quick-lint-js
 quick-lint-js copied to clipboard
quick-lint-js copied to clipboard
Optimize variable lookup
About 30% of lex+parse+lint time for three.min.js is spent comparing identifier names in linter (since renamed to variable_analyzer):
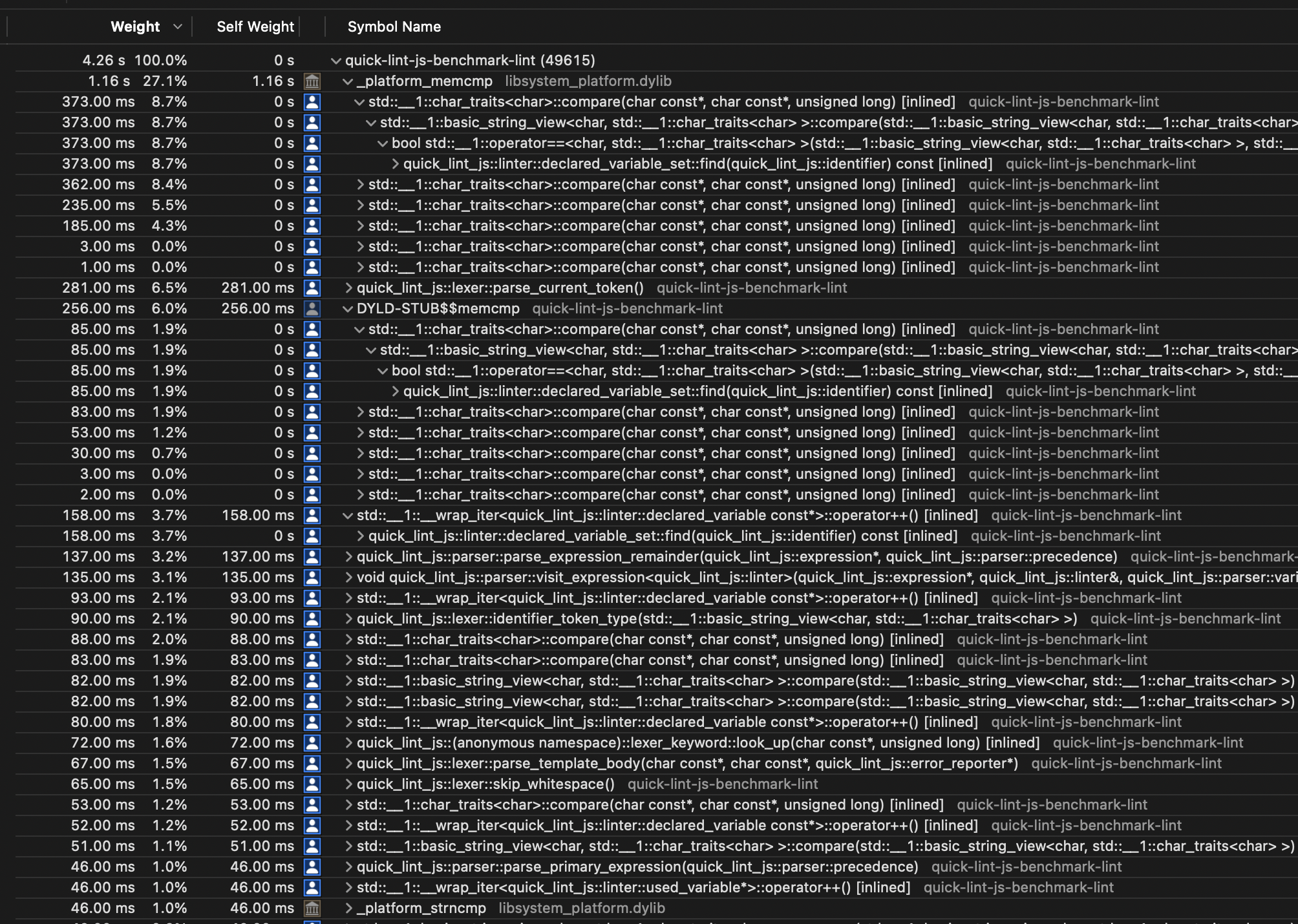
Let's optimize this for some nice perf win.
I have two ideas.
String pool
When lexing, create unique 32-bit (or 64-bit) handles for each equivalent identifier. When looking up variables, compare handles, avoiding any string comparisons.
The identifier class would look like this:
class identifier {
public:
const char8* span_begin_;
int span_size_;
std::uint32_t pool_handle_;
};
- lexing is slower + pool can be reused for keyword recognition - property names are pooled too (but this can be fixed later) + identifier comparison is extremely fast + variable lookup is O(n) instead of O(n*m) (where m is the length of an identifier, n is the number of variables in a scope
Hash table
When lexing, hash identifiers. When looking up variables, use this hash to reference a hash table. We still need to compare strings.
The identifier class would look like this:
class identifier {
public:
const char8* span_begin_;
const char8* normalized_begin_;
int span_size_;
int normalized_size_;
std::uint32_t hash_; // or std::uint64_t
};
We could be clever and store the normalized identifier inside the hash_ field. This means looking up small variable names involves fewer cache lines.
