GPTQ-for-LLaMa
 GPTQ-for-LLaMa copied to clipboard
GPTQ-for-LLaMa copied to clipboard
How to fine-tune the 4-bit model?
First a big thanks for this amazing effort!
I was just trying to fine-tune this 4-bit model under the transformers framework. The model could be loaded successfully and the training process worked well, however, the loss just became nan after one single loss.backward().
Here is the my code:
import sys
from pathlib import Path
sys.path.insert(0, str(Path("/efs-storage/text-generation-webui/repositories/GPTQ-for-LLaMa")))
import llama
load_quant = llama.load_quant
model = load_quant(
"/file/llama-7b-hf",
'/file/llama-7b-hf-int4/llama-7b-4bit.pt',
4
)
model.to(device)
....
for batch in tqdm(dataloader):
model.train()
input_ids = batch[0]['input_ids'].squeeze(1).to(device)
attention_mask = batch[0]['attention_mask'].squeeze(1).to(device)
tgt_labels = batch[1].squeeze(1).to(device)
loss = model(
input_ids = input_ids,
attention_mask = attention_mask,
labels=tgt_labels
).loss
model.zero_grad()
loss.backward()
optimizer.step()
torch.cuda.empty_cache()
And here is how my loss looks like after training one batch:
tensor(nan, device='cuda:1', dtype=torch.float16, grad_fn=<NllLossBackward0>)
I wonder is there any way to fine-tune the 4-bit model? thanks!
gptq quantization is designed for inference and does not support training.
Not sure if it is possible to have A @ B.T adapter for vecquant4matmul_cuda. That is needed to compute gradient for lora finetuning. https://github.com/tloen/alpaca-lora/issues/2#issuecomment-1472302525
@johnsmith0031
Would training quantized models ever be possible due to precision requirements for the gradients? From what I understand, PEFT reduces VRAM usage by training a limited a # of parameters but training is still being done in floating point numbers and not integers right. Also, even if it could work wouldn't the latency of quantizing/dequantizing the model severely hinder training performance?
You could train LoRA modules. Those are more efficient to train anyway. Imagine each layer as a 4096 x 4096 matrix of 4-bit weights. You superimpose a lower-rank 4096 x 4 matrix of FP32, which expands over the larger matrix via an outer product. After finishing the training session, you can de-quantize the 4096 x 4096, add the LoRA, then re-quantize. You can also not fuse anything, and leave the LoRA as a separate layer. That allows switching different variations of the model at runtime without loading in new weights.
Most weights (~16 GB): 4-bit integer (non-differentiable), not changed during gradient descent LoRa weights (~64 MB): 32-bit float (differentiable), changed during gradient descent
Also, even if it could work wouldn't the latency of quantizing/dequantizing the model severely hinder training performance?
You typically train with batches of several inputs at once. Switching 16 bit -> 4 bit improves the arithmetic intensity by 4x, meaning you can fully utilize hardware with only 1/4x as large batches. That should cancel the per-batch (not per-input) overhead of dequantizing.
@philipturner That sounds very promising! Would be really cool to see a RLHF training scheme utilize this kind of setup for the 30B or 65B models to try and replicate ChatGPT's results using LoRA.
You typically train with batches of several inputs at once. Switching 16 bit -> 4 bit improves the arithmetic intensity by 4x, meaning you can fully utilize hardware with only 1/4x as large batches. That should cancel the per-batch (not per-input) overhead of dequantizing.
This will probably require custom CUDA kernels or maybe even dedicated hardware support for 4 bit matmul and other BLAS operations right? Similar to how tensor cores in Turing and newer architectures accelerate 8 bit operations? I'm a bit skeptical of the linear performance increases since 8 bit inference in the transformers library has been around 40% - 60% slower than fp16, I would expect 4 bit to be lower.
This will probably require custom CUDA kernels or maybe even dedicated hardware support
No, this is already possible with PyTorch function calls. It also doesn't need to be restricted to CUDA/Nvidia-only. I was considering asking GPT-4 to draft me a Metal kernel that dequantizes in-place. Take geohot's kernel, inject decompression in place of the following lines, them reinterpret-cast two adjacent elements as the thread's components of a simdgroup_matrix.
// old
simdgroup_load(A[0], data1, {N}, ulong2(k, 0));
simdgroup_load(A[1], data1, {N}, ulong2(k, 8));
simdgroup_load(A[2], data1, {N}, ulong2(k, 16));
simdgroup_load(A[3], data1, {N}, ulong2(k, 24));
// new
// Read a bunch of 4-bit weights from contiguous device memory.
