botorch
 botorch copied to clipboard
botorch copied to clipboard
Update tutorials to use "sample_around_best": True
Motivation
Using "sample_around_best": True should lead to improved optimization performance.
Have you read the Contributing Guidelines on pull requests?
Yest
Test Plan
TODO: Re-run the notebooks, so the outputs reflect the changes.
Related PRs
(If this PR adds or changes functionality, please take some time to update the docs at https://github.com/pytorch/botorch, and link to your PR here.)
cc @sdaulton
Codecov Report
Merging #1075 (e7b6f4b) into main (40d89e1) will not change coverage. The diff coverage is
n/a.

@@ Coverage Diff @@
## main #1075 +/- ##
=========================================
Coverage 100.00% 100.00%
=========================================
Files 112 112
Lines 9330 9330
=========================================
Hits 9330 9330
Continue to review full report at Codecov.
Legend - Click here to learn more
Δ = absolute <relative> (impact),ø = not affected,? = missing dataPowered by Codecov. Last update 40d89e1...e7b6f4b. Read the comment docs.
are there any cases where we wouldn't want to sample_around_best? if it's so commonly useful for AF optimization why hide it in a options blob?
On Wed, Feb 9, 2022 at 9:37 AM Sait Cakmak @.***> wrote:
Motivation
Using "sample_around_best": True should lead to improved optimization performance. Have you read the Contributing Guidelines on pull requests https://github.com/pytorch/botorch/blob/main/CONTRIBUTING.md#pull-requests ?
Yest Test Plan
TODO: Re-run the notebooks, so the outputs reflect the changes. Related PRs
(If this PR adds or changes functionality, please take some time to update the docs at https://github.com/pytorch/botorch, and link to your PR here.)
cc @sdaulton https://github.com/sdaulton
You can view, comment on, or merge this pull request online at:
https://github.com/pytorch/botorch/pull/1075 Commit Summary
- e7b6f4b https://github.com/pytorch/botorch/pull/1075/commits/e7b6f4be7c5cd82d7319e0af10cf48289ef525b3 update notebooks to use "sample_around_best": True
File Changes
(19 files https://github.com/pytorch/botorch/pull/1075/files)
- M tutorials/GIBBON_for_efficient_batch_entropy_search.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-d2aadbf437f9805e38a3df495a5b9249b2e31a9d3ac8ab91c5628892dbec7ede (60)
- M tutorials/bo_with_warped_gp.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-1b6755c677043550bd87cdf17e817fe5b631c6bc35bf5791de7b834893784d24 (24)
- M tutorials/closed_loop_botorch_only.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-53a32bcd7f29f10bb055b2127ce43af5cc4104c21682d1f6991451e96cf4254f (4)
- M tutorials/compare_mc_analytic_acquisition.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-7ec14ebfe7fbb2b049d27bd12dca5da7f43b8221260b27abca95fd7e5d44adbf (7)
- M tutorials/composite_bo_with_hogp.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-49a3f6d69dfea21621408ba17c04c7b293afccf6fc446f0349a6fe0745ac4359 (3)
- M tutorials/composite_mtbo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-205223177634950cf481c79425d2a86b04f94fae1b9d9f7d14c1982c0a49cfdb (11)
- M tutorials/constrained_multi_objective_bo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-71885dde614230d8593189ed143acfa732d4e239d453faa298271460e2ca41d4 (1196)
- M tutorials/constraint_active_search.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-4f130567b33adc27d6375b3d08e1cd66996f8734c93faa513976006f58fde3a0 (1466)
- M tutorials/discrete_multi_fidelity_bo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-b96dc62d69e7c4489ea0e29bf3f0265f0f6426a2547fbf259602bb08e4691a0d (1052)
- M tutorials/max_value_entropy.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-ba5f8293c8f87463f72fd57a3f1b4f582b0d3a20198ec6cb2eb9e62a9595d1b1 (7)
- M tutorials/meta_learning_with_rgpe.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-39cbe1842635fc584e8fc3b4b1c527df9467191a3abfe37f8ed33df4a94b77fc (4)
- M tutorials/multi_fidelity_bo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-aea0c004611ee2d10bfc208596c4d173687cfd8fe41ace4dbc0440c4bbaa62ef (13)
- M tutorials/multi_objective_bo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-3f73e2644afebf41b2ef5e4fba9736c9d13b14212e069310ddbe7916bbb74f87 (1198)
- M tutorials/one_shot_kg.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-05432bc58cd0484ab77b60a8f965bbf44f2643600009cb0feed3ef4943cf2a88 (5)
- M tutorials/preference_bo.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-ea8aff8b75c07bf323654639e0b0d072b9fc1a27001d886e090b2be09c5a25aa (3)
- M tutorials/risk_averse_bo_with_environmental_variables.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-330e8d357b2b3ea2f0ca9821b3bb87ec13403e21e69c1e3ff991e25b8d569362 (1039)
- M tutorials/risk_averse_bo_with_input_perturbations.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-7f3c3652c8896e2cf43cac62ebe6460a7682423c908d4d8bcb929bc75b765702 (1226)
- M tutorials/turbo_1.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-a898b3f489b9edd159bdc313a8d0befebda73192ae54f55623f85b5050d474ff (4)
- M tutorials/vae_mnist.ipynb https://github.com/pytorch/botorch/pull/1075/files#diff-2b0836ae5c390f34f1285dea238c9e547807e61311c7b28da57be6b11d7045e6 (3)
Patch Links:
- https://github.com/pytorch/botorch/pull/1075.patch
- https://github.com/pytorch/botorch/pull/1075.diff
— Reply to this email directly, view it on GitHub https://github.com/pytorch/botorch/pull/1075, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAAW34MQCTODPOPSZIBEHXDU2KQ6FANCNFSM5N6FSZ3A . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
You are receiving this because you are subscribed to this thread.Message ID: @.***>
are there any cases where we wouldn't want to sample_around_best?
