botorch
 botorch copied to clipboard
botorch copied to clipboard
SingleTaskGP with more than 800 training samples
Issue description
Hi, everyone!
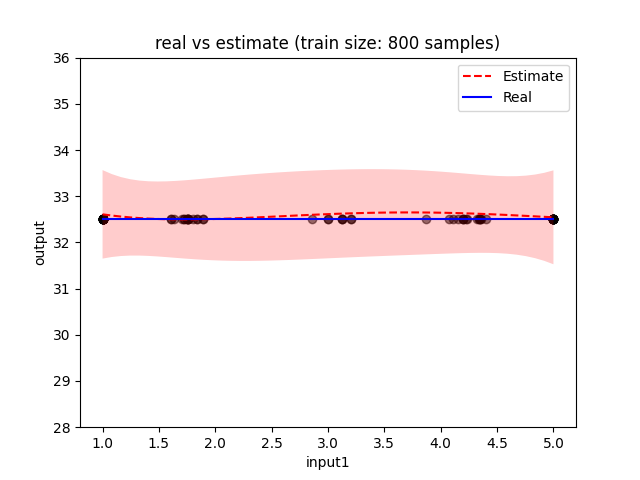
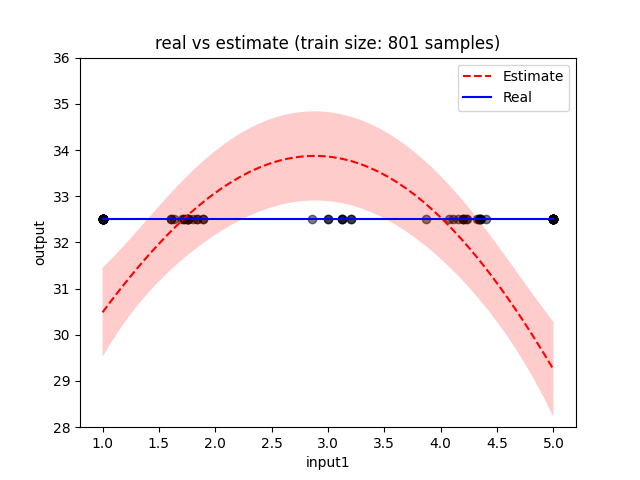
I am experiencing an issue when training a GP using BoTorch SingleTaskGP function. Everything works fine when using up to 800 training samples. When adding more training data the GP behaves strange, in the sense that the estimate and variance of the predicted function degrades significantly. In order to visualize this, I plotted an estimate of the function with 800 training samples as well as with 801 (please note that you might obtain different plots as you train on a different machine).
Could you please help me to understand this behavior? Is this normal or am I missing something?
I have also attached the training data (the first 5 columns are inputs and the last represents the output). Also, I attached the script to train and plot the estimate results.
Thank you in advance!
Code example
Attached is the code used to replicate the training process. At line 162 you can set how many training samples to use: N_EXAMPLES = 801.
System Info
Please provide information about your setup, including
- BoTorch Version:
0.6.0 - GPyTorch Version:
1.6.0 - PyTorch Version:
1.10.2+cpu - Computer OS:
Windows 11 / Ubuntu 18.04
Hi, thanks for your question. This has most likely to do with the fact that gpytorch is switching from using Cholesky-based solves to using Linear Conjugate Gradient solves by default at a matrix size of 800: https://github.com/cornellius-gp/gpytorch/blob/master/gpytorch/settings.py#L524-L532. This can improve speed / reduce memory usage, but typically comes at a loss in accuracy of the linear solves. If your system is not well-conditioned, then this can be a problem for inference.
To change the size at which this switch happens, you can wrap you code in the following context manager:
with gpytorch.settings.max_cholesky_size(NEW_MAX_SIZE):
# code goes here
where NEW_MAX_SIZE is the maximum size for which Cholesky solves are used.
What's your typical data size n, btw? This will work well for a few thousand data points, but will quickly hit scalability limits due to the O(n^3) cost of the Cholesky decomposition for more than that.
Hi @Balandat!
