dask-cuda
 dask-cuda copied to clipboard
dask-cuda copied to clipboard
[BUG] LocalCUDACluster doesn't work with NVIDIA MIG
(py)nvml does not appear to be compatible with MIG, which prevents various Dask services from working correctly, for example 'LocalCUDACluster'.
While this isn't explicitly Dask-cuda's fault, the end result is the same. Adding this issue for others to reference, and for discussion of potential work arounds.
from dask_cuda import LocalCUDACluster
from dask.distributed import Client
cluster = LocalCUDACluster(device_memory_limit=1.0, rmm_managed_memory=True)
client = Client(cluster)
---------------------------------------------------------------------------
NVMLError_NoPermission Traceback (most recent call last)
<ipython-input-1-48e0ebf5a2e9> in <module>
33
34
---> 35 cluster = LocalCUDACluster(device_memory_limit=1.0,
36 rmm_managed_memory=True)
37 client = Client(cluster)
/opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/local_cuda_cluster.py in __init__(self, n_workers, threads_per_worker, processes, memory_limit, device_memory_limit, CUDA_VISIBLE_DEVICES, data, local_directory, protocol, enable_tcp_over_ucx, enable_infiniband, enable_nvlink, enable_rdmacm, ucx_net_devices, rmm_pool_size, rmm_managed_memory, jit_unspill, **kwargs)
166 memory_limit, threads_per_worker, n_workers
167 )
--> 168 self.device_memory_limit = parse_device_memory_limit(
169 device_memory_limit, device_index=0
170 )
/opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/utils.py in parse_device_memory_limit(device_memory_limit, device_index)
478 device_memory_limit = float(device_memory_limit)
479 if isinstance(device_memory_limit, float) and device_memory_limit <= 1:
--> 480 return int(get_device_total_memory(device_index) * device_memory_limit)
481
482 if isinstance(device_memory_limit, str):
/opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/utils.py in get_device_total_memory(index)
158 """
159 pynvml.nvmlInit()
--> 160 return pynvml.nvmlDeviceGetMemoryInfo(
161 pynvml.nvmlDeviceGetHandleByIndex(index)
162 ).total
/opt/conda/envs/rapids/lib/python3.8/site-packages/pynvml/nvml.py in nvmlDeviceGetMemoryInfo(handle)
1286 fn = get_func_pointer("nvmlDeviceGetMemoryInfo")
1287 ret = fn(handle, byref(c_memory))
-> 1288 check_return(ret)
1289 return c_memory
1290
/opt/conda/envs/rapids/lib/python3.8/site-packages/pynvml/nvml.py in check_return(ret)
364 def check_return(ret):
365 if (ret != NVML_SUCCESS):
--> 366 raise NVMLError(ret)
367 return ret
368
NVMLError_NoPermission: Insufficient Permissions
Thanks @drobison00 for filing this, indeed we'll have to find a way to work around NVML. I don't know if we have any ways to do so without creating a CUDA context ahead of time, it may be that the only way to do so is forcing the user to specify parameters such as total device memory.
I do not have access to an A100, but the latest (unreleased) version of pynvml should include MIG-supported NVML bindings. I believe we will need to modify get_device_total_memory to optionally pass a MIG device handle when necessary. As a first-order functionality test, someone could try adding a try/except for the current NVMLError and retry with a MIG handle - E.g.:
def get_device_total_memory(index=0):
"""
Return total memory of CUDA device with index
"""
pynvml.nvmlInit()
try:
return pynvml.nvmlDeviceGetMemoryInfo(
pynvml.nvmlDeviceGetHandleByIndex(index)
).total
except pynvml.NVMLError:
return pynvml.nvmlDeviceGetMemoryInfo(
pynvml.nvmlDeviceGetMigDeviceHandleByIndex(index)
).total
Sounds like a good idea @rjzamora . A100s have been very scarce lately, I think we may be able to test that out in a week or two when Selene is open again to general usage.
Made the suggested changes on a GCP a100-mig system and hit the error below; the error spams continuously until the process is killed.
I tried using the latest pynvml from conda, as well as a manual install from source.
