NEW Feature: Mixup transform for Object Detection
- [x] Closes #6720
- [x] Passes tests
- [x] Uses transforms V2
Official implementation of the paper: Here
Minimalist code to reproduce:
import PIL
from torchvision import io, utils
from torchvision.prototype import features, transforms as T
from torchvision.prototype.transforms import functional as F
# Defining and wrapping input to appropriate Tensor Subclasses
path = "/Users/ambujpawar/Desktop/Cat03.jpeg"
path2 = "/Users/ambujpawar/Desktop/dog_2.jpeg"
# img = features.Image(io.read_image(path), color_space=features.ColorSpace.RGB)
img = PIL.Image.open(path)
img2 = PIL.Image.open(path2)
bbox_1 = features.BoundingBox(
[[2, 0, 100, 100], [396, 92, 479, 241]],
format=features.BoundingBoxFormat.XYXY,
spatial_size=F.get_spatial_size(img),
)
bbox_2 = features.BoundingBox(
[ [200, 100, 300, 300], [424, 38, 479, 250]],
format=features.BoundingBoxFormat.XYXY,
spatial_size=F.get_spatial_size(img2),
)
label = features.Label([59, 58])
# Defining and applying Transforms V2
trans = T.Compose(
[
T.MixupDetection(),
]
)
imgs = [img, img2]
bboxes = [bbox_1, bbox_2]
labels= [label, label]
imgs, bboxes, labels = trans(imgs, bboxes, labels)
# Visualizing results
viz = utils.draw_bounding_boxes(F.to_image_tensor(imgs[1]), boxes=bboxes[0])
F.to_pil_image(viz).show()
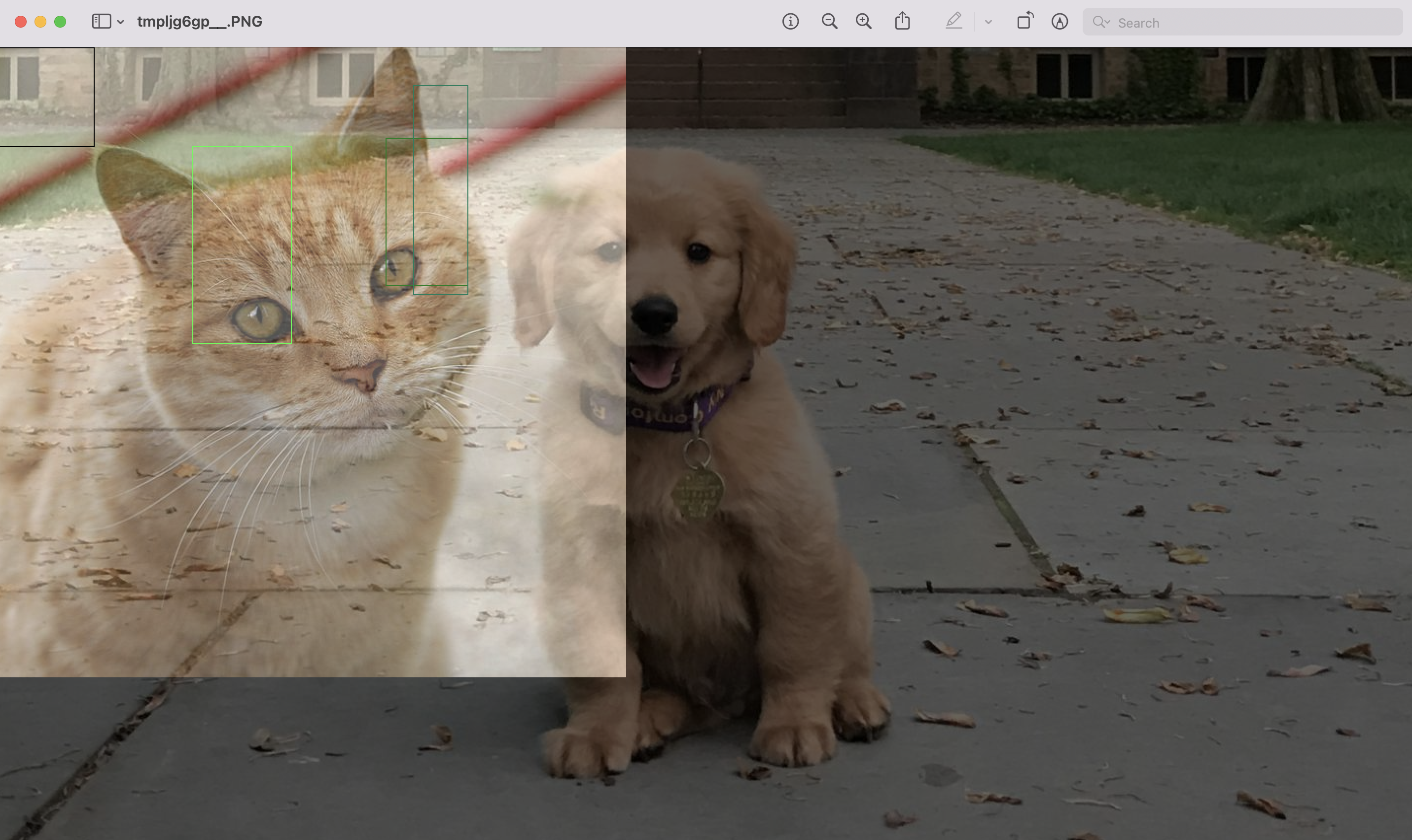
Examples output:
Please dont pay attention to bounding boxes in this particular image.
I just entered those boxes randomly
Hey @ambujpawar and thanks a lot for the PR! I'll try to help you land it in the near future. As you might have noticed, this transform is not straight forward to implement since it requires a batch of detection samples. In this context this means a list of samples, whereas for classification "batch" usually means an extra batch dimension on a tensor. This makes this implementation a lot harder compared to regular MixUp.
Still, we need to be able to support it. I'll look into how we can streamline the process for example by providing a _DetectionBatchTransform or standalone utilities that makes this easier. I'll get back to you when I found a solution or need your input. Is that ok with you?
Hi @pmeier, it sounds perfect to me. Looking forward to your suggestions :)