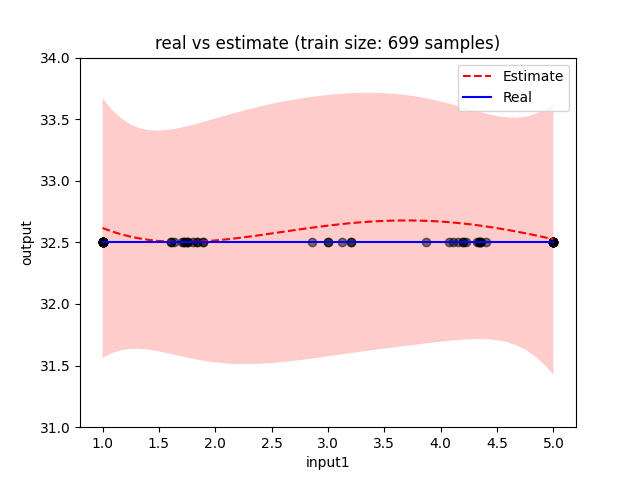
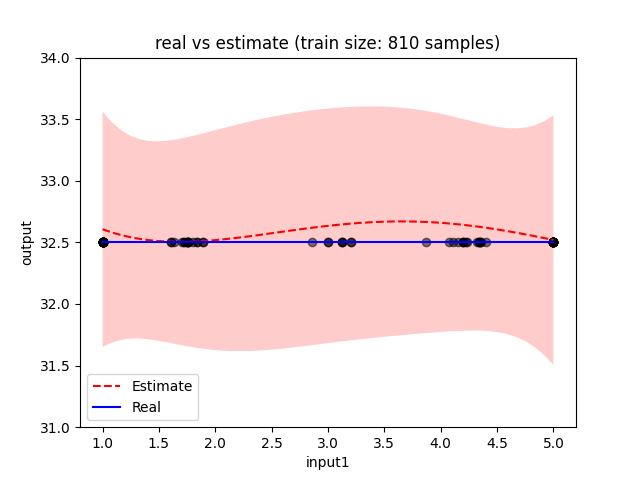
Thank your for the information, I set the cholesky size to 1000 and it seems to work as expected now! Variance decreased as we train with more data.
Regarding the typical data size n, I expect to have a maximum of 4000 training samples on certain configurations. Do you see any issue with setting such a large size for Cholesky solver?
Thank you!
 !
!
The only issue is that things may get slow, but other than that this shouldn’t be an issue.
I took a look into your code yesterday. I couldn't figure out what the issue was since I didn't know about the gpytorch side switching, but here are a few things I noticed.
- Seems like you're manually normalizing your inputs using
MinMaxScaler, then denormalizing afterwards. We have input and outcome transforms (NormalizeandStandardize) that you can pass in model construction to have this done under the hood, simplifying the code. You can use these by passing inoutcome_transform=Standardize(m=train_y.shape[-1]), input_transform=Normalize(d=train_x.shape[-1])into the model constructor. - You're using a custom loop with Adam to train your model. We have a convenient utility,
fit_gpytorch_model, that works quite well for fitting models. All you need is to callfit_gpytorch_model(mll). - You're using a custom RBF kernel without any priors. If you omit the kernel and likelihood,
SingleTaskGPhas pre-set priors that generally work quite well with standardized data (the default uses a Matern kernel).
If you're doing these for any particular reason, by all means keep them. These are just things I noticed while trying to debug. The result of these changes was a model fit with much narrower error bars, which is what I'd expect to see with 800 training points. I just figured I'd note these in case you're new to the package :)
@saitcakmak ,
First of all, thank you for taking the time to analyze the code. I find your suggestions very helpful.
I implemented the fit_gpytorch_model function instead of the adam optimizer steps + used the default SingleTaskGP with the Matern kernel and default prior.
Yes, the GP is very fit now with almost no visible error bars, but the code crashed after 564 samples:
python3.7/site-packages/gpytorch/utils/cholesky.py", line 32, in psd_safe_cholesky L = torch.cholesky(A, upper=upper, out=out) RuntimeError: cholesky_cpu: U(107,107) is zero, singular U.
I think the optimizer reached convergence and there is nothing to train with additional samples, right? In this case, I should think of a stopping criteria.
The error you're getting is due to numerical issues. It happens when you have lots of training data and the points are too close together. The first thing I'd to is to make sure you're using double dtype, which you can do by passing in dtype=torch.double whenever you're constructing a new tensor (including the train and test inputs to the model).
If you're already using double, one other thing that may help is to wrap the part of the code that throws this error in gpytorch.settingscholesky_max_tries(num_tries), where the default num_tries is 3. This is the number of times gpytorch will attempt to add a jitter to the diagonal of the tensor before computing the Cholesky decomposition, so larger values (e.g., 6) will tolerate numerical singularity a bit better.
Hello @saitcakmak, sorry for answering so late.
Thank you for the explanation, I am trying to use gpytorch.settingscholesky_max_tries(num_tries), but I get the error:
AttributeError: module 'gpytorch.settings' has no attribute 'cholesky_max_tries'
I see it is in the documentation (https://docs.gpytorch.ai/en/stable/settings.html), but I cannot find it in my botorch install. Was it introduced in a later version?
To answer your question yes, our training samples are very close to each other. Either I use your suggestion or I try to use a try / catch block when I train the model and use the previous one if it fails.
Hi,
I am running version 1.4.0, which I guess is quite old. Should upgrade first. :)