Optimise ra_server_proc:init
#239 optimised ra server restart initialisation but there may be more that can be done to speed up cases where lots of ra servers need to be started simultaneously (like in RabbitMQ). As init is called synchronously by the supervisor we only want to do just enough work to validate we have a good ra server - the rest of the work can be done in the recover state.
Things to consider:
- Ways to read config faster.
- Delay snapshot recovery until the
recoverstate.
This is still mostly I/O bound. I've compared QQ recovery using the default disk on GCP and using an SSD disk and the difference is significant. With the default I get 113914ms to recover 5000 QQs (22ms per queue), while with an SSD disk with ext4 - 39307ms (7.8ms per queue) or even less using XFS (33522ms / 6.7ms/q).
Hi,
I actually wanted to submit this to RabbitMQ and I just noticed this issue here. We are running into this issue is that RabbitMQ is very slow to start up with many Quorum Queues.
I am pretty sure it's because this init does a lot of stuff, I tried to make it more parallel on the RabbitMQ side and that did not really help.
It happens with empty queues as well, so it may be IO bound in a sense that it takes some time to do it, but then there is something going wrong there, even in that case, they could still do their IO in parallel because the disk and CPU is barely utilised.
@luos try the latest OCI image from RabbitMQ master - should improve matters considerably.
https://github.com/rabbitmq/rabbitmq-server/runs/4191419251?check_suite_focus=true
Thank you. I tested the containers with 4900 quorum queues and on my machine version 3.9.9 it takes about 2 minutes 40 seconds to start up with 4900 queues while with your version it takes 1 minute 8 seconds, so it is definitely much better! Thank you!
It would be much easier to test this one with some more queues for me on the generic linux package (rpm for el7) because of the high load required for the number of queues, can you please share if that is accessible some way?
I managed to extract the beams and overwrite my install, in this case the number I got:
For 40 000 queues, startup is 4:30 with 3.9.9, with the linked version it's 2:52. So it is definitely an improvement.
I think the preferred way to go, as you mentioned in the top comment, would be is to move some file access out of init. And I think during testing sometimes it took more than 10 minutes for these to start up (though it did not happen now).
Possibly but we need to know at init that we have a ra server that has a decent chance of not just immediately crashing so taking stuff out of init means less guarantees provided by init.
All the heavy state machine recovery work is done in the recover state
afterwards and will take much longer than init as soon as you have a few
messages on disk. As the recovery phase executes in parallel it means that
processes doing more work in recovery will still throttle other processes
doing work in init.
3.9.9 already had some optimisations in it - if you really want to compare try 3.9.8 :)
What kind of spec machine do you use? (cpus / disk)
On Mon, 15 Nov 2021 at 09:30, Lajos Gerecs @.***> wrote:
I managed to extract the beams and overwrite my install, in this case the number I got:
For 40 000 queues, startup is 4:30 with 3.9.9, with the linked version it's 2:52. So it is definitely an improvement.
I think the way to go would be is to move some file access out of init. And I think during testing sometimes it took more than 10 minutes for these to start up (though it did not happen now).
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub https://github.com/rabbitmq/ra/issues/240#issuecomment-968698982, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAJAHFBDVWYNOCC6OXQI2KTUMDHL7ANCNFSM5HST476A . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
-- Karl Nilsson
I think I can live with 3 minutes, probably I was testing 3.9.8 when it was very slow if there were some optimisations.
I am using AWS c5.4xlarge, 5 node cluster with quorum-size=3, in a way that all queues use this one machine as a member but otherwise are distributed in the cluster.
I am using the worst disk (gp2, 120 iops 🐌 ), but today I will run some tests with the provisioned IOPS ones to see how that behaves.
In my tests, I also saw that the ra_server_proc, leaves a file open after recovery, is there something which can control that? IE, lot of idle queues just keep the files open for no reason.
@luos
In my tests, I also saw that the
ra_server_proc, leaves a file open after recovery, is there something which can control that? IE, lot of idle queues just keep the files open for no reason.
Do you happen to know which file it holds open? Looking at the code it should close all segment files before entering either follower or leader state. Of course it may open a segment after that to apply some entries at which point it will keep it open for ready access.
Hi,
I just tested 3.9.14, 3000 queues, published 1 message into each queue. During the restart or after the queues are not used at all. Then restarted one node:
[root@ip-172-31-19-223 rabbitmq]# ls -l /proc/12636/fd | head -n 20
total 0
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:39 0 -> /dev/null
lrwx------ 1 rabbitmq rabbitmq 64 Mar 23 16:39 1 -> socket:[327891]
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:39 10 -> pipe:[327906]
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 100 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUO4YUBUSH0MDAF/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1000 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOGJDDD7MV9TA3/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1001 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUO01ULKZJQXFV2/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1002 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOY7WUQE28KQXN/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1003 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOX120KU80AGSZ/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1004 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUORJ0VB3VU7YYB/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1005 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUO8QPBTORAC5MY/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1006 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOJREF99RY7LSO/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1007 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUO0XZPAYKGLHRT/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1008 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUODQ8L2KER6SI7/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1009 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOCNL0ZI5MD7OL/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 101 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOGJAA5KNKV53U/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1010 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUO1ORUKEXFHS5H/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1011 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUODUB11BZVBN5U/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1012 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUONSFL4MMGOFJ9/00000001.segment
lr-x------ 1 rabbitmq rabbitmq 64 Mar 23 16:40 1013 -> /var/lib/rabbitmq/mnesia/rabbit@ip-172-31-19-223/quorum/rabbit@ip-172-31-19-223/2F_QUOMS7VO8PG8NC3/00000001.segment
[root@ip-172-31-19-223 rabbitmq]# ls -l /proc/12636/fd | grep segment | wc -l
3083
I think the reason I noticed this was that in this case the memory usage was very high, but maybe that was with larger messages or larger segment files?