>>> client = Client(cluster)tornado.application - ERROR - Exception in callback <bound method SystemMonitor.update of <SystemMonitor: cpu: 16 memory: 315 MB fds: 45>>
Traceback (most recent call last):
File "/root/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/tornado/ioloop.py", line 905, in _run
return self.callback()
File "/root/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/distributed/system_monitor.py", line 96, in update
gpu_extra = nvml.one_time()
File "/root/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/distributed/diagnostics/nvml.py", line 47, in one_time
"memory-total": pynvml.nvmlDeviceGetMemoryInfo(h).total,
File "/root/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/pynvml/nvml.py", line 1984, in nvmlDeviceGetMemoryInfo
_nvmlCheckReturn(ret)
File "/root/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/pynvml/nvml.py", line 743, in _nvmlCheckReturn
raise NVMLError(ret)
pynvml.nvml.NVMLError_NoPermission: Insufficient Permissions
We've ran into perm issues in the past, though MIG things might required something else. Possible solutions are documented here: https://github.com/gpuopenanalytics/pynvml#nvml-permissions
I was able to atleast circumvent the Insufficient Permissions error with the following code:
def get_device_total_memory(index=0, migindex=0):
"""
Return total memory of CUDA device with index
"""
import pynvml
pynvml.nvmlInit()
try:
return pynvml.nvmlDeviceGetMemoryInfo(
pynvml.nvmlDeviceGetHandleByIndex(index)
).total
except pynvml.NVMLError:
return pynvml.nvmlDeviceGetMemoryInfo(
pynvml.nvmlDeviceGetMigDeviceHandleByIndex(device = pynvml.nvmlDeviceGetHandleByIndex(index), index=migindex=0)
).total
However, as I understand from the API, nvmlDeviceGetMigDeviceHandleByIndex function expects both the handle for the parent GPU and an index for the specific MIG device (here I am passing in 0 for the mig device index) . I believe brief modifications in dask-cuda needs to be added in order to pass in the MIG device index as well if we start the LocalCUDACluster with multiple MIG instances?
Yes, the code above is possible now with latest pyNVML. However, I feel that this is still a bit more complicated to handle, Dask-CUDA now needs to know which devices are MIG devices and which ones are not. Presently, it only relies upon CUDA_VISIBLE_DEVICES which is automatically defined as list(range(pynvml.nvmlDeviceGetCount())), and to be honest I haven't had the chance to work with MIG yet and don't know exactly what happens when you have MIG devices available, are they treated just as one more device? For example, imagine there's a system with 2 GPUs configured as follows:
- GPU 0; ** MIG 0; ** MIG 1;
- GPU 1.
In the case above, will there 3 indices that can be passed to CUDA_VISIBLE_DEVICES, where 0->GPU 0 MIG 0, 1->GPU 0 MIG 1, 2->GPU 1? And if so, are we able to reliably identify which ones are MIG and which are just regular devices?
I tested a few things. I have used a VM on AWS which has 8 A100 GPUs. I enabled MIG on GPU 0 and divided that into 7 5GB instances.
MIG instances configuration.
ubuntu@ip-172-31-48-89:~$ sudo nvidia-smi -mig 1 -i 0
Enabled MIG Mode for GPU 00000000:10:1C.0
All done.
ubuntu@ip-172-31-48-89:~$ sudo nvidia-smi mig -cgi 19,19,19,19,19,19,19 -i 0
Successfully created GPU instance ID 9 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 7 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 8 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 11 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 12 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 13 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 14 on GPU 0 using profile MIG 1g.5gb (ID 19)
ubuntu@ip-172-31-48-89:~$ sudo nvidia-smi mig -i 0 -cci -gi 7,8,9,11,12,13,14
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 7 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 8 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 9 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 11 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 12 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 13 using profile MIG 1g.5gb (ID 0)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 14 using profile MIG 1g.5gb (ID 0)
ubuntu@ip-172-31-48-89:~$
ubuntu@ip-172-31-48-89:~$ nvidia-smi
Mon Jul 12 22:17:40 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.119.03 Driver Version: 450.119.03 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB On | 00000000:10:1C.0 Off | On |
| N/A 40C P0 47W / 400W | 102MiB / 40537MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
| 1 A100-SXM4-40GB On | 00000000:10:1D.0 Off | 0 |
| N/A 40C P0 56W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 A100-SXM4-40GB On | 00000000:20:1C.0 Off | 0 |
| N/A 41C P0 57W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 A100-SXM4-40GB On | 00000000:20:1D.0 Off | 0 |
| N/A 37C P0 51W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 A100-SXM4-40GB On | 00000000:90:1C.0 Off | 0 |
| N/A 40C P0 55W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 A100-SXM4-40GB On | 00000000:90:1D.0 Off | 0 |
| N/A 37C P0 52W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 A100-SXM4-40GB On | 00000000:A0:1C.0 Off | 0 |
| N/A 42C P0 55W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 A100-SXM4-40GB On | 00000000:A0:1D.0 Off | 0 |
| N/A 40C P0 59W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 7 0 0 | 80MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 4MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 8 0 1 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 9 0 2 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 11 0 3 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 12 0 4 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 13 0 5 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 14 0 6 | 3MiB / 4864MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 8191MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 7 0 5239 C ...s/rapids-21.06/bin/python 73MiB |
+-----------------------------------------------------------------------------+
Some of the tests are done on a notebook running on bare VM. For other tests, I am using the rapids 21.06 docker container where I restrict which GPUs the container can see using the --gpus flag. I will describe the setup appropriately as needed.
