Handle tail call optimization
It appears function boundaries are a bit off when tail call optimization is used. For instance:
cat <<EOF > main.c
void foo(void);
int main()
{
foo();
return 0;
}
EOF
cat <<EOF > foo.c
void bar(void);
void foo()
{
bar();
}
EOF
cat <<EOF > bar.c
void bar()
{
}
EOF
gcc -m32 -O2 main.c foo.c bar.c
r2 -A a.out -qc "pdf @sym.foo"
...yields:
╒ (fcn) sym.foo 16
│ ; CALL XREF from 0x08048301 (sym.foo)
│ ┌─< 0x08048410 e90b000000 jmp sym.bar
│ │ 0x08048415 6690 nop
│ │ 0x08048417 6690 nop
│ │ 0x08048419 6690 nop
│ │ 0x0804841b 6690 nop
│ │ 0x0804841d 6690 nop
╘ │ 0x0804841f 90 nop
e anal.eobjmp=true
On 08 Mar 2016, at 03:30, Ido Yariv [email protected] wrote:
It appears function boundaries are a bit off when tail call optimization is used. For instance:
cat <<EOF > main.c void foo(void);
int main() { foo(); return 0; } EOF
cat <<EOF > foo.c void bar(void);
void foo() { bar(); } EOF
cat <<EOF > bar.c void bar() { } EOF
gcc -m32 -O2 main.c foo.c bar.c r2 -A a.out -qc "pdf @sym.foo" ...yields:
╒ (fcn) sym.foo 16 │ ; CALL XREF from 0x08048301 (sym.foo) │ ┌─< 0x08048410 e90b000000 jmp sym.bar │ │ 0x08048415 6690 nop │ │ 0x08048417 6690 nop │ │ 0x08048419 6690 nop │ │ 0x0804841b 6690 nop │ │ 0x0804841d 6690 nop ╘ │ 0x0804841f 90 nop — Reply to this email directly or view it on GitHub https://github.com/radare/radare2/issues/4258.
This indeed seems to solve this, thanks! Any reason this shouldn't be true by default?
Because this is not probably the right solution. Indeed you will see that functions will now be terminated as soon as you meet a jmp... I don't think anal.eobjmp really fixes the issue, because it creates many more problems.
eobjmp doesnt exactly means that the funciton terminates on any jump. it must have some kind of conditions.. i know that this creates problems, because it is not easy to handle all sistuations in a generic way, did you spot any case where this is not working fine? we should have tests for this :3
On 08 Mar 2016, at 11:17, Riccardo Schirone [email protected] wrote:
Because this is not probably the right solution. Indeed you will see that functions will now be terminated as soon as you meet a jmp... I don't think anal.eobjmp really fixes the issue, because it creates many more problems.
— Reply to this email directly or view it on GitHub https://github.com/radare/radare2/issues/4258#issuecomment-193705822.
Yes, a lot. This is /bin/cat for example:
╒ (fcn) entry0 60
│ 0x100001540 55 push rbp
│ 0x100001541 4889e5 mov rbp, rsp
│ 0x100001544 4157 push r15
│ 0x100001546 4156 push r14
│ 0x100001548 4155 push r13
│ 0x10000154a 4154 push r12
│ 0x10000154c 53 push rbx
│ 0x10000154d 50 push rax
│ 0x10000154e 4889f3 mov rbx, rsi
│ 0x100001551 4189fe mov r14d, edi
│ 0x100001554 488d35f50900. lea rsi, section.4.__cstring
│ 0x10000155b bf02000000 mov edi, 2
│ 0x100001560 e80b080000 call sym.imp.setlocale ;[1]
│ 0x100001565 4c8d3de50900. lea r15, str.benstuv
│ 0x10000156c 4c8d2d610100. lea r13, 0x1000016d4
│ 0x100001573 4c8b25b60a00. mov r12, qword [reloc.__stdoutp_48]
╘ ┌──< 0x10000157a eb14 jmp 0x100001590 ;[2]
┌────> 0x10000157c c705ca0b0000. mov dword [0x100002150], 1
│ │ 0x100001586 c705b00b0000. mov dword [section.11.__common], 1
───└──> 0x100001590 4489f7 mov edi, r14d
│ 0x100001593 4889de mov rsi, rbx
I also found out some time ago that there are BasicBlocks that do not belong to any function. As always, I think RAnal needs a lot of love!
