output in an e.g.
<textarea>with or without syntax highlighting - generate examples to be copied and pasted into pull requests
- generate examples for developers to copy and paste into their static pages and templates
- this could cut down on free requests to SMV
- Google Cloud Run:
- host the static site container
- Google Cloud Functions
- HTTP API: host functions (container, function) such as linting and validation
- Google Cloud Endpoints
- HTTP API: deploy and scale an [OpenAPI, gRPC, AppEngine] API with tokens
- Google Apigee
- Front an HTTP API with [free] quotas, per-api-token billing (monetization)
Anyways, way OT
Why not 50, or 100? Eventually a cutoff is needed and people will have larger files. It is perhaps better to think of it as a way to check the general approach than to check every single doc...
On Sun, 23 May 2021 at 10:54, jay gray @.***> wrote:
@danbri https://github.com/danbri Would you consider increasing the SMV file size limit? Currently, it is 2.5MB. Could you raise the limit to 4MB?
/jay
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/schemaorg/schemaorg/issues/2790#issuecomment-846535622, or unsubscribe https://github.com/notifications/unsubscribe-auth/AABJSGPYR6ZOXGUHMHMHUNTTPDGD7ANCNFSM4U4K2D4A .