Observations:
-
Currently,
LocalCUDAClusterrequiresCUDA_VISIBLE_DEVICESargument to haveMIG-GPU-prefix if we want to specify MIG instances: https://github.com/rapidsai/dask-cuda/blob/branch-21.08/dask_cuda/utils.py#L467 . Non MIG gpus can be specified via integers or with a prefixGPU-. -
LocalCUDAClusterfails when I try to use MIG instances by specifying the MIG enabled GPU by its indexCUDA_VISIBLE_DEVICES="0". This is directly on the VM.Expand to see Error Details.
from dask.distributed import Client, wait from dask_cuda import LocalCUDACluster cluster = LocalCUDACluster(CUDA_VISIBLE_DEVICES="0") cluster --------------------------------------------------------------------------- tornado.application - ERROR - Exception in callback <bound method SystemMonitor.update of <SystemMonitor: cpu: 15 memory: 306 MB fds: 53>> Traceback (most recent call last): File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/tornado/ioloop.py", line 905, in _run return self.callback() File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/distributed/system_monitor.py", line 99, in update gpu_metrics = nvml.real_time() File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/distributed/diagnostics/nvml.py", line 38, in real_time "utilization": pynvml.nvmlDeviceGetUtilizationRates(h).gpu, File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/pynvml/nvml.py", line 2058, in nvmlDeviceGetUtilizationRates _nvmlCheckReturn(ret) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/pynvml/nvml.py", line 743, in _nvmlCheckReturn raise NVMLError(ret) pynvml.nvml.NVMLError_NotSupported: Not Supported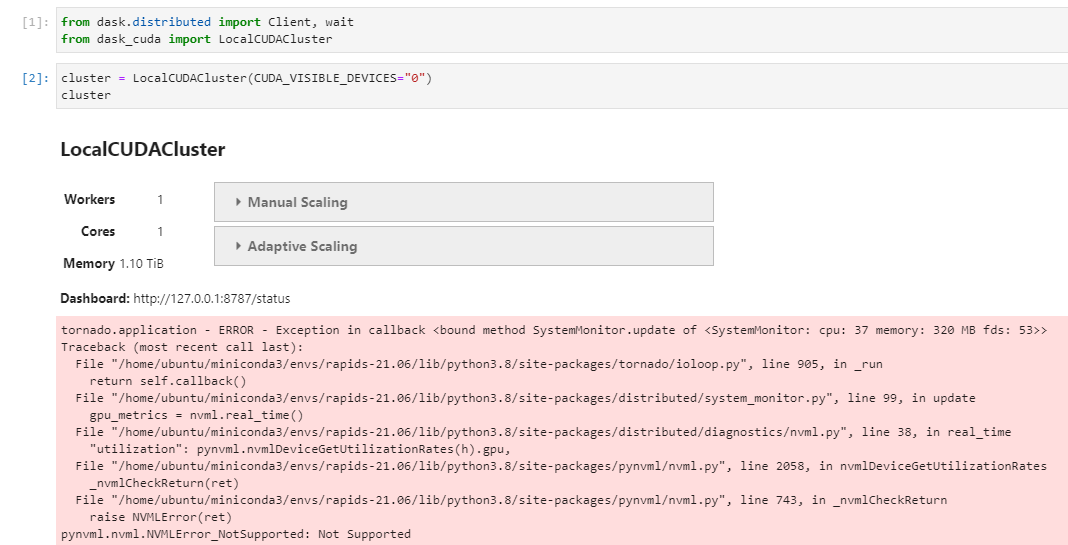
Note: If we test the same by attaching GPU 0 by index to a docker container via :
docker run --gpus '"device=0"' --rm -it rapidsai/rapidsai:21.06-cuda11.0-runtime-ubuntu18.04-py3.8we get the same error as in the next bullet point. -
LocalCUDAClusterfails when I try to use MIG instances from inside a docker container (a case similar to when we run things with GKE or EKS). I start the docker container withdocker run --gpus '"device=0:0,0:1,0:2"' --rm -it rapidsai/rapidsai:21.06-cuda11.0-runtime-ubuntu18.04-py3.8to allow the container to see only the 1st, 2nd and 3rd MIG instance of GPU 0.Expand to see Error Details.