All yours if you are in the mood :D
On 09 Mar 2016, at 11:04, Riccardo Schirone [email protected] wrote:
Yes, a lot. This is /bin/cat for example:
╒ (fcn) entry0 60 │ 0x100001540 55 push rbp │ 0x100001541 4889e5 mov rbp, rsp │ 0x100001544 4157 push r15 │ 0x100001546 4156 push r14 │ 0x100001548 4155 push r13 │ 0x10000154a 4154 push r12 │ 0x10000154c 53 push rbx │ 0x10000154d 50 push rax │ 0x10000154e 4889f3 mov rbx, rsi │ 0x100001551 4189fe mov r14d, edi │ 0x100001554 488d35f50900. lea rsi, section.4.__cstring │ 0x10000155b bf02000000 mov edi, 2 │ 0x100001560 e80b080000 call sym.imp.setlocale ;[1] │ 0x100001565 4c8d3de50900. lea r15, str.benstuv │ 0x10000156c 4c8d2d610100. lea r13, 0x1000016d4 │ 0x100001573 4c8b25b60a00. mov r12, qword [reloc.__stdoutp_48] ╘ ┌──< 0x10000157a eb14 jmp 0x100001590 ;[2] ┌────> 0x10000157c c705ca0b0000. mov dword [0x100002150], 1 │ │ 0x100001586 c705b00b0000. mov dword [section.11.__common], 1 ───└──> 0x100001590 4489f7 mov edi, r14d │ 0x100001593 4889de mov rsi, rbx I also found out some time ago that there are BasicBlocks that do not belong to any function. As always, I think RAnal needs a lot of love!
— Reply to this email directly or view it on GitHub.
Which condition can we assume when considering a tail continuation or not? Do you have more examples?
For the PLT we can asume that a JMP is EOB when it points to a UJMP. can someone work a PR on this to see how much tests are broken and how many fixed?
I would assume that when there is a jump, the next block is always part of the current function (unless it is already part of another function). If during analysis you find out that one of those basic blocks is actually the start of another function, you could split the functions.
What if theres data? Or just analize a single function?
Imho the approach would be to see if any branch in the current analyzed part theres a jump after that jmpback if not just end the function there
On 04 May 2016, at 20:45, Riccardo Schirone [email protected] wrote:
I would assume that when there is a jump, the next block is always part of the current function (unless it is already part of another function). If during analysis you find out that one of those basic blocks is actually the start of another function, you could split the functions.
— You are receiving this because you commented. Reply to this email directly or view it on GitHub
If there is a direct jump to an address, there can't be data there (unless of course we are talking about obfuscated binaries, but then if we assume that, we may fail in thousands of ways). An address reachable through a direct jump is always part of the current function IMO. You can say there is a tail recursion optimisation only when, later, you find out that there is a call to one of the basic block or there is a function symbol there or you have other strong assumptions that make you think there is a function there.
For example:
┌──< 0x00000000 eb0a jmp 0xc
│ 0x00000002 0000 add byte [rax], al
│ 0x00000004 0000 add byte [rax], al
│ 0x00000006 0000 add byte [rax], al
│ 0x00000008 0000 add byte [rax], al
│ 0x0000000a 0000 add byte [rax], al
└──> 0x0000000c 55 push rbp
0x0000000d 53 push rbx
0x0000000e b800000000 mov eax, 0
0x00000013 5b pop rbx
0x00000014 5d pop rbp
0x00000015 c3 ret
In this case there is nothing, IMO, that can make you think that @ 0 there is a tail-recursion optimisation. So there should be just one function starting at 0, with two basic blocks (one starting at 0 and one starting at 0xc).
