redux-toolkit
 redux-toolkit copied to clipboard
redux-toolkit copied to clipboard
Add `upsertQueryData` functionality
I have a use case where I would like to pass an additional parameter when calling an endpoint, where I do not want this additional parameter to be cached. The first parameter, args, would still be serialized as the cache key as normal.
Would it be possible to provide an additional field to pass some additional data when calling an endpoint via a hook/initiate? My use case is for calling a query endpoint with initiate.
Perhaps an additional optional parameter after options? Something likeextraArgs, noCacheArgs, or nonCacheableArgs. I don't know if it makes sense have it on the options parameter, https://redux-toolkit.js.org/rtk-query/api/created-api/endpoints#initiate, but that would work too.
Specifically, my use case is to cache the result from a create api call in a different cache. I can do this, but it comes at the cost of having to override serializeQueryArgs, and having to have some additional logic in the providesTags field for postById.
If I could pass the response from createPost in postsClient.endpoints.postById.initiate, I could see that I have that data in the queryFn for getById, and if so, return it, caching it, and if not, call the api and cache it as normal.
import { createApi } from "@reduxjs/toolkit/query/react";
import posts from "some-api";
import { getByIdProvidesTags, getByIdQueryFn, mapClientResponse, serializeGetByIdArgs } from "./postsHelper";
export const POSTS = "posts";
export const POST_BY_ID = "postById";
const { get: getPosts, getById: getPostById, create: createPost, update: updatePost } = posts;
const postsApi = createApi({
reducerPath: "posts",
tagTypes: [POSTS, POST_BY_ID],
baseQuery: ({ args, method }) => method(...args).then(mapClientResponse),
serializeQueryArgs: serializeGetByIdArgs(POST_BY_ID),
endpoints: (builder) => ({
posts: builder.query({
query: (args) => ({ args: [args], method: getPosts }),
providesTags: (result, error, args) => [{ type: POSTS, id: JSON.stringify(args) }],
}),
postById: builder.query({
queryFn: getByIdQueryFn(getPostById),
providesTags: getByIdProvidesTags(POST_BY_ID),
}),
createPost: builder.mutation({
query: (args) => ({ args: [args], method: createPost }),
invalidatesTags: (result, error) => (error ? [] : [{ type: POSTS }]),
onQueryStarted: (_args, { dispatch, queryFulfilled }) =>
queryFulfilled.then(({ data }) => dispatch(postsClient.endpoints.postById.initiate(data))),
}),
updatePost: builder.mutation({
query: (args) => ({ args: [args], method: updatePost }),
invalidatesTags: (result, error) => (error ? [] : [{ type: POSTS }]),
}),
}),
});
export default postsApi;
export const { usePostsQuery, usePostByIdQuery, useCreatePostMutation, useUpdatePostMutation } = postsClient;
Without the code for getByIdQueryFn and serializeGetByIdArgs and maybe a bit more in-depth explanation, I really have no idea what exactly you are trying to accomplish here, sorry.
Generally, no, that is not supported, and so far I have not seen a use case valid enough to add first-class support for it, as it is very uncommon, there are ways around it (although clumsy) and would probably lead to lots of bugs and unexpected behaviour for users: the serialized arg is the base for the decision "do we make another request?" and many people would wonder why, even if they changed an argument, no additional request would be made.
This is what those two functions look like.
// Serialize args for getById endpoints
// Use when calling getById endpoint by either the id or the passed object to map the id from passed object to serializedKey
export const serializeGetByIdArgs =
(getByIdEndpointName: string) =>
({ endpointName, queryArgs }) =>
`${endpointName}(${
endpointName === getByIdEndpointName && isObject(queryArgs) ? queryArgs.id : JSON.stringify(queryArgs)
})`;
// Call getById and cache response if id passed as args, or cache getById object if object passed as args
// Use when calling getById endpoint by either the id or with an object to cache the object based off its id instead of retrieving it and then caching it
export const getByIdQueryFn =
(method) =>
<T>(args, _api, _extraOptions, baseQuery): MaybePromise<QueryReturnValue<T, unknown, unknown>> =>
isObject(args) ? { data: args } : baseQuery({ args: [args], method });
// Provide id as tag id if id passed as args, or provide object id as tag id if object passed as args
// Use when calling getById endpoint by either the id or with an object to map the id from from passed object to tag
export const getByIdProvidesTags = (tagName) => (result, error, args) =>
[{ type: tagName, id: isObject(args) ? args.id : args }];
Essentially what I'm doing with them is handling the case where instead of passing the id to postById to retrieve the post by id (the usual case), I'm passing the entire post as the arg to cache it in postById, without actually making the call to retrieve it.