from dask.distributed import Client, wait from dask_cuda import LocalCUDACluster cluster = LocalCUDACluster(CUDA_VISIBLE_DEVICES="MIG-GPU-0:0,MIG-GPU-0:1,MIG-GPU-0:2") cluster --------------------------------------------------------------------------- NVMLError_NoPermission Traceback (most recent call last) <ipython-input-2-7a3566f39e2f> in <module> ----> 1 cluster = (CUDA_VISIBLE_DEVICES="MIG-GPU-0:0,MIG-GPU-0:1,MIG-GPU-0:2") 2 cluster /opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/local_cuda_cluster.py in __init__(self, CUDA_VISIBLE_DEVICES, n_workers, threads_per_worker, memory_limit, device_memory_limit, data, local_directory, protocol, enable_tcp_over_ucx, enable_infiniband, enable_nvlink, enable_rdmacm, ucx_net_devices, rmm_pool_size, rmm_managed_memory, rmm_async, rmm_log_directory, jit_unspill, log_spilling, **kwargs) 214 memory_limit, threads_per_worker, n_workers 215 ) --> 216 self.device_memory_limit = parse_device_memory_limit( 217 device_memory_limit, device_index=0 218 ) /opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/utils.py in parse_device_memory_limit(device_memory_limit, device_index) 525 device_memory_limit = float(device_memory_limit) 526 if isinstance(device_memory_limit, float) and device_memory_limit <= 1: --> 527 return int(get_device_total_memory(device_index) * device_memory_limit) 528 529 if isinstance(device_memory_limit, str): /opt/conda/envs/rapids/lib/python3.8/site-packages/dask_cuda/utils.py in get_device_total_memory(index) 185 """ 186 pynvml.nvmlInit() --> 187 return pynvml.nvmlDeviceGetMemoryInfo( 188 pynvml.nvmlDeviceGetHandleByIndex(index) 189 ).total /opt/conda/envs/rapids/lib/python3.8/site-packages/pynvml/nvml.py in nvmlDeviceGetMemoryInfo(handle) 1982 fn = _nvmlGetFunctionPointer("nvmlDeviceGetMemoryInfo") 1983 ret = fn(handle, byref(c_memory)) -> 1984 _nvmlCheckReturn(ret) 1985 return c_memory 1986 /opt/conda/envs/rapids/lib/python3.8/site-packages/pynvml/nvml.py in _nvmlCheckReturn(ret) 741 def _nvmlCheckReturn(ret): 742 if (ret != NVML_SUCCESS): --> 743 raise NVMLError(ret) 744 return ret 745 NVMLError_NoPermission: Insufficient Permissions
This error goes away if I made the changes mentioned in https://github.com/rapidsai/dask-cuda/issues/583#issuecomment-878349249 in
nvmlDeviceGetMemoryInfo. ButnvmlDeviceGetMemoryInfoneeds both the handle of the parent GPU and the MIG instance index. These are not passed in correctly at the moment however we are not getting thepermissionserror. Hence we will need to handle these changes indask-cudacode.Expand to see Image.

-
LocalCUDAClusterfails when I try to use MIG instances from directly without docker, but with a different error if I useCUDA_VISIBLE_DEVICEStto denote the MIG instances. Need to investigate further.Expand to see Error Details.
from dask.distributed import Client, wait from dask_cuda import LocalCUDACluster cluster = LocalCUDACluster(CUDA_VISIBLE_DEVICES="MIG-GPU-0:0,MIG-GPU-0:1,MIG-GPU-0:2") cluster --------------------------------------------------------------------------- Unable to start CUDA Context Traceback (most recent call last): File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 237, in initialize self.cuInit(0) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 300, in safe_cuda_api_call self._check_error(fname, retcode) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 335, in _check_error raise CudaAPIError(retcode, msg) numba.cuda.cudadrv.driver.CudaAPIError: [100] Call to cuInit results in CUDA_ERROR_NO_DEVICE During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/dask_cuda/initialize.py", line 142, in dask_setup numba.cuda.current_context() File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 212, in get_context return _runtime.get_or_create_context(devnum) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 138, in get_or_create_context return self._get_or_create_context_uncached(devnum) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 151, in _get_or_create_context_uncached with driver.get_active_context() as ac: File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 393, in __enter__ driver.cuCtxGetCurrent(byref(hctx)) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 280, in __getattr__ self.initialize() File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 