Instead, if we consider this code with a small change:
┌──< 0x00000000 eb0a jmp 0xc
│ 0x00000002 0000 add byte [rax], al
│ 0x00000004 0000 add byte [rax], al
│ 0x00000006 0000 add byte [rax], al
│ 0x00000008 0000 add byte [rax], al
│ 0x0000000a 0000 add byte [rax], al
└──> 0x0000000c 55 push rbp
0x0000000d 53 push rbx
0x0000000e b800000000 mov eax, 0
0x00000013 5b pop rbx
0x00000014 5d pop rbp
0x00000015 c3 ret
0x00000016 0000 add byte [rax], al
;-- myfunction:
0x00000018 55 push rbp
0x00000019 e8eeffffff call 0xc
0x0000001e 5d pop rbp
0x0000001f c3 ret
We have 3 functions: one at 0 with only one basic block that jumps outside the function, one at 0xc and another one at 0x18. When you start analysing the function @ 0, there isn't anything that tells you that the jump instruction is actually the result of a tail-call optimisation, so you have to consider the basic block @ 0xc as part of the function @ 0. Only later, when you analyse myfunction you find out that there is a call to a basic block that is not the entry point of the relative function and so, you can split the function @ 0 in two functions, one starting at 0 and one starting at 0xc.
This is how I see this problem.
About the analysis of only one function... well, if you want to analyse only part of the binary you can't expect to gather every aspect of the binary :P you have to live with the fact that you'll have part of all the info.
Many nonreturn calls are constructed with jumps nowadays, so you will end up having many imports as bb of other functions
On 08 May 2016, at 23:58, Riccardo Schirone [email protected] wrote:
If there is a direct jump to an address, there can't be data there (unless of course we are talking about obfuscated binaries, but then if we assume that, we may fail in thousands of ways). An address reachable through a direct jump is always part of the current function IMO. You can say there is a tail recursion optimisation only when, later, you find out that there is a call to one of the basic block or there is a function symbol there or you have other strong assumptions that make you think there is a function there.
For example:
┌──< 0x00000000 eb0a jmp 0xc │ 0x00000002 0000 add byte [rax], al │ 0x00000004 0000 add byte [rax], al │ 0x00000006 0000 add byte [rax], al │ 0x00000008 0000 add byte [rax], al │ 0x0000000a 0000 add byte [rax], al └──> 0x0000000c 55 push rbp 0x0000000d 53 push rbx 0x0000000e b800000000 mov eax, 0 0x00000013 5b pop rbx 0x00000014 5d pop rbp 0x00000015 c3 ret In this case there is nothing, IMO, that can make you think that @ 0 there is a tail-recursion optimisation. So there should be just one function starting at 0, with two basic blocks (one starting at 0 and one starting at 0xc).
Instead, if we consider this code with a small change:
┌──< 0x00000000 eb0a jmp 0xc │ 0x00000002 0000 add byte [rax], al │ 0x00000004 0000 add byte [rax], al │ 0x00000006 0000 add byte [rax], al │ 0x00000008 0000 add byte [rax], al │ 0x0000000a 0000 add byte [rax], al └──> 0x0000000c 55 push rbp 0x0000000d 53 push rbx 0x0000000e b800000000 mov eax, 0 0x00000013 5b pop rbx 0x00000014 5d pop rbp 0x00000015 c3 ret 0x00000016 0000 add byte [rax], al ;-- myfunction: 0x00000018 55 push rbp 0x00000019 e8eeffffff call 0xc 0x0000001e 5d pop rbp 0x0000001f c3 ret We have 3 functions: one at 0 with only one basic block that jumps outside the function, one at 0xc and another one at 0x18. When you start analysing the function @ 0, there isn't anything that tells you that the jump instruction is actually the result of a tail-call optimisation, so you have to consider the basic block @ 0xc as part of the function @ 0. Only later, when you analyse myfunction you find out that there is a call to a basic block that is not the entry point of the relative function and so, you can split the function @ 0 in two functions, one starting at 0 and one starting at 0xc.
