GPTQ-for-LLaMa
 GPTQ-for-LLaMa copied to clipboard
GPTQ-for-LLaMa copied to clipboard
CUDA: 8bit quantized models are stupid.
I have tried to quantize some models to 8bit after seeing scores for Q4. The models produced appear coherent but get Wikitext evaluations like 2000 or 5000. In contrast, the models I can run with bitsandbytes have fantastic wikitext scores (6.x, 7.x). I tried both opt and llama. Opt had 2000, llama7b was at 5152. I did not use group size or act order. Just plain int8 quantization.
edit: I see.. the models get nonsensical if almost any context is used. Talking with the assistant is fine but then any character it becomes a mess.
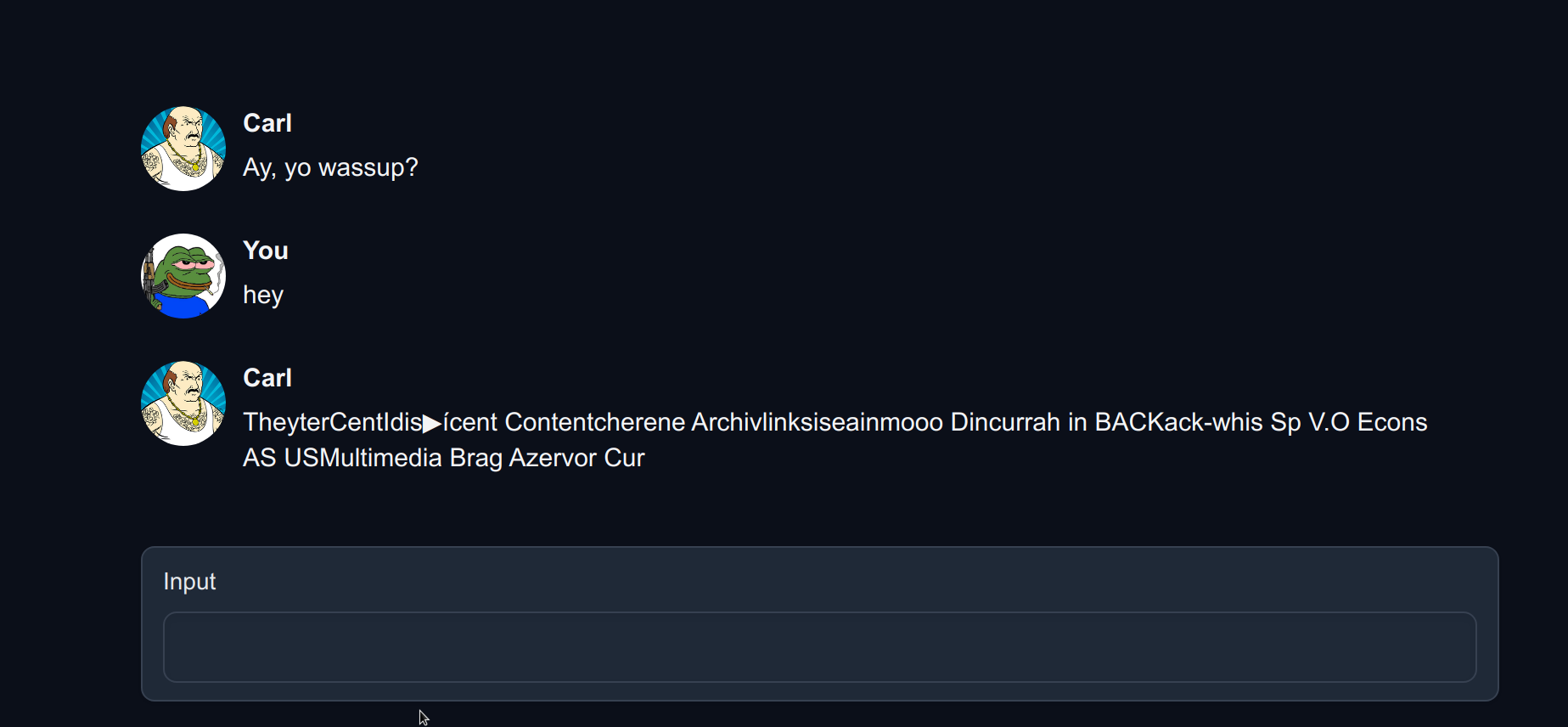
I has same problem with 65B 4-bit 128-group model inferenced with CUDA:
Quantization: CUDA_VISIBLE_DEVICES=0,1 python llama.py decapoda-research/llama-65b-hf c4 --wbits 4 --true-sequential --act-order --groupsize 128 --save llama65b-4bit-128g.pt
Inference: CUDA_VISIBLE_DEVICES=0,1 python -i llama_inference.py decapoda-research/llama-65b-hf --wbits 4 --groupsize 128 --load llama65b-4bit-128g.pt --text "Question: Write a poem. \n Answer:It was a sunny.\nIt was a snowy day.\n"
Result:
<unk> Question: Tell me about You
Answer:
The
This
C
A
What incre
In
I converted a model to 8-bit using AutoGPTQ and now it works both here and in what converted it.. so the quantization code is broken and not inference.
I converted a model to 8-bit using AutoGPTQ and now it works both here and in what converted it.. so the quantization code is broken and not inference.
could you share the process of how to do that in detail?
Yea.. download autogptq and install then use this script: https://github.com/PanQiWei/AutoGPTQ/blob/main/examples/quantization/quant_with_alpaca.py