I agree with your comment regarding MixupforDetection taking batches of detection samples. However, shouldn't it be similar to what we do in CopyPaste transform? Because in copyPaste we also expect a batch of images
However, shouldn't it be similar to what we do in CopyPaste transform? Because in copyPaste we also expect a batch of images
Exactly. Before we operated under the assumption that SimpleCopyPaste is the only batch detection transform and thus a one-off solution for it was good enough. With DetectionMixUp in the picture our assumption is no longer true and we need to look how we can provide utilities to ease the implementation of these transforms.
Right now the largest part of the implementation deals with the "infrastructure", i.e. extracting the right inputs and putting them back afterwards. Only a small part is spent on the actual algorithm. In a best case scenario, I find a solution so you can only write the algorithm and the remainder is handled by a base class or some high level utilities.
That clears up all the questions for me. Thanks!
Yeah, a base class is perhaps the best solution in those regards. Please let me know if I my help is needed :)
Thanks for adding the patch! :)
I think it looks nice. Regarding your questions:
- Both SimpleCopyPaste as well MixUpDetection use a "split" layout for images and targets. Is that by design or could we use one container like a dictionary for both of them. Imagine something like sample = {"image": ..., "boxes": ...}.
Yes, they both use a "split" design, but Mixup Detection but Mixup does not use "Masks". Mixup is only used for Detection not Segmentation.
- The old extraction and insertion logic converted to tensor and back for images and (un-)wrapped the other features. Right now, the new logic does not do this. Instead this is moved inside the _mixup function. We could move that back into the logic as well. What do you prefer?
If I had to choose one design, I would chose the former design but I dont have any strong arguments for it.
Shall we also include the developers of SimpleCopyPaste transform as well? They might also have some comments regarding these changes
[Just a question] why did we have to do changes to "torchvision/prototype/datasets/_builtin/coco.py"? I did not get that...
