futures-rs
 futures-rs copied to clipboard
futures-rs copied to clipboard
Rewrite `BiLock` lock/unlock to be allocation free
Inspired by a previous attempt to remove allocation (#606), this version uses three tokens to synchronize access to the locked value and the waker. These tokens are swapped between the inner struct of the lock and the bilock halves. The tokens are initalized with the LOCK token held by the inner struct, the WAKE token held by one bilock half, and the NULL token held by the other bilock half.
To poll the lock, our half swaps its token with the inner token: if we get the LOCK token we now have the lock, if we get the NULL token we swap again and loop if we get the WAKE token we store our waker in the inner and swap again, if we then get the LOCK token we now have the lock, otherwise we return Poll::Pending
To unlock the lock, our half swaps its token (which we know must be the LOCK token) with the inner token: if we get the NULL token, there is no contention so we return if we get the WAKE token, we wake the waker stored in the inner
Additionally, this change makes the bilock methods require &mut self
Thanks! It seems the previous attempt had performance issue, so I'm curious if this implementation fixed that issue.
Sure, here's some benchmarks with criteron on my Ryzen 2700X desktop. I also did some preliminary benchmarks on my ARM phone with similar results, although with a slight (40us -> 50us) regression on lock_unlock for some reason. Additionally with the old implementation the contended benchmark was leaking memory like crazy on ARM, allocating over 8GB during the ~5s benchmark run.
concurrent
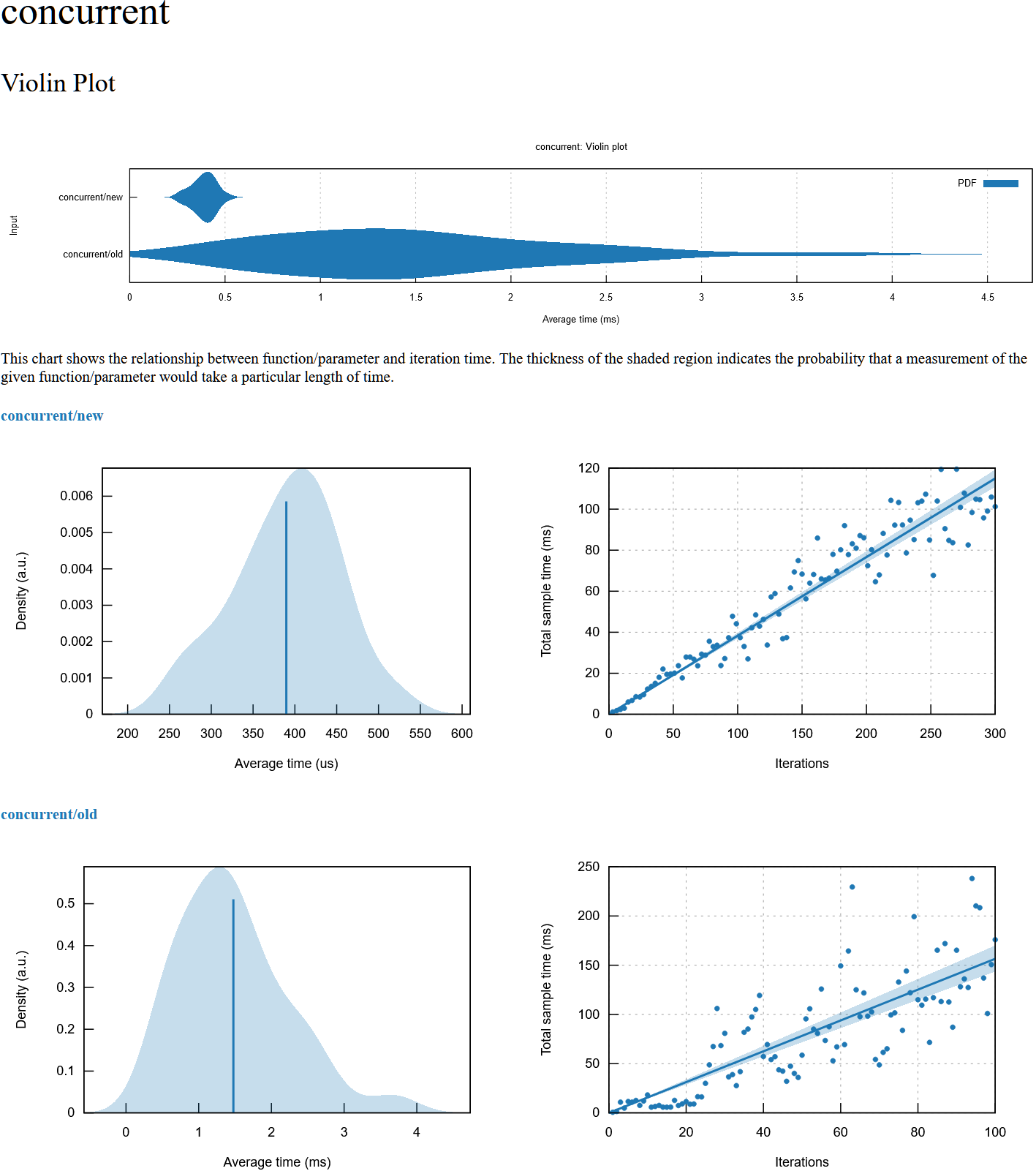
contended

lock_unlock
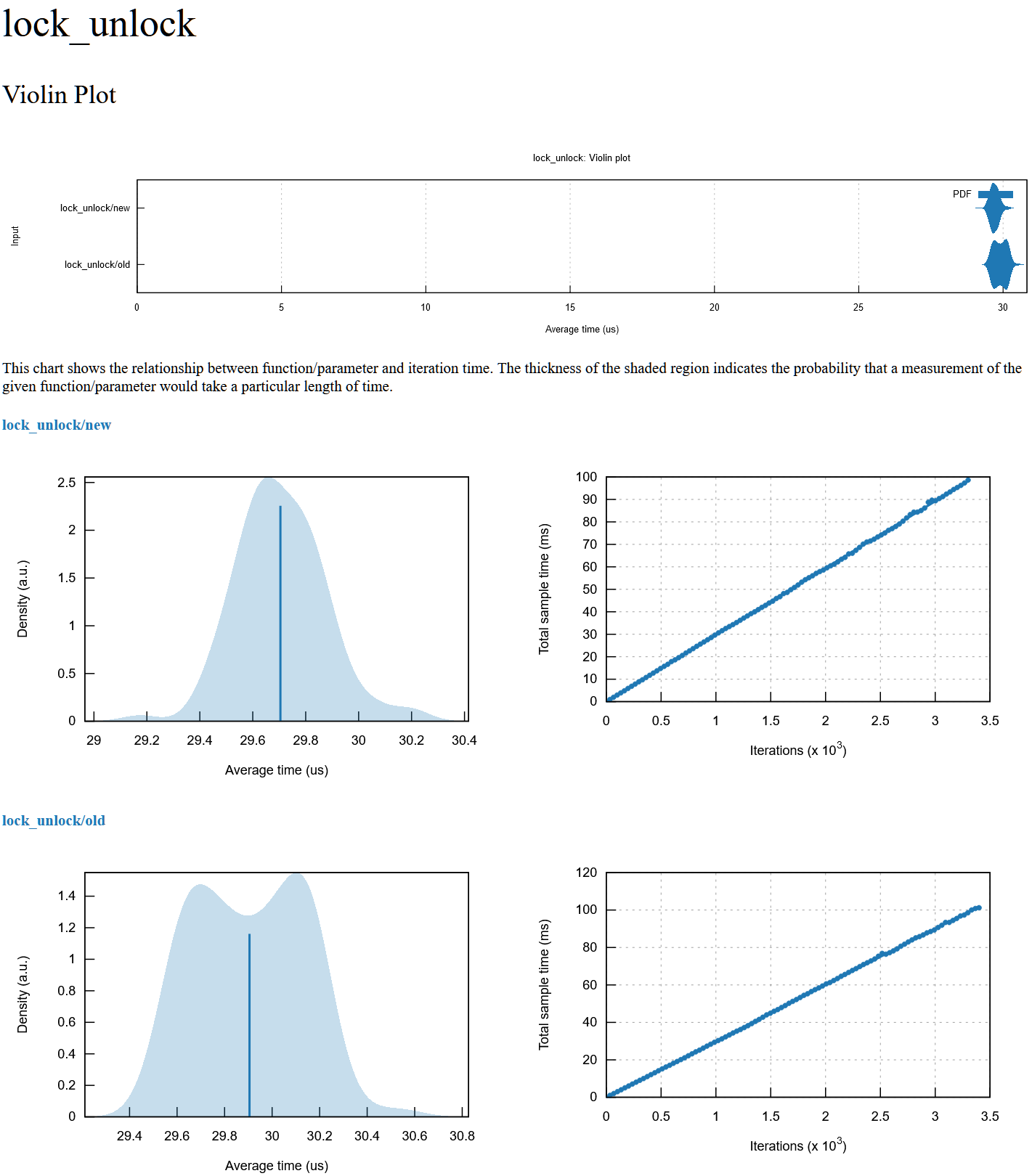
mobile aarch64 benchmarks:
concurrent
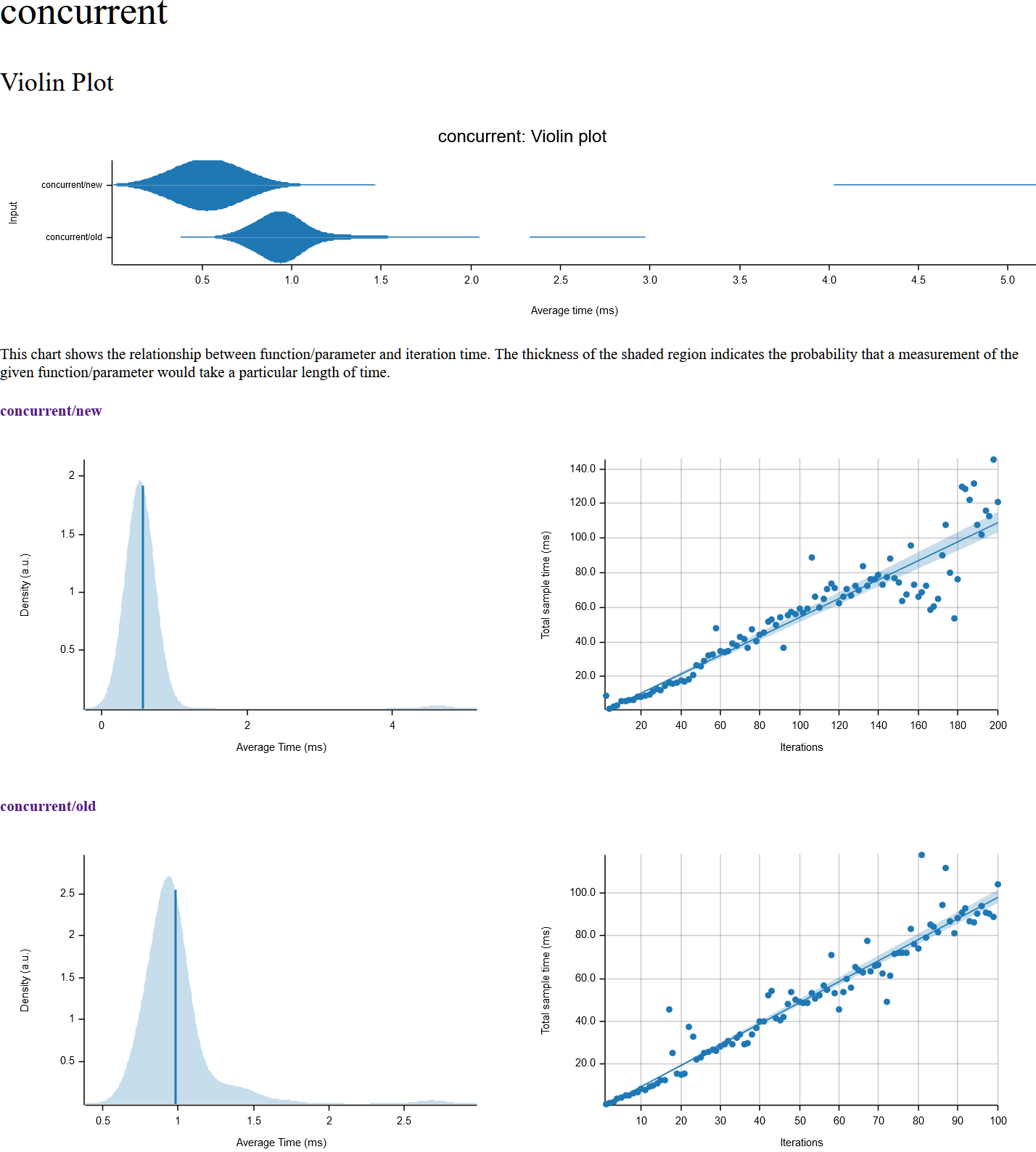
contended
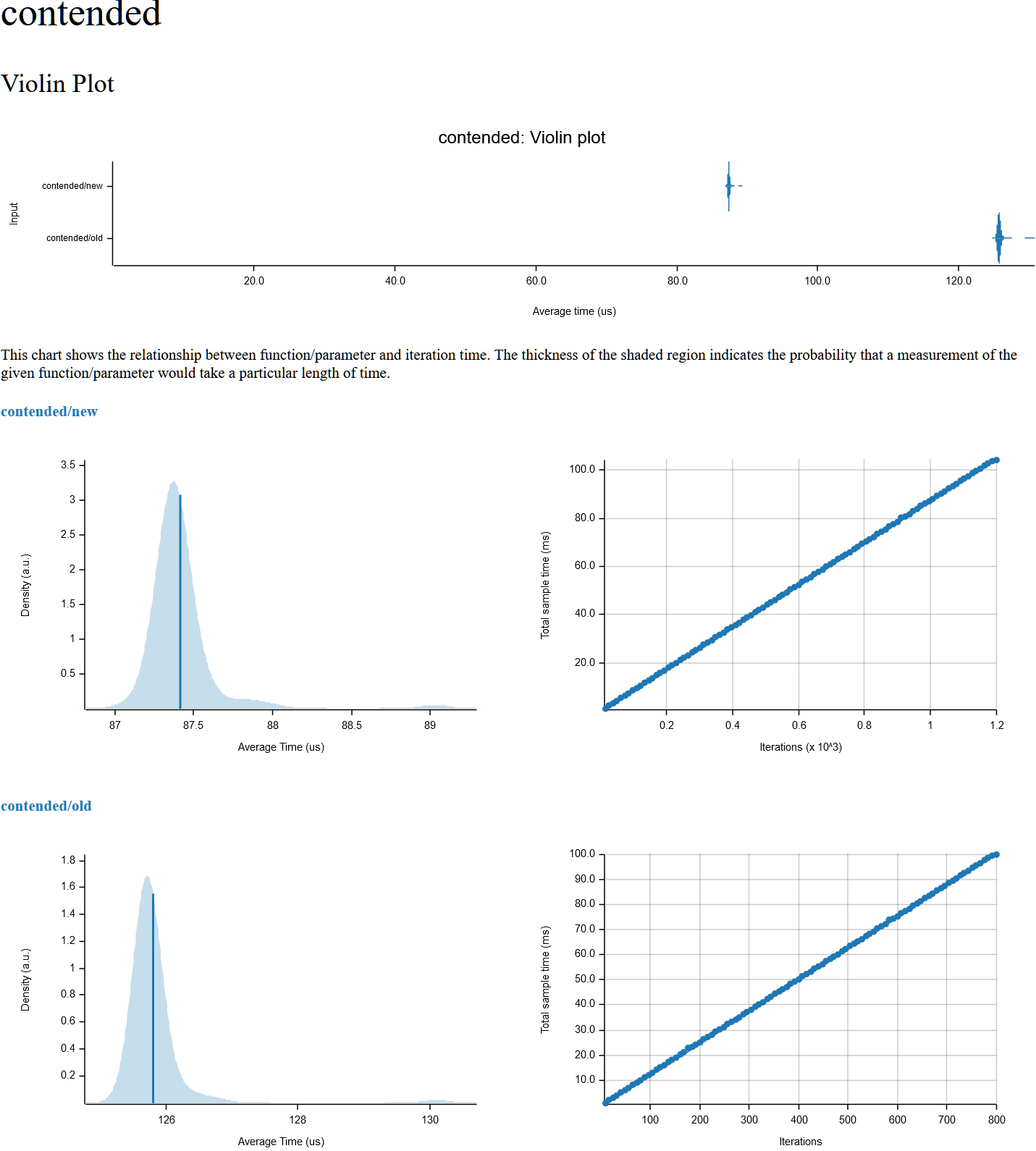
lock_unlock

FWIW, results on my MacBook Pro (Intel Core i7-9750H, macOS v11.2.3).
old (2be999da)
test bench::concurrent ... bench: 4,328,809 ns/iter (+/- 2,353,379)
test bench::contended ... bench: 94,411 ns/iter (+/- 12,618)
test bench::lock_unlock ... bench: 23,861 ns/iter (+/- 1,640)
