docs.rs
 docs.rs copied to clipboard
docs.rs copied to clipboard
CDN invalidation: decide what to do about quotas
According to https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/cloudfront-limits.html#limits-invalidations:
File invalidation: maximum number of active wildcard invalidations allowed 15
So, during times of heavy building (particularly when many crates in a family are released at once), we are likely to hit this limit. Presumably it will depend on how long the invalidations actually take.
We should decide what to do about these:
- queue the invalidations
- drop them when we hit the limit
- try to cluster same-prefixed crates that are built at once into a single invalidation
- if we hit the limit, set a ten-minute timer (to capture additional clustered builds), and invalidate the whole distribution when the timer expires
Valid point, I missed that, we will definitely hit this at some point, my guess would be only when we have much higher build capacity, much better caching, or many build-failures in a short time.
In these cases I prefer optimistic / simple approaches, which means:
when we get a rate-limit error we retry after some time. A local queue could optimize this behaviour when we have many builds.
In these cases I prefer optimistic / simple approaches
Same!
when we get a rate-limit error we retry after some time.
One question with this: will we get into a state where the retry queue grows without bound?
Looking at https://docs.rs/releases/activity it seems we average at least 600 releases per day. If an average invalidation takes 5 minutes and we can have 15 in parallel, that's 3 invalidations per minute throughput. With 1440 minutes in a day, we could handle up to 4320 builds per day before we wind up in unbounded growth land. Of course, that's based on a significant assumption about how long an invalidation takes.
If we're going to have a queue anyhow, maybe it makes more sense for all invalidations to go onto that queue, and have an independent component responsible for managing the queue? That way it could keep track of how many validations are inflight and avoid hitting the quota unnecessarily.
We'll also want a way for the docs.rs team to clear the queue (and, separately if needed, invalidate the whole distribution).
One other consideration: when the queue does start growing faster than we can clear it, how do we want to handle that? It may be better to treat it as a stack. That way more recently built crates are more likely to have a successful invalidation; crates that have been waiting on an invalidation for a long time are lower priority since their contents are likely to fall out of the CDN independently due to age.
Another approach (a pessimistic one) would be probably:
- collect paths to invalidate in a separate table
- once a minute (or something like that), push the collected invalidations to cloudfront
the problematic limit is on invalidation-requests, not on paths.
Since we would have to have a persistent queue anyways for the retries we could also base the whole thing on it. Without a persistent queue we might loose a needed purge after build.
If an average invalidation takes 5 minutes and we can have 15 in parallel
On that I'll try to collect some data. According to the docs an invalidation can take up to 15 minutes.
Another approach (a pessimistic one) would be probably:
collect paths to invalidate in a separate table once a minute (or something like that), push the collected invalidations to cloudfront
Aha, I like this approach. Coindicentally, it's quite similar to what we implemented for letsencrypt/boulder's similar cache invalidation (for OCSP responses).
in a small dummy distribution the invalidation only takes some seconds.
This probably looks different with more files to invalidate, we'll see in prod.
It seems like there is also a rate-limit on the API calls, but information is confusion here (https://github.com/aws/aws-sdk-js/issues/3983#issuecomment-1238959245).
We'll see how it looks like after #1864 is deployed
the problematic limit is on invalidation-requests, not on paths.
I think it's number of paths, for the non-wildcard ones they say
If you’re invalidating files individually, you can have invalidation requests for up to 3,000 files per distribution in progress at one time. This can be one invalidation request for up to 3,000 files, up to 3,000 requests for one file each, or any other combination that doesn’t exceed 3,000 files. — https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/Invalidation.html#InvalidationLimits
short update here:
especially in combination with the rebuilds from #1181 we're running into an too many active wildcard invaldations error in cloudfront, multiple times a day:
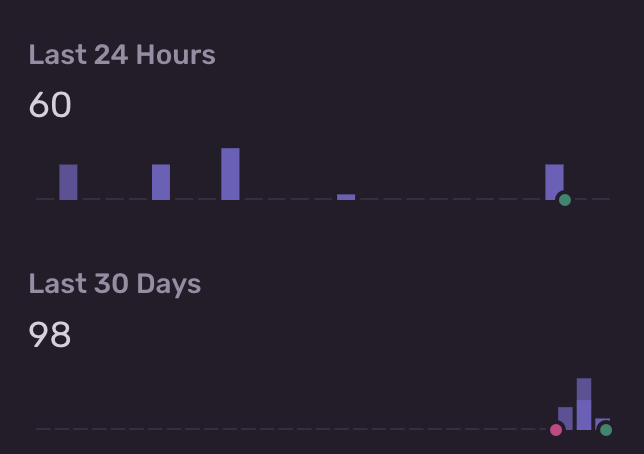
So we have to handle this before we can activate the full page cache again.
@syphar
According to the docs an invalidation can take up to 15 minutes
where did you find that number in the docs, i'm not seeing it and just trying to confirm.
I'm sorry but I don't find it any more. I'm not sure if they removed it.
One thing I am sure: I did many manual tests and the invalidations took ~13-15 minutes to finish.
update on this issue here:
Since #1961 we have a queue for these invalidations.
Through the queue we are
- fully using the available invalidations,
- directly enqueueing new ones after a spot becomes empty, and - spreading out eventual peaks
Also we are starting to track some metrics around the queue, later around invalidation execution times.
There is a pending optimization to be done where paths are sometimes queued multiple times for example when multiple releases of a crate are yanked. These can be de-duplicated before they are sent to CloudFront.
We can think about further improvements (from above):
- escalating into a full distribution invalidation, when the queue is too full, or
- switching to invalidating a full crate-name prefix if we see the invalidations take too long.
Before digging into optimizations there is also the option to at some point switch to fastly, where invalidation are much faster and without limits, but also not path-based but tag-based.
Currently I'm leaning towards closing this issue when we de-duplicate the paths, and added the pending metric PRs.