The reason I find this interesting is that a queue which does nothing, has no files open but after a restart, all of them keep it open:
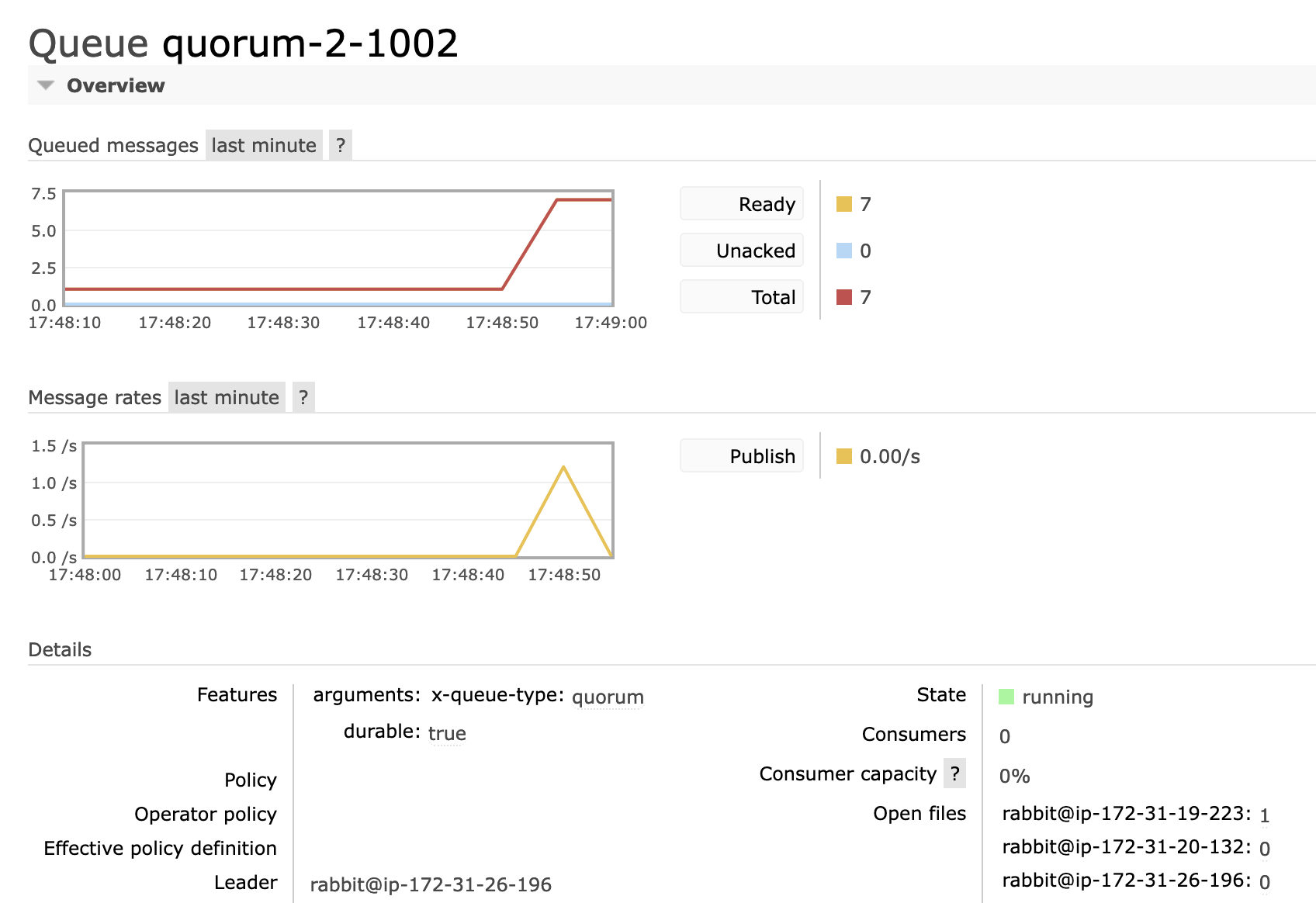
I think what it is is that after recovery these followers receive an append entires rpc from each leader, when they do so they need to validate their log against the leader's. To do so they have to read the last entry from the log which is all on disk after a restart so that is why they have a file handle open.
Validating the log is something even an idle RA cluster does periodically (for liveness) which is why the files are left open.
Followers have a limit of only a single file handle so they will never go over that (although we may make that configurable so that followers can have more open if beneficial).
I think if you are correct that only single file handle can be open, then it can be closed. Also with #304 probably it is very fast. :) Thank you