So, I will just have to fix the tests and we are done?
Hi @pmeier , is there anything I can do to speed up the merging of this PR to master?
Sorry, for keep you waiting. Unfortunately, I'm caught up in something else until end of the week.
Things you can do until then:
- move your implementation into the
_augmentmodule as suggested in https://github.com/pytorch/vision/pull/6721#discussion_r1017685091 - refactor the
_check_inputsper https://github.com/pytorch/vision/pull/6721#discussion_r1017693484 and https://github.com/pytorch/vision/pull/6721#discussion_r1017693719 - improve the error messages that I either left out or just added dummys like https://github.com/pytorch/vision/pull/6721#discussion_r1016715204
- Think again whether or not we need to special case images in the whole logic. My initial version didn't do it and @datumbox also asked about it in https://github.com/pytorch/vision/pull/6721#discussion_r1017690068.
Hi @pmeier , Sorry I was a bit stuck with something but now happy to be back to contribute. I have tried to resolve the first 3 topics you mentioned in your previous comment. The tests are still breaking and I will take a look at it again. In the meantime, PTAL at the PR.
One request from my side, its still not clear to me what should we regarding the point you mentioned over here
Think again whether or not we need to special case images in the whole logic. My initial version didn't do it and @datumbox also asked about it in https://github.com/pytorch/vision/pull/6721#discussion_r1017690068.
and this comment. I dont have any strong preference for either case. I am happy to implement whatever is easier to implement and maintain :)
@ambujpawar I've refactored the extraction and insertion logic in ae9908b037f5c64334ddba5f61d378bcc699a458. This temporarily breaks SimpleCopyPaste, but that is fine as long as we are in the design phase. Let me know what you think. While doing this, I already fixed a few of the comments I had above. Please still have a look in case I misunderstood something.
Hi @pmeier, it looks good to me. Thanks a lot for refactoring the code. It looks much neat and tidy now :)
Shall I now work on fixing tests and refactoring SimpleCopyPaste?
Shall I now work on fixing tests and refactoring SimpleCopyPaste?
Yup, go ahead. Plus, you haven't addressed some of the comments above. Could you go through all open comments and mark the ones that have been addressed as resolved? That makes it much easier to assess at a glance what still needs some work and what is finished.
Sorry, for being a bit late with my part of the code. But finally fixed up the tests :) (they were simple just had to remove extract_image_targets call)
Even though I could run the tests successfully. However, I could not replicate it as a user of the transform. For instance,
import PIL
from torchvision import io, utils
from torchvision.prototype import features, transforms as T
from torchvision.prototype.transforms import functional as F
from torchvision.prototype import datapoints
# Defining and wrapping input to appropriate Tensor Subclasses
path = "/Users/ambujpawar/Desktop/Cat03.jpeg"
path2 = "/Users/ambujpawar/Desktop/dog_2.jpeg"
# img = features.Image(io.read_image(path), color_space=features.ColorSpace.RGB)
img = PIL.Image.open(path)
img2 = PIL.Image.open(path2)
bbox_1 = datapoints.BoundingBox(
[[2, 0, 100, 100], [396, 92, 479, 241]],
format=datapoints.BoundingBoxFormat.XYXY,
spatial_size=F.get_spatial_size(img),
)
bbox_2 = datapoints.BoundingBox(
[ [200, 100, 300, 300], [424, 38, 479, 250]],
format=datapoints.BoundingBoxFormat.XYXY,
spatial_size=F.get_spatial_size(img2),
)
label = datapoints.Label([59, 58])
# Defining and applying Transforms V2
trans = T.Compose(
[
T.MixupDetection(),
]
)
imgs = [img, img2]
bboxes = [bbox_1, bbox_2]
labels= [label, label]
sample = {"image": imgs, "boxes": bboxes, "label": labels}
imgs, bboxes, labels = trans(imgs, bboxes,labels)
results in
TypeError: Sample at index 0 in the batch is missing dict_keys(['boxes', 'labels'])
This is based on the example listed in the blogpost rergarding Transforms v2. How should we call this transform instead?