If I could pass an additional parameter to an endpoint, I could avoid having to override the method serializeGetByIdArgs and not have the extra logic to handle two different types of args (the id or the post) in getByIdProvidesTags and getByIdQueryFn.
Instead in createPost I could do something like:
createPost: builder.mutation({
query: (args) => ({ args: [args], method: createPost }),
invalidatesTags: (result, error) => (error ? [] : [{ type: POSTS }]),
onQueryStarted: (_args, { dispatch, queryFulfilled }) =>
queryFulfilled.then(({ data }) => dispatch(postsClient.endpoints.postById.initiate(data.id, undefined, { data }))),
}),
and then getByQueryFn could look like so, so that the endpoint method is only called when extraArgs.data is falsy, else we cache the data, as in my case the response returned from createPost is the same as postById.
export const getByIdQueryFn =
(method) =>
<T>(args, _api, _extraOptions, baseQuery, extraArgs): MaybePromise<QueryReturnValue<T, unknown, unknown>> =>
extraArgs?.data ? { data: extraArgs.data } : baseQuery({ args: [args], method });
I can think of some additional cases where having a place to put args that aren't part of the cache key would be useful.
One might be if you needed to have different options when calling an endpoint. Perhaps something like having a different retry or backoff approach for an endpoint when called from one place, but not another.
These options would have to be passed to the endpoint conditionally, and to have them share a cache and do so is not easy.
So in that specific use case... how should provides work? If invalidated, it would fire the same query and return the old value instead of fetching new, updated data from the server. Are you sure you don't just want to prime your cache with some data from another source?
In that case, cache management utilities might be more useful.
As for different backoffs: imagine, two component are mounted with the same cache entry - but different backoffs. Which would win? And if the components mounted in a different order, or the first one rerendered after the second one rendered, which one would win then? Would it cause a request every time?
Coordinating something like that is very complicated - even for built-in functionality like polling. Having it only on the endpoint is at least a bit more manageable.
Basically, there is one route to pass data to queries/mutations, that is through args. I want a backdoor to pass additional data, called extraArgs, with the difference made clear that anything passed through this backdoor will not be subject to any of the rules/side effects of args.
Provides would still behave the same, my "backdoor" cached items should behave no different than one that is normally cached.
I looked into the cache management utilities and I couldn't really find any way to provide what I want. I want the posts cached by id as args in the rtk query api endpoint, but I want to be able to freely create new cache entries, without going through the process of calling the endpoint api to retrieve the data.
Really, even more to my point and more direct/useful would be a method like
createQueryData(endpoint, args, data) // endpoint being the endpoint, same as in updateQueryData, args - the cache args, data - the data we want to cache
postsClient.util.createQueryData("postsById", data.id, { data }), that I could call instead the weirdness I'm doing calling postsClient.endpoints.postById.initiate(...), in createPost -> onQueryStarted. However, I think there may be an issue opened for something like this.
Backoffs may be more complicated on further consideration.
As far as I know, people have been using patchQueryData with a patch in the form [ { op: "replace", path: [], value: yourNewValue ] for that.
That doesn't work for my use case. patchQueryData will only update query data for a cached entry. It won't create if there's not one there.
Fascinating, someone was reporting they were doing this. But yeah, looking at the code, it shouldn't work.
I guess sooner or later we will need a upsertQueryData functionality. I'm not a fan of it, because it will enable a lot of patterns people could use to hurt themselves, but I guess they'll find workarounds that are even more dangerous otherwise.
I guess they'll find workarounds that are even more dangerous otherwise.
Indeed we will, haha. Thank you for taking the time to understand my problem.
In my RTK-Query API slice, I have single entity queries and list queries and they both return same type of objects. When I do a list query then I would like to upsert the cache for single entity queries. So this feature would help out. :)
Another potential use case: With projects like Next.js - during SSR we may want to use cached API responses for endpoints that have largely static payloads. At the moment, if we want to use RTKQuery we're kind've out of luck as there isn't a nice way to insert this data without firing off a HTTP request. This results in some SSR endpoints being much slower than they need to be.
@phryneas can you think of a way around this that wouldn't require this upsertQueryData functionality?
This is now available in https://github.com/reduxjs/redux-toolkit/releases/tag/v1.9.0-alpha.1 . Please try it out and let us know how it works!
@markerikson Thanks for this release, I'm excited to try it out!