new (37c66f61)
test bench::concurrent ... bench: 486,154 ns/iter (+/- 92,153)
test bench::contended ... bench: 41,488 ns/iter (+/- 10,598)
test bench::lock_unlock ... bench: 25,685 ns/iter (+/- 1,622)
new (3208bb56)
test bench::concurrent ... bench: 480,203 ns/iter (+/- 73,745)
test bench::contended ... bench: 39,459 ns/iter (+/- 2,696)
test bench::lock_unlock ... bench: 24,195 ns/iter (+/- 1,498)
new (08707e3a)
test bench::concurrent ... bench: 558,425 ns/iter (+/- 36,155)
test bench::contended ... bench: 51,819 ns/iter (+/- 7,067)
test bench::lock_unlock ... bench: 32,035 ns/iter (+/- 4,968)
new (be2242e0)
test bench::concurrent ... bench: 491,844 ns/iter (+/- 96,733)
test bench::contended ... bench: 39,943 ns/iter (+/- 11,236)
test bench::lock_unlock ... bench: 24,148 ns/iter (+/- 881)
new (aa5f1290)
test bench::concurrent ... bench: 554,916 ns/iter (+/- 75,457)
test bench::contended ... bench: 38,764 ns/iter (+/- 6,630)
test bench::lock_unlock ... bench: 25,267 ns/iter (+/- 4,527)
new (c8788cdb)
test bench::concurrent ... bench: 448,243 ns/iter (+/- 54,914)
test bench::contended ... bench: 247,089 ns/iter (+/- 47,252)
test bench::lock_unlock ... bench: 23,646 ns/iter (+/- 5,088)
Both 3208bb56 and be2242e0 look good on my machine (I tend to prefer 3208bb56, which is compatible with thread sanitizer).
any progress here? I would love to see the bilock feature not requiring nightly.