rabbitmq-server
 rabbitmq-server copied to clipboard
rabbitmq-server copied to clipboard
khepri: starting/stopping a node with many queues is very slow
Note: this issue is related to an unreleased feature
Steps (JSON file available in the sample-configs repo):
bazel run --config=local broker
bazel run --config=local rabbitmqctl enable_feature_flag raft_based_metadata_store_phase1
bazel run --config=local rabbitmqctl import_definitions 50k-classic-queues.json
# from erlang shell
rabbit:stop().
rabbit:start().
Stopping the node took 10 minutes for me. With mnesia, it's just 15s. Starting the node took 48 minutes for me. With mnesia, it's just 2m26s.
In both cases, the problem is with code compilation. code_server is the most busy process and a CPU flamegraph is almost exclusively about the code_server:
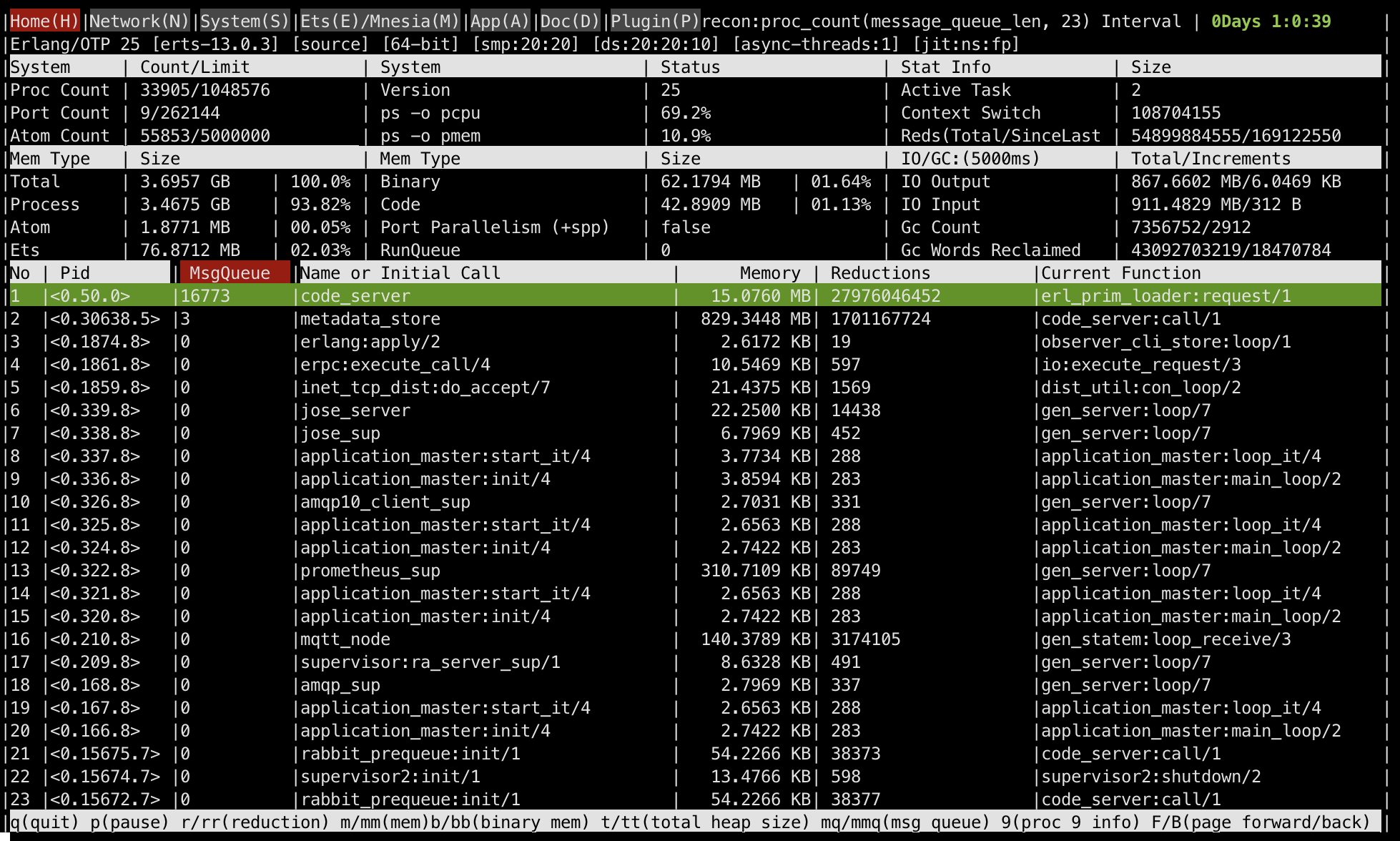

Regarding the rabbit:stop() this is the operation to blame: https://github.com/rabbitmq/rabbitmq-server/blob/khepri-queues/deps/rabbit/src/rabbit_amqqueue_process.erl#L285
All queues get their state updated to stopped simultaneously, generating 50k khepri transactions.
The expensive operation is the call to code_server:call from https://github.com/rabbitmq/khepri/blob/main/src/khepri_fun.erl#L1567, that calls code:get_object_code
https://github.com/rabbitmq/khepri/commit/7b14bbd96db01bfc91d7162b71e48f49cfffe077#diff-f6a204c9bd1dd73fe12d8819b1af8295bc43cc95dfc646ddede107888b5764e1R1385-R1402
It looks like we're currently only caching module object code in tests? Should that ifdef be ifndef?
Edit: actually that block looks like it's used in tests to be able to override a module's object code. It would probably provide a nice speed boost to cache the object code lookup though.
I figured out what happens to the khepri cache for functions. When we call rabbit:stop(), it’s the first time that rabbit_amqqueue_process:update_state/2 is executed, and the function has not been cached yet in Khepri. All queues try to execute it in parallel, and they find the function isn’t there. Then they go through the server behind code:get_object_code/1 , and when they get the answer they more or less update the cache at the same time. If we call rabbit:stop(), rabbit:start(), rabbit:stop(), the last stop call takes only a few seconds as the function is already on the cache. I wonder, should we pre-cache our transactions? Rough count, we have around 50 transactions right now.
https://github.com/rabbitmq/khepri/pull/130 introduces locks to ensure that only one process is processing a function at a time. This speeds up the transactions, as all other processes in the queue will hit the cache once the lock is released.
I've re-tested with [the most recent changes)[https://github.com/rabbitmq/rabbitmq-server/commit/7de5a806099a5902fadba8bea28f6512ae5194eb).
Mnesia:
rabbitmqctl import 50k-classic-queues.json: 15srabbitmqctl stop_app: 25srabbitmqctl start_app: 140s
Khepri:
rabbitmqctl import 50k-classic-queues.json: 16srabbitmqctl stop_app: 37srabbitmqctl start_app: 225s
Looking at the flamegraph, I think we should be able to make further improvements.
stop_app

start_app

This commit reduces the time to stop_app by half: https://github.com/rabbitmq/rabbitmq-server/commit/657ca6d1d835c72530e342071ede4e74bb36ca13
These days it takes 10s to stop and 17s to start with 50k classic queues. For comparison, with Mnesia (on the same machine) it's also 10s to stop and 19s to start.