So in my situation, we are sending a cart_token, which is our cache key, to our API but that token can be either an encoded one that generates a unique token OR it can be the unique token itself. For example, if I send the API __c__generatedToken==, I'll receive {data: {cart_token: asdfghjkl12345 ...}}. Or I can send it asdfghjkl12345 and get the same data. That's why we want to de-duplicate this entry because the __c__generatedToken== is only used once at the beginning and up until now, we have been fetching from the API twice, once with the generation token and once with the unique token, just to fill the cache entry.
So here's my endpoint:
import { vrioApi } from '../vrioApi';
const extendedVrioApi = vrioApi.injectEndpoints({
endpoints: (builder) => ({
carts: builder.query<any, { cart_token: string }>({
query: ({ cart_token }) => ({
url: `carts/${cart_token}`,
method: 'GET',
}),
transformResponse: (response) => ({
...(response as any),
order: {
...(response as any).order,
shipping_profile_id:
(response as any).order.shipping_profile_id ?? '',
},
}),
async onQueryStarted(_arguments, { dispatch, queryFulfilled }) {
try {
const { data } = await queryFulfilled;
dispatch(
extendedVrioApi.util.upsertQueryData(
'carts',
{ cart_token: data.cart_token },
data
)
);
} catch {}
},
}),
}),
overrideExisting: true,
});
export const { useCartsQuery, useLazyCartsQuery } = extendedVrioApi;
When I run this, I get an infinite loop of the onQueryStarted function. I can see that data is correct but it just loops forever and never gets to the next function. Am I doing something wrong here? Should I not add it to the onQueryStarted callback?
Hmm. That... actually sorta makes sense, given how we implemented upsertQueryData.
We opted to implement it as a tweak to our existing "actually start this async request" logic. That runs the entire standard request sequence, including dispatching actions...
and also the cache lifecycle methods.
You've got an onQueryStarted, in a carts endpoint, that is also upserting into a carts endpoint. So, the initial actual request is going to run onQueryStarted, which is going to call upsertQueryData, which then triggers its own onQueryStarted, which.... recurses.
I'm going to say this is probably a bug in the design and we'll have to rethink some of this behavior.
@phryneas , thoughts?
I don't really get what you are trying to do here. The code updates the exact same cache entry with the value it already just got?
@phryneas it's more like the cache key we initially use is for generating the cache key that we want to use thereafter:
- The user hits a URL with
__c__asdfghjkl12345==in the URL. - This is what we use to fetch the cart so we pass it as the argument to the query.
- The API identifies this argument as one that generates a unique
cart_tokenand returnsdatawith that. - The unique
cart_tokenreturned indatais what we want to continue referencing, so we also update thecart_tokenwith the unique one when we've received.
If a user were to keep hitting the URL with __c__asdfghjkl12345== in it over and over again, they'd keep creating unique cart_tokens and they'd never be able to mutate the cart and complete the order because it's not actually tied to data.
Walking you all through this it makes me wonder, if we can identify the generation token, would it be better to use a mutation to "create" the unique token with the upsertQueryData function?
Or at least you should check that the endpoint you want to update is not the endpoint that just has been updated - I mean, just compare the argument of the current query with the argument of the query you want to upsert.
@phryneas that seemed like the most streamlined approach so I tried it and I could get out of the infinite loop, so thanks for that!
However, I am still hitting the API for that cart_token. Basically, when the cart_token in data differs from the one in the URL, I redirect to the one from data, which triggers a query for that one. What I'm expecting upsertQueryData to do is to add that cache entry so when I change the URL, it just fetches the cached value. Instead, it appears to be still trying to fetch it from the API i.e., I still get 2 query calls even though I should have a cache entry that I upserted already.
Edit: Working on my implementation so maybe it's something on my end.
Do you see onQueryStarted executing twice or two actual requests?
upsertQueryData triggers the lifecycle methods as if a request would be made, that is intended. It doesn't really make a request though, but immediately resolves with the upserted data.
I'm hoping my use-case isn't super specific to the point where this isn't helpful but let me flesh out the application a bit more:
First of all, before I can even fetch the data from API, I need an access_token, which I've used standard Redux state to hold since it is easily accessible from within RTK Query i.e., I wrap the axios call for a custom query function with the necessary access_token header.
Therefore, I don't make the useCartsQuery call until I have an access_token, then I use useLazyCartsQuery to trigger it when I do. Unfortunately, it'll take a bit of work to go around that check so I would like to avoid that unless you tell me this won't work with lazy queries.