This is how I see this problem.
About the analysis of only one function... well, if you want to analyse only part of the binary you can't expect to gather every aspect of the binary :P you have to live with the fact that you'll have part of all the info.
— You are receiving this because you commented. Reply to this email directly or view it on GitHub
And we cannot relay always on the sections
On 08 May 2016, at 23:58, Riccardo Schirone [email protected] wrote:
If there is a direct jump to an address, there can't be data there (unless of course we are talking about obfuscated binaries, but then if we assume that, we may fail in thousands of ways). An address reachable through a direct jump is always part of the current function IMO. You can say there is a tail recursion optimisation only when, later, you find out that there is a call to one of the basic block or there is a function symbol there or you have other strong assumptions that make you think there is a function there.
For example:
┌──< 0x00000000 eb0a jmp 0xc │ 0x00000002 0000 add byte [rax], al │ 0x00000004 0000 add byte [rax], al │ 0x00000006 0000 add byte [rax], al │ 0x00000008 0000 add byte [rax], al │ 0x0000000a 0000 add byte [rax], al └──> 0x0000000c 55 push rbp 0x0000000d 53 push rbx 0x0000000e b800000000 mov eax, 0 0x00000013 5b pop rbx 0x00000014 5d pop rbp 0x00000015 c3 ret In this case there is nothing, IMO, that can make you think that @ 0 there is a tail-recursion optimisation. So there should be just one function starting at 0, with two basic blocks (one starting at 0 and one starting at 0xc).
Instead, if we consider this code with a small change:
┌──< 0x00000000 eb0a jmp 0xc │ 0x00000002 0000 add byte [rax], al │ 0x00000004 0000 add byte [rax], al │ 0x00000006 0000 add byte [rax], al │ 0x00000008 0000 add byte [rax], al │ 0x0000000a 0000 add byte [rax], al └──> 0x0000000c 55 push rbp 0x0000000d 53 push rbx 0x0000000e b800000000 mov eax, 0 0x00000013 5b pop rbx 0x00000014 5d pop rbp 0x00000015 c3 ret 0x00000016 0000 add byte [rax], al ;-- myfunction: 0x00000018 55 push rbp 0x00000019 e8eeffffff call 0xc 0x0000001e 5d pop rbp 0x0000001f c3 ret We have 3 functions: one at 0 with only one basic block that jumps outside the function, one at 0xc and another one at 0x18. When you start analysing the function @ 0, there isn't anything that tells you that the jump instruction is actually the result of a tail-call optimisation, so you have to consider the basic block @ 0xc as part of the function @ 0. Only later, when you analyse myfunction you find out that there is a call to a basic block that is not the entry point of the relative function and so, you can split the function @ 0 in two functions, one starting at 0 and one starting at 0xc.
This is how I see this problem.
About the analysis of only one function... well, if you want to analyse only part of the binary you can't expect to gather every aspect of the binary :P you have to live with the fact that you'll have part of all the info.
— You are receiving this because you commented. Reply to this email directly or view it on GitHub
Why? If you have symbols you can also use them to know when another function starts.. If you don't have them, then you can special handling the plt stubs. If you are really in worst case, at most you will consider some more bb as part of that function...
Btw, my algorithm doesn't relay on section info
you cant relay on symbols always either
On 09 May 2016, at 08:40, Riccardo Schirone [email protected] wrote:
Why? If you have symbols you can also use them to know when another function starts.. If you don't have them, then you can special handling the plt stubs. If you are really in worst case, at most you will consider some more bb as part of that function...
