❓ [Question] No improvement when I use sparse-weights?
❓ Question
No speed improvement when I use sparse-weights.
I just modified this notebook https://github.com/pytorch/TensorRT/blob/master/notebooks/Hugging-Face-BERT.ipynb
And add the sparse_weights=True in the compile part. I also changed the regional bert-base model when I apply 2:4 sparse on most parts of the FC layers.

But whether I set the "sparse_weights=True", the results look like no changes. Here are some results.
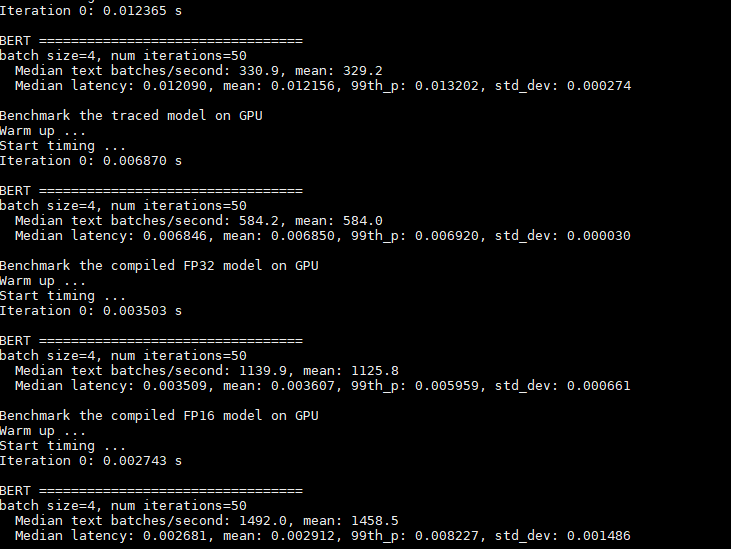
set sparse_weights=False
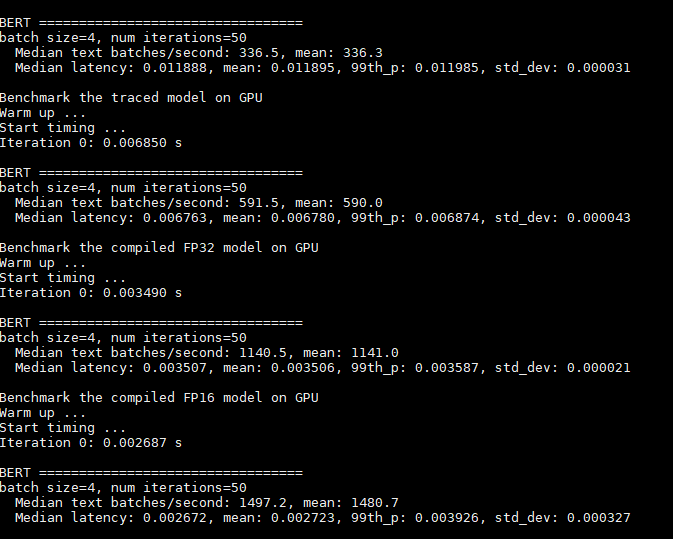
set sparse_weights=True
Environment
Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.13
- CPU Architecture:x86-64
- OS (e.g., Linux):Ubuntu 18.04
- How you installed PyTorch (
conda,pip,libtorch, source): - Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.8
- CUDA version: 11.7.1
- GPU models and configuration: Nvidia A100 GPU & CUDA Driver Version 515.65.01
- Any other relevant information:
Additional context

Hi @wzywzywzy this is because of TensorRT's kernel autotuning. TRT selects the fastest kernels for your model, regardless of sparsity, so in this case the dense kernels may be faster than the sparse & thus are selected regardless of the flag.
Would be good to confirm this, but it is almost certainly the cause.
One other consideration: is your model in 2:4 structured sparsity? I can't tell by the above. Also, how did you sparsify the model?
Hi @wzywzywzy this is because of TensorRT's kernel autotuning. TRT selects the fastest kernels for your model, regardless of sparsity, so in this case the dense kernels may be faster than the sparse & thus are selected regardless of the flag.
@ncomly-nvidia Sincerely thank you for your reply!
I just chose the largest 2 entries among every 4 .
Here are some parts of my model parameters on the Bert's FC layers.