240, in initialize raise CudaSupportError("Error at driver init: \n%s:" % e) numba.cuda.cudadrv.error.CudaSupportError: Error at driver init: [100] Call to cuInit results in CUDA_ERROR_NO_DEVICE: Unable to start CUDA Context Traceback (most recent call last): File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 237, in initialize self.cuInit(0) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 300, in safe_cuda_api_call self._check_error(fname, retcode) File "/home/ubuntu/miniconda3/envs/rapids-21.06/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 335, in _check_error raise CudaAPIError(retcode, msg) numba.cuda.cudadrv.driver.CudaAPIError: [100] Call to cuInit results in CUDA_ERROR_NO_DEVICE
-
LocalCUDAClustersucceeds if I try to use non-MIG instances from directly with/without docker.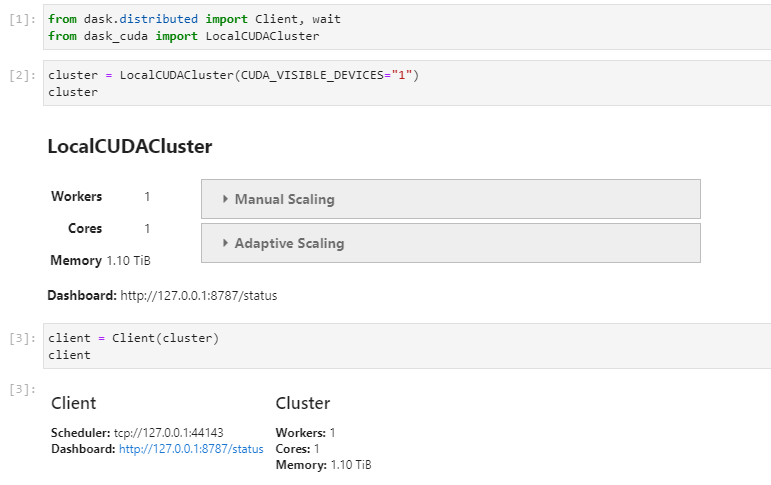
Based on these pocs, there appear to be some existing discrepancies. We think that we need to first properly identify what type of device each device is in CUDA_VISIBLE_DEVICES. Once we do that, we then need to query the GPUs with the right NVML call via right pynvml api in several places such as get_cpu_affinity, get_device_total_memory, etc.
Action Plan after discussion with @pentschev :
-
Firstly mapping the MIG counterparts for the
pynvmlapi we use indask_cuda/utils.py. We should be able to write ais_mig_deviceutils function which will parse a device index and return whether it is a MIG device or not. This can be subsequently used inget_cpu_affinity,get_device_total_memoryto use the correctpynvmlapis. -
Secondly, add more user-friendly error when trying to start a CUDA worker on a MIG-enabled device. See error 2 above.
-
Thirdly, add handling of default Dask-CUDA setup when we use a hybrid deployment of MIG enabled and disabled GPUs. Suppose we have a deployment where user wants to have the following configuration:
- GPU 0: (MIG enabled)
- MIG 0
- MIG 1
- GPU1 (MIG not enabled)
Three possible solution approaches are applicable in such a scenario: a. We rely on the default behavior and create workers only on the non-MIG devices and just create MIG devices when explicitly specified via
CUDA_VISIBLE_DEVICESb. Add a new argument--migthat will create workers using all MIG devices (and ignore the non MIG ones), where the default behavior (when--migis NOT specified) would be to create workers on all non-MIG devices. c. Create 3 workers with 3 completely different memory sizes and characteristics. Generally a bad idea.This perhaps need much more discussion before we do something.
- GPU 0: (MIG enabled)
This issue has been labeled inactive-90d due to no recent activity in the past 90 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.
Based on https://github.com/rapidsai/dask-cuda/pull/674 , it sounds like this may have been resolved. Is this still an issue, or can it be closed?
I believe this can be closed. @pentschev can attest please?
On Thu, Jan 6, 2022, 10:36 AM Nick Becker @.***> wrote:
Based on #674 https://github.com/rapidsai/dask-cuda/pull/674 , it sounds like this may have been resolved. Is this still an issue, or can it be closed?
— Reply to this email directly, view it on GitHub https://github.com/rapidsai/dask-cuda/issues/583#issuecomment-1006686194, or unsubscribe https://github.com/notifications/unsubscribe-auth/AFH6YA42S4SO5FUEACLBU6LUUWZHNANCNFSM43GU4X4A . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
You are receiving this because you are subscribed to this thread.Message ID: @.***>
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.
@pentschev are we ok to close this? Sounds like yes from the conversation above, but please let us know if something is still missing here
I think we want to keep it open still because not all parts of the action plan in https://github.com/rapidsai/dask-cuda/issues/583#issuecomment-878675364 were done. It would be good to have them addressed at some point if it really becomes a priority and someone has bandwidth to work on those.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.
We're still seeing this issue when running the latest Merlin image (nvcr.io/nvidia/merlin/merlin-pytorch:22.06), which includes CUDA 11.7, dask-cuda==22.04, and pynvml==11.4.1. Happens on both driver 515.48.07 and 510.47.03 if that makes any difference.