Btw, my algorithm doesn't relay on section info
— You are receiving this because you commented. Reply to this email directly or view it on GitHub https://github.com/radare/radare2/issues/4258#issuecomment-217786997
I know. If you don't have symbols you can detect plt stubs. If neither that is true, well, you are jumping simply somewhere else and there is nothing that can make you say that you are jumping to a different function :)
we dont supported functions with shared basic blocks.. so this approach will fuckup the whole thing
On 09 May 2016, at 13:03, Riccardo Schirone [email protected] wrote:
I know. If you don't have symbols you can detect plt stubs. If neither that is true, well, you are jumping simply somewhere else and there is nothing that can make you say that you are jumping to a different function :)
— You are receiving this because you commented. Reply to this email directly or view it on GitHub https://github.com/radare/radare2/issues/4258#issuecomment-217836109
Yeah there are a lot of things where analysis is not good enough :) It's in the design of the analysis itself. So, just because the analysis currently sucks, it doesn't mean we should continue adding wrong algorithms on top of that
Feel free to read a2f or write your own analysis loop, ehich can be done in a plugin too
On 09 May 2016, at 18:01, Riccardo Schirone [email protected] wrote:
Yeah there are a lot of things where analysis is not good enough :) It's in the design of the analysis itself. So, just because the analysis currently sucks, it doesn't mean we should continue adding wrong algorithms on top of that
— You are receiving this because you commented. Reply to this email directly or view it on GitHub
@radare Sorry for the delayed response. Running the original example still seems a tad weird:
╒ (fcn) sym.foo 7
│ sym.foo ();
│ ; CALL XREF from 0x08048301 (sym.main)
│ ┌─< 0x08048410 e90b000000 jmp sym.bar
│ 0x08048415 6690 nop
Moving to 1.2, dont wanna touch the anal much more for next week release. Focusing on stability now.
Off-topic. DWARF 5 defines DW_AT_call_tail_call. There are also GNU extensions for tail calls.
Off-topic. many ideas from DWARF could be incorporated.
@all please provide a test binaries @sivaramaaa please check this case for detecting variables/arguments.
Hi, It seems that anal.eobjmp or anal.jmp.eobj is disabled in the new version. Is there any other methods to detect tail call optimization now in radare2?
tail call optimizations should work fine by default now, if theres any regression please fill an issue and i'll have a look
On 20 Mar 2020, at 15:15, bin2415 [email protected] wrote:
Hi, It seems that anal.eobjmp or anal.jmp.eobj is disabled on the new version. Is there any other methods to detect tail call optimization now in radare2?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/radareorg/radare2/issues/4258#issuecomment-601722751, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAG75FXGIAEQDB2ZVE7QRP3RIN3BJANCNFSM4B5NRVWQ.
Great!
Recently, I am learning the algorithm of detecting tail call optimization, could you please give any hint about where is the source code to handle tail call optimization?
Thanks!
ther'es no formal definition for this and its a bit blurry by definition because it can be confused with obfuscated code so it ends up being a bit difficult to solve in a generic way, you can use metrics like lastr intruction of a function is a jump, but it can be a conditional jump too. and last instruction of a function can be inside the function because there can be more than one tailcall in the same function and this can be a jump forward or backward, so you can use some boundaries to determine this but it is always a bit fuzzy to solve.
the code is in libr/anal/fcn.c
On 20 Mar 2020, at 16:19, bin2415 [email protected] wrote:
Great! Recently, I am learning the algorithm of detecting tail call optimization, could you please give any hint about where is the source code to handle tail call optimization?
Thanks!
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/radareorg/radare2/issues/4258#issuecomment-601754092, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAG75FVDIAU54OPLCCR3453RIOCOZANCNFSM4B5NRVWQ.
Hi, is this the logic that detecting tail call optimization? If so, could you please give any advice to set the anal.jmp.tailcall value?