After that lazy query, I compare the returned cart_token from the data with what's in the URL (this is a Next.js application so I use the useRouter hook to grab that). Then I redirect to the proper Next.js dynamic route containing the cart_token from data. For example, if I go to http://localhost:3000/__c__asdfghjkl12345, fetch the cart, and receive a new cart_token = "newCartToken", I redirect to http://localhost:3000/newCartToken. Then the application would check for an access_token, which we have from before, and immediately trigger the useLazyCartsQuery function to fetch the new data. I call that with cartsQuery({cart_token: 'newCartToken'}, true); to prefer the cached value.
So the questions are:
- Is using a lazy query going to work with
upsertQueryData? - Could the redirect and unmounting + remounting components be clearing the cache somehow?
@phryneas in response to your question, I see the onQueryStarted running twice, although in the conditional for upsertQueryData, it only runs once. On top of that, I see a second API request in the Firefox console to get the cart with the new token. That second API request shouldn't be happening if we have it in the cache and I'm preferring that value with the lazy query, correct?
In the Redux Devtools, should I see two entries on fulfillment of the first query, right?
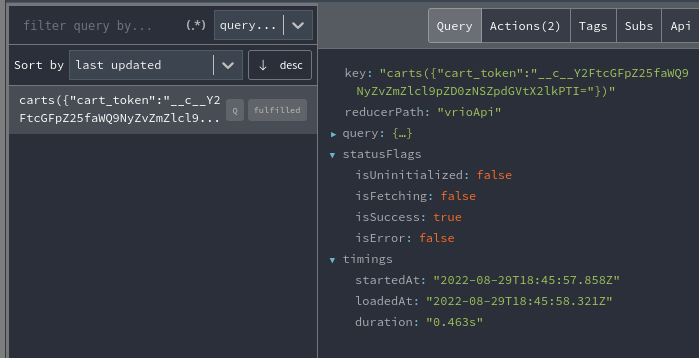 I only ever see one then it tries to get a new entry from the API.
I only ever see one then it tries to get a new entry from the API.
However, this is interesting:
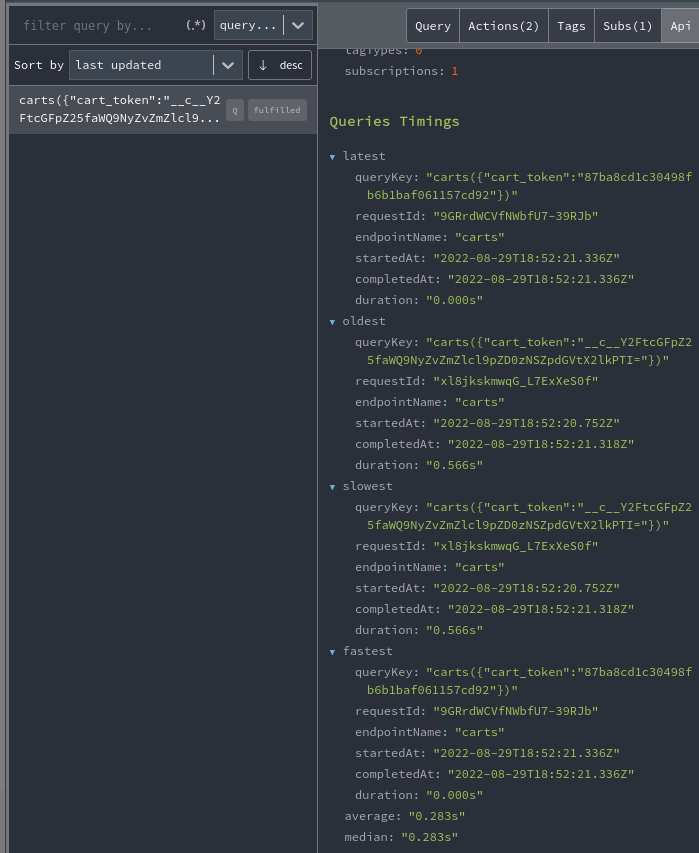
I actually have it as a query in there at the bottom as the fastest one, I just can't seem to access it without pinging the API
Sorry for spamming, this is the entire lay of the land so you can see the issue:
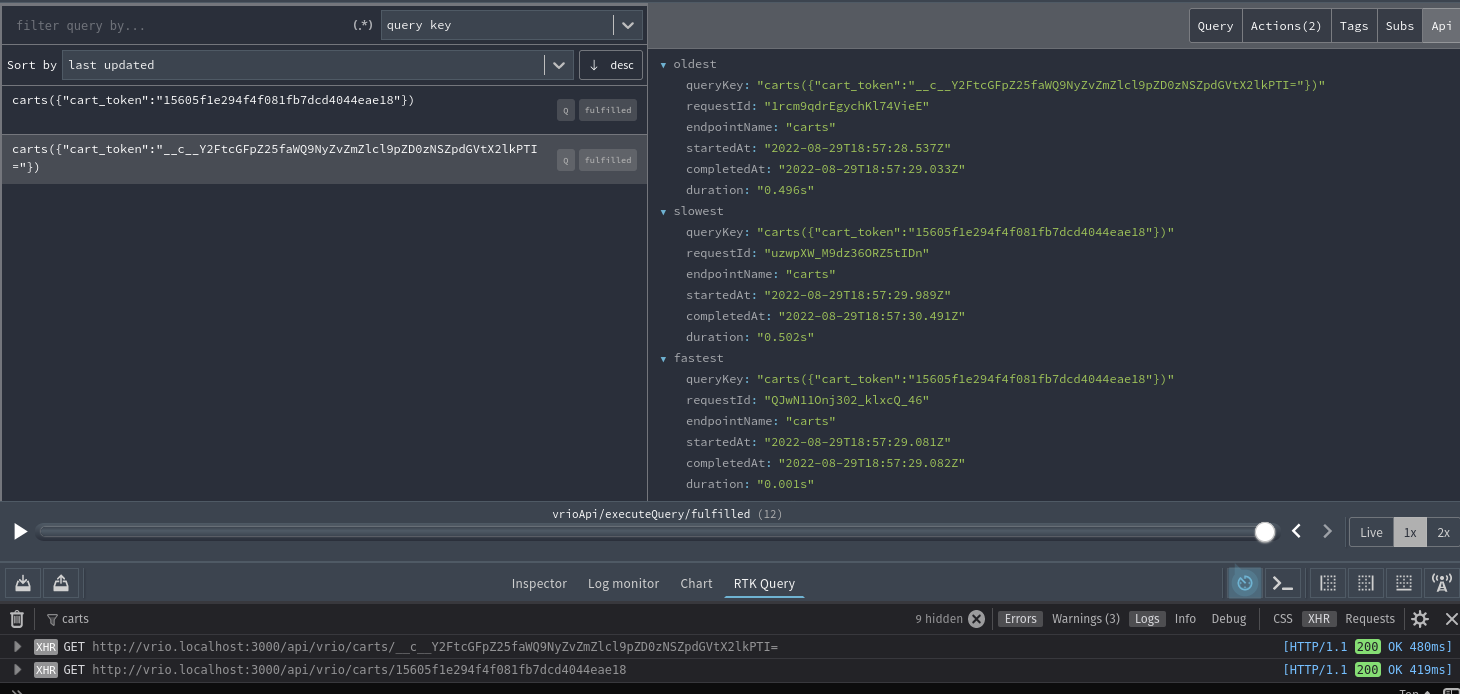
Notice the fastest is still the one we upsert but somehow, it's also the slowest because it hits the API twice, which is evident by the two calls in the console below.
I really can't follow, I'm sorry. Can you try to make a simpler reproduction of what you are getting there?
Sure so check out the following repo for the code (I tried to pare it down as much as possible while maintaining the core functionality that I'm having issues with):
https://github.com/davidrhoderick/testing-upsertQueryData
You can also demo it at https://testing-upsert-query-data.vercel.app/. I tried to make a Codesandbox but this was easier to integrate with Next.js and Redux etc.
I'll look a bit deeper tomorrow, but on first look it just looks like you have a page transition there and after that transition you start with an empty store again.
But tbh., this is also a monster of useEffects. Can you maybe slim that example down to a minimum of code that's actually necessary to showcase what you are seeing?
@phryneas Yea that page transition is probably the issue. I've messed around with the Next.js-Redux SSR wrapper and it was kind of painful. Could Redux Persist be a simpler solution in this case? I think the app could benefit from persisting some amount of data.
Oof you should see the actual app, this is HUGELY pared down! Maybe I'll see if I can reproduce the issue without the lazy query and that should remove a bunch of the useEffects and probably still point to the page transition.
Edit: Code should be updated now. I just pushed to GitHub so it might take a couple minutes for the build to finish.
What's confusing is if the state gets wiped, how come I can still see the previews queries in the Redux Toolkit? Is that just how it records things?