In [1]: from dask_cuda import LocalCUDACluster
In [2]: cluster = LocalCUDACluster("MIG-e65035fb-733c-5aeb-9a88-e20f5f0cb0b5")
---------------------------------------------------------------------------
NVMLError_NoPermission Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 cluster = LocalCUDACluster("MIG-e65035fb-733c-5aeb-9a88-e20f5f0cb0b5")
File /usr/local/lib/python3.8/dist-packages/dask_cuda/local_cuda_cluster.py:337, in LocalCUDACluster.__init__(self, CUDA_VISIBLE_DEVICES, n_workers, threads_per_worker, memory_limit, device_memory_limit, data, local_directory, shared_filesystem, protocol, enable_tcp_over_ucx, enable_infiniband, enable_nvlink, enable_rdmacm, rmm_pool_size, rmm_maximum_pool_size, rmm_managed_memory, rmm_async, rmm_log_directory, rmm_track_allocations, jit_unspill, log_spilling, worker_class, pre_import, **kwargs)
330 worker_class = partial(
331 LoggedNanny if log_spilling is True else Nanny,
332 worker_class=worker_class,
333 )
335 self.pre_import = pre_import
--> 337 super().__init__(
338 n_workers=0,
339 threads_per_worker=threads_per_worker,
340 memory_limit=self.memory_limit,
341 processes=True,
342 data=data,
343 local_directory=local_directory,
344 protocol=protocol,
345 worker_class=worker_class,
346 config={
347 "distributed.comm.ucx": get_ucx_config(
348 enable_tcp_over_ucx=enable_tcp_over_ucx,
349 enable_nvlink=enable_nvlink,
350 enable_infiniband=enable_infiniband,
351 enable_rdmacm=enable_rdmacm,
352 )
353 },
354 **kwargs,
355 )
357 self.new_spec["options"]["preload"] = self.new_spec["options"].get(
358 "preload", []
359 ) + ["dask_cuda.initialize"]
360 self.new_spec["options"]["preload_argv"] = self.new_spec["options"].get(
361 "preload_argv", []
362 ) + ["--create-cuda-context"]
File /usr/local/lib/python3.8/dist-packages/distributed/deploy/local.py:236, in LocalCluster.__init__(self, name, n_workers, threads_per_worker, processes, loop, start, host, ip, scheduler_port, silence_logs, dashboard_address, worker_dashboard_address, diagnostics_port, services, worker_services, service_kwargs, asynchronous, security, protocol, blocked_handlers, interface, worker_class, scheduler_kwargs, scheduler_sync_interval, **worker_kwargs)
233 worker = {"cls": worker_class, "options": worker_kwargs}
234 workers = {i: worker for i in range(n_workers)}
--> 236 super().__init__(
237 name=name,
238 scheduler=scheduler,
239 workers=workers,
240 worker=worker,
241 loop=loop,
242 asynchronous=asynchronous,
243 silence_logs=silence_logs,
244 security=security,
245 scheduler_sync_interval=scheduler_sync_interval,
246 )
File /usr/local/lib/python3.8/dist-packages/distributed/deploy/spec.py:260, in SpecCluster.__init__(self, workers, scheduler, worker, asynchronous, loop, security, silence_logs, name, shutdown_on_close, scheduler_sync_interval)
258 if not self.asynchronous:
259 self._loop_runner.start()
--> 260 self.sync(self._start)
261 try:
262 self.sync(self._correct_state)
File /usr/local/lib/python3.8/dist-packages/distributed/utils.py:309, in SyncMethodMixin.sync(self, func, asynchronous, callback_timeout, *args, **kwargs)
307 return future
308 else:
--> 309 return sync(
310 self.loop, func, *args, callback_timeout=callback_timeout, **kwargs
311 )
File /usr/local/lib/python3.8/dist-packages/distributed/utils.py:376, in sync(loop, func, callback_timeout, *args, **kwargs)
374 if error:
375 typ, exc, tb = error
--> 376 raise exc.with_traceback(tb)
377 else:
378 return result
File /usr/local/lib/python3.8/dist-packages/distributed/utils.py:349, in sync.<locals>.f()
347 future = asyncio.wait_for(future, callback_timeout)
348 future = asyncio.ensure_future(future)
--> 349 result = yield future
350 except Exception:
351 error = sys.exc_info()
File /usr/local/lib/python3.8/dist-packages/tornado/gen.py:762, in Runner.run(self)
759 exc_info = None
761 try:
--> 762 value = future.result()
763 except Exception:
764 exc_info = sys.exc_info()
File /usr/local/lib/python3.8/dist-packages/distributed/deploy/spec.py:292, in SpecCluster._start(self)
290 if isinstance(cls, str):
291 cls = import_term(cls)
--> 292 self.scheduler = cls(**self.scheduler_spec.get("options", {}))
293 self.scheduler = await self.scheduler
294 self.scheduler_comm = rpc(
295 getattr(self.scheduler, "external_address", None) or self.scheduler.address,
296 connection_args=self.security.get_connection_args("client"),
297 )
File /usr/local/lib/python3.8/dist-packages/distributed/scheduler.py:3983, in Scheduler.__init__(self, loop, delete_interval, synchronize_worker_interval, services, service_kwargs, allowed_failures, extensions, validate, scheduler_file, security, worker_ttl, idle_timeout, interface, host, port, protocol, dashboard_address, dashboard, http_prefix, preload, preload_argv, plugins, **kwargs)
3924 self.handlers = {
3925 "register-client": self.add_client,
3926 "scatter": self.scatter,
(...)