Hey @ambujpawar :wave: I hope you are all right. I wanted to check in on this PR. Are you planning on finishing it or should I take over?
Hi @pmeier, thanks for asking! I'm doing good :) just back from a super long christmas and new year vacation so did not have time to work on this PR. I would still like to work on if we are not running on a deadline or something.
I can work on it this weekend and can request you for re-review :) Does that work with you?
No rush from my side. I thought I check on you after roughly one month of inactivity. In case you didn't plan to finish this, we still would like to have it and I would have taken over. This weekend sounds good.
Hi, I added the test cases for when the ratios for mixup are 0 and 1. However, I still think there is some bug when we are mixing the two images. I am not able to exactly point what causes it though. Perhaps after looking at the code something rings a bell for you.
So, this is the expected output (or something similar). Notice the light appearance of cat in the background

However, after our latest changes it look like this. Notice the picture of cat is completely overwriting the picture of dog.

I am not exactly sure but I suspect something is going wrong when we are mixing images in augment.py Line 376-381. I am not able to solve it but perhaps you can have a look at it please?
I am not exactly sure but I suspect something is going wrong when we are mixing images in
augment.py Line 376-381. I am not able to solve it but perhaps you can have a look at it please?
Yup, the problem is that we replace the values in the first image with the ones from the second rather than adding them. To demonstrate, let's establish a visual benchmark first that we both can easily reproduce:
import PIL.Image
import torch
from torchvision.io import read_image
from torchvision.prototype import datapoints, transforms
from torchvision.utils import make_grid
def read_sample(path, label):
image = datapoints.Image(read_image(path))
bounding_box = datapoints.BoundingBox(
[[0, 0, *image.spatial_size[::-1]]], format="xyxy", spatial_size=image.spatial_size
)
label = datapoints.Label([label])
return dict(
path=path,
image=image,
bounding_box=bounding_box,
label=label,
)
batch = [
read_sample("test/assets/encode_jpeg/grace_hopper_517x606.jpg", 0),
read_sample("test/assets/fakedata/logos/rgb_pytorch.png", 1),
]
transform = transforms.MixupDetection()
torch.manual_seed(0)
output = transform(batch)
image = make_grid([sample["image"] for sample in output])
PIL.Image.fromarray(image.permute(1, 2, 0).numpy()).save("mixup_detection.jpg")
Output with the current implementation is

So, in the left image, the PyTorch logo is the second image and thus we are just pasting it over Grace Hopper. On the right side the PyTorch logo is completely gone, since Grace Hopper is larger and thus completely paints over it.
Applying the first suggestion from below gives us

And thus the behavior we want.
And thus the behavior we want.
Yup, exactly! This is the behavior we want. Thanks for fixing it, my eyes were not able to find it haha
I've pushed an update to SimpleCopyPaste, but so far I have only done visual checks. The tests for it very much relied on the internals and so I'll need to fix them as well. @ambujpawar is there anything left on your side that you want to do? Otherwise, I'm going to finish over the next few days.
@ambujpawar is there anything left on your side that you want to do?
Nope. I think everything is done on my side and this mixupDetection feature is ready. :)
Hi @pmeier, Congrats on the torchvision v0.15 release. I just wanted to checkup on the future regarding the MixupDetection transform. Is it still waiting on the topic of "How to smoothly support "pairwise" transforms" listed in #7319?
Thanks in advance!! :)
Yes, unfortunately we are blocked by this. Sorry for not informing your earlier. We held off the batch transforms for now for the reason you listed above. I'll ping you here when we have figured it out. Thanks a lot for your patience!
Ah sure! No worries Thanks for the update! :) BTW, the new transforms_v2 really look good. Thanks for them
Hi everyone,
I was looking for an implementation of MixUp for object detection in torchvision and came across this PR.
I noticed it has not seen much activity for a while; could someone please clarify its current status or whether this is still planned to be merged?
I would be happy to help rebase or update it to align with the current API if that would be useful.
Thanks!