Probably not? I guess that requires some additional benchmarking
if it's so commonly useful for AF optimization why hide it in a options blob?
I would like to avoid adding a long rats tail of boolean options to our interfaces, that will soon become unwieldy. If we want to enable that by default we can do that without exposing it as a separate option.
The main issue I can imagine with this is that the initialization becomes too greedy and we fail to uncover a global optimum of the acquisition function that is far from the best point(s). This on its own may not actually be a bad thing since it is similar to what TuRBO/MORBO do and we may just end up avoiding points that we probably didn't want to pick in the first place. I think there will be a heavy dependency of the dimensionality here where this will probably always help in the high-dimensional setting, but it may make things worse for simpler low-dimensional problems. I echo what @Balandat said that some benchmarking would be interesting.
Thanks for putting this up @saitcakmak!
I think there are very few situations where using sample_around_best would perform worse. It is worth noting that sample_around_best does not replace the space filling (sobol) initialization heuristic. Rather, the initial conditions consist of raw_samples points from the global sobol heuristic and raw_samples points from the sample_around_best heuristic. Hence, if the sobol points identify a design far from the current best with higher acquisition value than points around the current best, then that design will be preferred in the initialization heuristic.
Using sample_around_best makes the heuristic slightly more greedy, so the one case where this could be suboptimal is if one of the sobol points with lower acquisition value is not selected as a starting point for gradient optimization, but is proximal to a better optima of the acquisition surface. However, there is still additional tempering since we do Boltzmann sampling on the acquisition values of the raw samples which should help mitigate this. Using more random restarts would also help mitigate this.
The main benefit of sample_around_best is mitigate the issue of all raw samples having zero acquisition value. This can happen for improvement-based acquisition functions when the optima are in tiny regions of the design space. For example in ZDT1, the Pareto frontier is in a small sliver of the design space and the acquisition surface quickly becomes zero basically everywhere, expect for right around the previously evaluated pareto optimal designs. Using sample_around_best makes acquisition optimization significantly more robust to these scenarios (see attached plot).
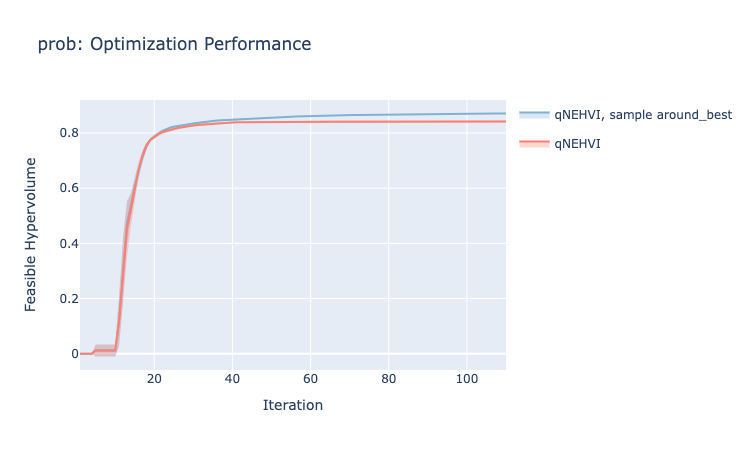
In the high-dimensional case, the sample_around_best heuristic only perturbs a subset of the dimensions of the best point(s) (and again this complements and does not replace the global sobol heuristic). So I would expect there to be a significant performance improvement.
The main challenge to turning this on by default is that it would require unifying an interface for extracting previously evaluated designs(or best designs) from botorch models and acquisition functions. The current error handling is fairly robust, but may not cover every single edge case for any conceivable (e.g. non-gpytorch) model. @Balandat and I have chatted about adding an X_baseline/train_inputs property to all botorch models and acquisition functions, but that change would touch a lot of code. If we want to turn this on by default, we should explore that refactor.
@saitcakmak has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator.
@saitcakmak What is the status of this PR? It would great to get his merged in
@sdaulton We're waiting on the benchmarking suite to decide whether to set sample_around_best True by default.
We're waiting on the benchmarking suite to decide whether to set sample_around_best True by default.
@saitcakmak is this PR still relevant?
The PR itself is not that relevant (quite a bit outdated). Making these changes to the default configs is still worth investigating though. I never got around to properly benchmark this since we had a bunch of reproducibility bugs in the benchmarking suite back then.
One thing to keep in mind: The current implementation of sample_around_best doubles the number of raw_samples. So, turning it on and off doesn't really give us an apples to apples comparison. If we're going to benchmark this, we should make sure they use the same number of raw_samples.