3978 "dump_cluster_state_to_url": self.dump_cluster_state_to_url,
3979 }
3981 connection_limit = get_fileno_limit() / 2
-> 3983 super().__init__(
3984 # Arguments to SchedulerState
3985 aliases=aliases,
3986 clients=clients,
3987 workers=workers,
3988 host_info=host_info,
3989 resources=resources,
3990 tasks=tasks,
3991 unrunnable=unrunnable,
3992 validate=validate,
3993 plugins=plugins,
3994 # Arguments to ServerNode
3995 handlers=self.handlers,
3996 stream_handlers=merge(worker_handlers, client_handlers),
3997 io_loop=self.loop,
3998 connection_limit=connection_limit,
3999 deserialize=False,
4000 connection_args=self.connection_args,
4001 **kwargs,
4002 )
4004 if self.worker_ttl:
4005 pc = PeriodicCallback(self.check_worker_ttl, self.worker_ttl * 1000)
File /usr/local/lib/python3.8/dist-packages/distributed/scheduler.py:2105, in SchedulerState.__init__(self, aliases, clients, workers, host_info, resources, tasks, unrunnable, validate, plugins, **kwargs)
2102 self._transition_counter = 0
2104 # Call Server.__init__()
-> 2105 super().__init__(**kwargs)
File /usr/local/lib/python3.8/dist-packages/distributed/core.py:191, in Server.__init__(self, handlers, blocked_handlers, stream_handlers, connection_limit, deserialize, serializers, deserializers, connection_args, timeout, io_loop)
189 self._comms = {}
190 self.deserialize = deserialize
--> 191 self.monitor = SystemMonitor()
192 self.counters = None
193 self.digests = None
File /usr/local/lib/python3.8/dist-packages/distributed/system_monitor.py:59, in SystemMonitor.__init__(self, n)
56 self.quantities["num_fds"] = self.num_fds
58 if nvml.device_get_count() > 0:
---> 59 gpu_extra = nvml.one_time()
60 self.gpu_name = gpu_extra["name"]
61 self.gpu_memory_total = gpu_extra["memory-total"]
File /usr/local/lib/python3.8/dist-packages/distributed/diagnostics/nvml.py:139, in one_time()
136 def one_time():
137 h = _pynvml_handles()
138 return {
--> 139 "memory-total": _get_memory_total(h),
140 "name": _get_name(h),
141 }
File /usr/local/lib/python3.8/dist-packages/distributed/diagnostics/nvml.py:116, in _get_memory_total(h)
114 def _get_memory_total(h):
115 try:
--> 116 return pynvml.nvmlDeviceGetMemoryInfo(h).total
117 except pynvml.NVMLError_NotSupported:
118 return None
File /usr/local/lib/python3.8/dist-packages/pynvml/nvml.py:2063, in nvmlDeviceGetMemoryInfo(handle)
2061 fn = _nvmlGetFunctionPointer("nvmlDeviceGetMemoryInfo")
2062 ret = fn(handle, byref(c_memory))
-> 2063 _nvmlCheckReturn(ret)
2064 return c_memory
File /usr/local/lib/python3.8/dist-packages/pynvml/nvml.py:765, in _nvmlCheckReturn(ret)
763 def _nvmlCheckReturn(ret):
764 if (ret != NVML_SUCCESS):
--> 765 raise NVMLError(ret)
766 return ret
NVMLError_NoPermission: Insufficient Permissions
@neggert this error seems to be coming from the Dask dashboard. I think that was really never tested with the most recent additions, and indeed the NVML diagnostics in Dask dashboard will not work with MIG currently. However, you may be able to disable it with:
with dask.config.set({"distributed.diagnostics.nvml": False}):
cluster = LocalCUDACluster(CUDA_VISIBLE_DEVICES="MIG-<uuid>")
That didn't work, but setting the environment variable export DASK_DISTRIBUTED__DIAGNOSTICS__NVML=False did. Thanks for pointing me in the right direction.
That didn't work, but setting the environment variable
export DASK_DISTRIBUTED__DIAGNOSTICS__NVML=Falsedid. Thanks for pointing me in the right direction.
This usually indicates a bug in the way dask config options are handled at import time. In this case it is because importing distributed runs distributed.diagnostics.nvml.device_get_count() which initialises nvml before the config option as suggested by @pentschev can be set.