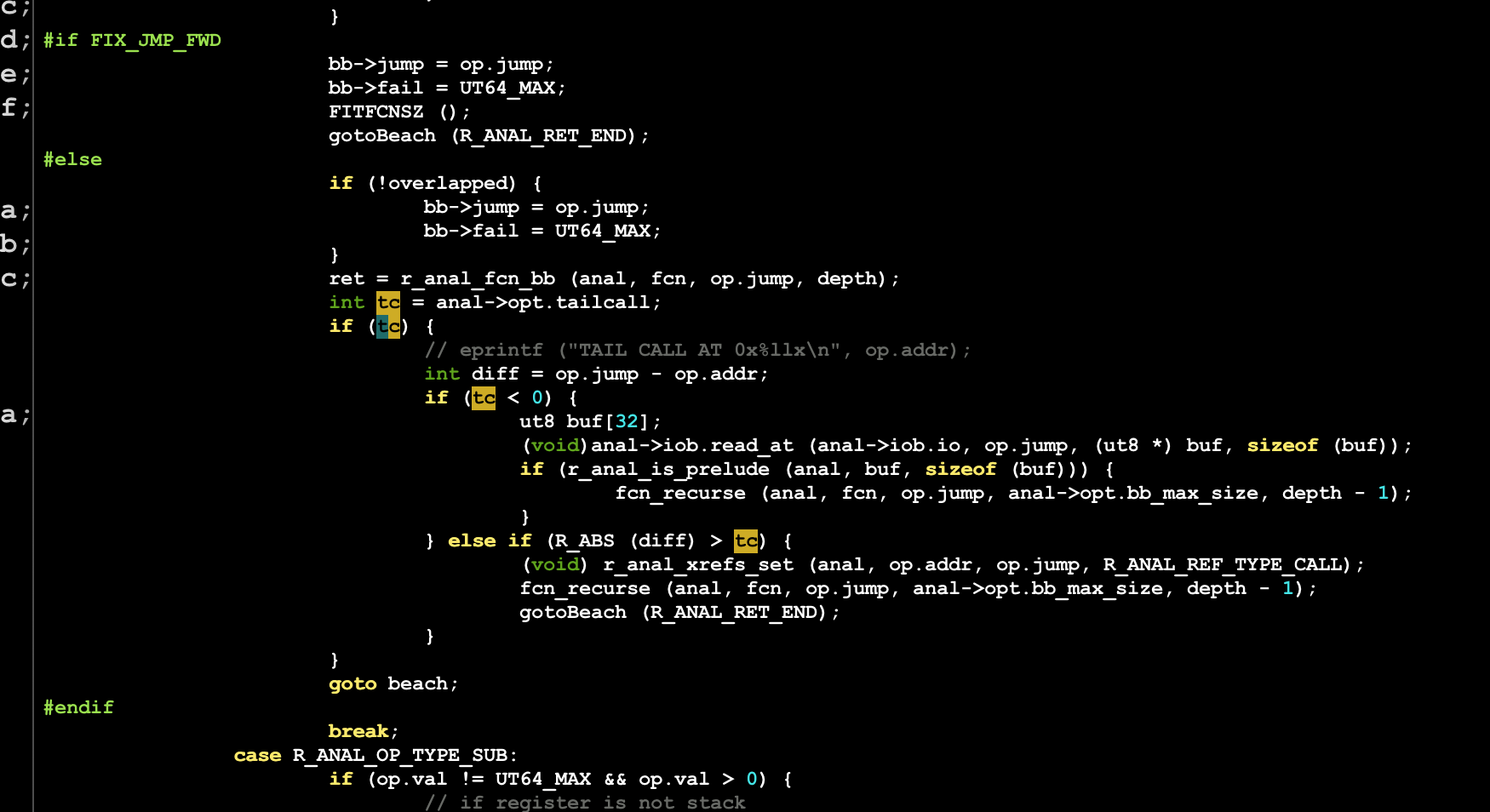
Yeah, Thanks!
A quick question, is there any advice to set the anal.jmp.tailcall value?
@trufae @ret2libc @bin2415 should we close this issue? Do we have tests for this feature?
We have some tests afaik, but there are a bunch of problems to solve for proper tailcall support. Right now it depends if the tailing function is being analyzed before and also if the distance is bigger than a specific value that is configurable by an eval var. but all those are just random assumptions that must be addressed properly