// Use SIMD-scoped operations to transpose certain chunks in-place
// to the different threads' SIMD-group matrices.
// Decompress to 32-bit and reinterpret cast to SIMD-group matrix.e
8 bit inference
8 bit inference will have vastly different performance patterns than 8 bit training. One is memory-bound, the other compute-bound.
try and replicate ChatGPT's results using LoRA.
Sorry to disappoint, but GPT-3.5 outperforms LLaMa by a large margin, without fine-tuning. And GPT-4 makes every LLM before it essentially obsolete. I've been using it to help me generate code instead of setting up local models for that purpose. It's more efficient to rephrase whatever your goal is - instead of a low-accuracy local model with high batch throughput, ask Bing GPT-4 some hard questions. Then it shows you how to implement the goal yourself.
Thanks for the deep insights into LLMs. I had some hopes of maybe LoRA adapter for the larger 30B or 65B LLaMa models that were trained Stanford's Alpaca could be a match against text-davinci-003 since it generally showed promising results for the smaller models. I guess some dreams were just not meant to be :(
And GPT-4 makes every LLM before it essentially obsolete.
Perhaps GPT-5 could give us the answers to achieving the previous model's iterations on consumer hardware someday? That would really be something.
I was planning to build an application that uses LLaMa as an AI-powered transpiler. It would port massive CUDA code bases to Metal, processing batches of ~32 files at once. I attached the raw data gathered while planning the application.
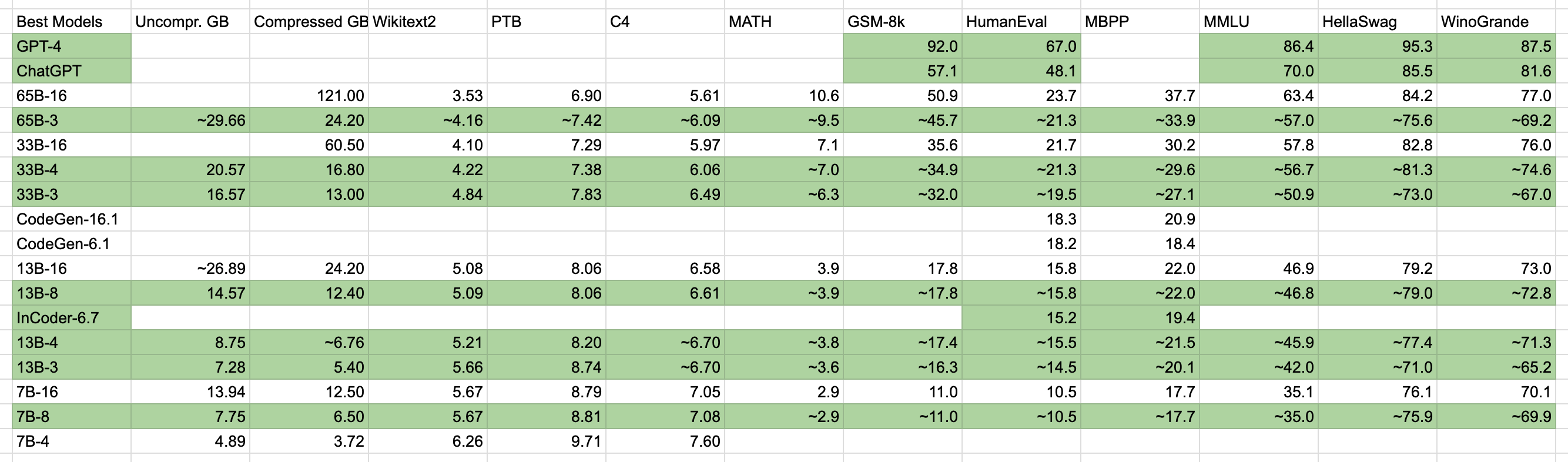
Fun fact: Before LLaMa-65B-3bit data was available, I predicted its Wikitext2 performance to within rounding error. I guessed ~4.16; the actual was 4.17. The only reference measurement was 16-bit, scoring 3.53.
65B-3 probably performs equal to 33B-4 in HumanEval. I wanted to try though, because it's the largest model my 32 GB GPU could fit (projected 29.7 GB deserialized). Regardless, its codegen performance pales in comparison even to untuned GPT-3.5.
We also try to implement 4bit-qlora, thanks to the optimized kernel implementation of back-propagation, the fine-tuning speed is similar to 8-bit lora at present. Welcome to use and issue: https://github.com/megvii-research/Sparsebit/tree/main/large_language_models/alpaca-qlora