- lexing is slower + hash can be reused for keyword recognition - property names are hashed too (but this can be fixed later) + variable lookup is O(m) instead of O(n*m) (where m is the length of an identifier, n is the number of variables in a scope) (for minified code, m is small)
TODO: Research typical values of n and m in practice. m is artificially low in minified code (usually 1 or 2 bytes).
For an interning string pool, we'd probably use a hash table. What hash function should we use?
Wisdom from smhasher and Richter et al suggests that a simple implementation is ideal. This is good news to me, 'cus I'll have to integrate hashing with our identifier logic.
According to smhasher, on ARM, FNV (public domain) seems to perform well, and on x86, wyhash (public domain) seems to perform well.
Here's an idea to reuse the 128-bit SIMD registers we already use when parsing identifiers:
- On the last iteration, mask off non-identifier bytes, making them zeros (or ff)
- Hash each 32-bit lane independently (i.e. run four independent 32-bit hashers)
- At the end of parsing the identifier, mix each 32-bit lane horizontally
Step 1 is easy with FNV2, which works 32 bits at a time and has a 32-bit state.
Step 2 could be done by running 64-bit FNV2 to mix the first 64 bits with the last 64 bits.
It'd be fun to test my scheme with hash function testers.
On x86, aesenc works on 128-bit SSE registers. That might be even better than FNV2.
There are three cases:
- keywords (compile-time-known strings)
- fast identifiers (ASCII; no escapes)
- slow identifiers (non-ASCII, or escapes)
In the first two cases, we can point to an existing string span. In the first case, the string span can be length-prefixed or null-terminated or both.
In the last case, we allocate a copy of the string anyway. That copy can be placed inside the interning table or it can be separately allocated.
Thought: The table could have three classes of strings:
- small fast strings (<= 8 bytes)
- external strings
- slow strings
Small strings and slow strings are stored in the table. For external strings, the table only stores a pointer and size.
The table is a vector of subtables. Each subtable stores strings of one class (small, external, or slow). [EDIT: How would lookup know whether to look in the external table or the slow table?] Perhaps we can have a fixed set of subtables for small fast strings, and create subtables for external and slow strings as needed (instead of growing a subtable). A goal is to avoid rehashing and copying a bunch of strings or string pointers.
Note: For fast strings, there are 26+10+2=38 possibilities per character, except for the first character which has 26+2=28 possibilities.
Small string subtables: size 1: 28 max entries = 28 max bytes size 2: 28*38 max entries = 2'128 max bytes size 3: 28*38**2 max entries = 121'296 max bytes size 4: 28*38**3 max entries = 6'145'664 max bytes
I don't think allocating 6 MiB for strings of size 4 is a good idea. So I think the 'small fast strings' idea won't work unless we allow each subtable to grow dynamically. (But I wanted to avoid table resizing...)
I think we can't reasonably avoid table resizing. Therefore, my idea of using a 32-bit index into the string pool won't work. =\
As the string ID, we should use a normal 64-bit pointer to the normalized string. Booooring.
Well, we could use a 31-bit index into the source code string or a 31-bit index into the temporary string table. 🤔
If we have a 32-bit string ID, identifier could look like this:
class identifier {
const char8* span_begin_; // 8 bytes
int span_size_; // 4 bytes
identifier_string_id normalized_; // 4 bytes
};
class identifier_string_id {
// size is stored in the table (O(1)) or computed as needed (O(n)).
std::uint32_t begin_offset_ : 31;
std::uint32_t is_source_code_string_ : 1;
};
If we have a 64-bit string ID, identifier could look like this:
class identifier {
// span size is computed as needed (O(n)).
const char8* span_begin_; // 8 bytes
identifier_string_id normalized_; // 8 bytes
};
class identifier_string_id {
// size is stored in the table (O(1)) or computed as needed (O(n)).
const char8* begin_;
};
or this:
class identifier {
const char8* span_begin_; // 8 bytes
identifier_string_id normalized_; // 8 bytes
int span_size_; // 4 bytes
// If needed, we could store the normalized size here.
// If we don't, we waste 4 bytes due to padding.
};
class identifier_string_id {
// size is stored in the table (O(1)), computed as needed (O(n)),
// or stored in identifier.
const char8* begin_;
};
We only currently use the size of a normalized identifier for equality comparing, debug printing, and checking for on-prefixed JSX attributes, so I think O(n) for querying the normalized size is fine.
We use spans often in diagnostics. We should probably keep the span's size O(1). So a 32-bit string ID is preferable.
KISS implementation: All string data is external; power of two table sizes; quadratic probing; full hashes in-line; single array; stable ID inside the table:
struct Entry {
const Char8* string_data;
std::uint64_t hash;
std::uint32_t string_size;
std::uint32_t string_id;
Token_Type token_type;
// padding
};
Entry* hash_table_;
std::uint64_t hash_mask_;
std::uint32_t size_; // next string_id
std::uint32_t max_size_before_rehash_;