In fact, even if this is fixed there's another pitfall that the following:
with dask.config.set({"distributed.diagnostics.nvml": False}):
cluster = LocalCUDACluster("MIG-...")
do_stuff_with_cluster(cluster)
may well later try to initialise nvml as well again, since the "once-only" initialisation is not actually once-only if the first initialisation took place with nvml diagnostics switched off. Given the name, one might expect that init_once only runs initialisation and makes a decision the first time it is called, but:
export DASK_DISTRIBUTED__DIAGNOSTICS__NVML=False
In [1]: import dask
In [2]: from distributed.diagnostics import nvml
In [3]: nvml.nvmlInitialized
Out[3]: False
In [4]: nvml.init_once()
In [5]: nvml.nvmlInitialized
Out[5]: False
In [6]: with dask.config.set({"distributed.diagnostics.nvml": True}):
...: nvml.init_once()
...:
In [7]: nvml.nvmlInitialized
Out[7]: True # Huh?
I'll try and find some time to handle this properly in distributed.
Good catch @wence- , it seems this is a problem in https://github.com/dask/distributed/blob/75f4635b05034eba890c90d2f829c3672f59e017/distributed/diagnostics/nvml.py#L32-L34 , where one could indeed set to True later on and initialize, even if the first time that was False.
For a bit of context, the problem there is that there are so many different ways NVML may fail for different setups (e.g., pynvml is installed but not the NVIDIA driver, or both are installed but there are no GPUs on the system, etc.) that is hard to make sure that it works everywhere, and now MIG is a whole new issue by itself (which is why it isn't currently supported). Over the past year or so we had that code path changed probably a dozen times -- mostly to cover WSL2 cases -- but it is impossible to realistically test it for all combinations, and thus issues like this may be introduced from time to time.
I'll try and find some time to handle this properly in distributed.
dask/distributed#6678
Please pardon my ignorance, but am I seeing the same (or similar) thing here:
Unable to start CUDA Context
Traceback (most recent call last):
File "/home/perth/w47686/.conda/envs/rapids/lib/python3.9/site-packages/dask_cuda/initialize.py", line 31, in _create_cuda_context
distributed.comm.ucx.init_once()
File "/home/perth/w47686/.conda/envs/rapids/lib/python3.9/site-packages/distributed/comm/ucx.py", line 104, in init_once
cuda_visible_device = int(
ValueError: invalid literal for int() with base 10: 'MIG-41518e05-dfc8-5485-a5f7-8948b6c213a4'
This is with dask_cuda=22.06.00, pynvml=11.4.1, and distributed=2022.05.2.
@hendeb the error you're seeing is different, it's coming from Dask-CUDA, and thus not the Dask scheduler. Could you post also how you're starting up the cluster and a minimal reproducer of the client code?
OK, thanks for taking the time to reply, @pentschev. I am starting up the cluster as per:

This is using MIG devices created on a pair of A100s:
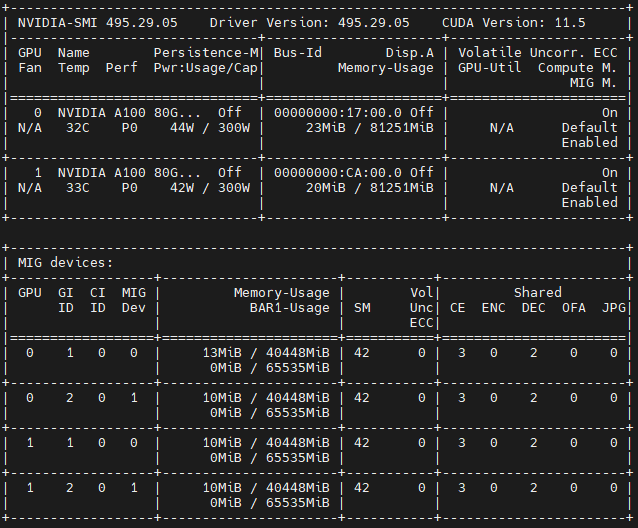
@hendeb I think the issues should be fixed by https://github.com/dask/distributed/pull/6720 and https://github.com/rapidsai/dask-cuda/pull/950 . If you have the chance, could you try both PRs and report back? Please note that you'll need to switch to RAPIDS 22.08 nightly builds, and then install those two PRs from source.
Apologies for the slow reply, @pentschev, and thank you for your help. Using RAPIDS 22.08 nightly build with PRs dask/distributed#6720 and rapidsai/dask-cuda#950 seems to be OK:

Something to maybe note is that the A100 driver used here has been updated since my last post (from 495.29.05 to 515.48.07).
The newer driver version should be ok. Thanks @hendeb for confirming that it worked.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.