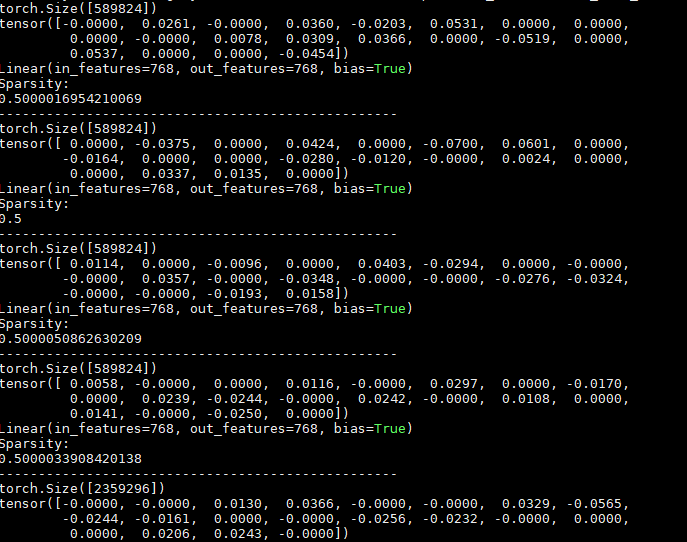
By the way, I refer to Nvidia's previous work , discover that you test the acceleration reach 1.5x ,so I wondering how you test this.
One option for you to investigate the kernel selection further is to extract the TRT engines from Torch-TRT via the torch_tensorrt.ts.convert_method_to_trt_engine API then tools like TREx to inspect it and compare with sparsity on & off.
Now I use the ASP https://github.com/NVIDIA/apex/blob/master/apex/contrib/sparsity/asp.py method to prune my bert model, however when I convert my onnx to trt_engine I find that the [09/16/2022-02:05:36] [I] [TRT] (Sparsity) Layers eligible for sparse math: [09/16/2022-02:05:36] [I] [TRT] (Sparsity) TRT inference plan picked sparse implementation for layers: are both empty.
[ASP][Info] permutation_search_kernels can be imported. [ASP] torchvision is imported, can work with the MaskRCNN/KeypointRCNN from torchvision. [ASP] Auto skipping pruning cls.predictions.decoder::weight of size=torch.Size([30522, 768]) and type=torch.float32 for sparsity [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.attention.self.query::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.attention.self.key::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.attention.self.value::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.attention.output.dense::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.intermediate.dense::weight of size=torch.Size([3072, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.0.output.dense::weight of size=torch.Size([768, 3072]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.attention.self.query::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.attention.self.key::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.attention.self.value::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.attention.output.dense::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.intermediate.dense::weight of size=torch.Size([3072, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.1.output.dense::weight of size=torch.Size([768, 3072]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.attention.self.query::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.attention.self.key::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.attention.self.value::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.attention.output.dense::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.intermediate.dense::weight of size=torch.Size([3072, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.2.output.dense::weight of size=torch.Size([768, 3072]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.3.attention.self.query::weight of size=torch.Size([768, 768]) and type=torch.float32 [ASP] Enabled 50.00% sparsity for bert.encoder.layer.3.attention.self.key::weight of size=torch.Size([768, 768]) and type=torch.float32
Here are more details
my tensorrt version is 8.4.2.4
The command of trtexec trtexec --onnx=./onnx/bert-sparse-ASP-qabase-sq128-b1.onnx --sparsity=force --workspace=4096
&&&& RUNNING TensorRT.trtexec [TensorRT v8402] # trtexec --onnx=./onnx/bert-sparse-ASP-qabase-sq128-b1.onnx --sparsity=force --workspace=4096
[09/16/2022-09:55:06] [W] --workspace flag has been deprecated by --memPoolSize flag.
[09/16/2022-09:55:06] [I] === Model Options ===
[09/16/2022-09:55:06] [I] Format: ONNX
[09/16/2022-09:55:06] [I] Model: ./onnx/bert-sparse-ASP-qabase-sq128-b1.onnx
[09/16/2022-09:55:06] [I] Output:
[09/16/2022-09:55:06] [I] === Build Options ===
[09/16/2022-09:55:06] [I] Max batch: explicit batch
[09/16/2022-09:55:06] [I] Memory Pools: workspace: 4096 MiB, dlaSRAM: default, dlaLocalDRAM: default, dlaGlobalDRAM: default
[09/16/2022-09:55:06] [I] minTiming: 1
[09/16/2022-09:55:06] [I] avgTiming: 8
[09/16/2022-09:55:06] [I] Precision: FP32
[09/16/2022-09:55:06] [I] LayerPrecisions:
[09/16/2022-09:55:06] [I] Calibration:
[09/16/2022-09:55:06] [I] Refit: Disabled
[09/16/2022-09:55:06] [I] Sparsity: Forced
[09/16/2022-09:55:06] [I] Safe mode: Disabled
[09/16/2022-09:55:06] [I] DirectIO mode: Disabled
[09/16/2022-09:55:06] [I] Restricted mode: Disabled
[09/16/2022-09:55:06] [I] Build only: Disabled
[09/16/2022-09:55:06] [I] Save engine:
[09/16/2022-09:55:06] [I] Load engine:
[09/16/2022-09:55:06] [I] Profiling verbosity: 0
[09/16/2022-09:55:06] [I] Tactic sources: Using default tactic sources
[09/16/2022-09:55:06] [I] timingCacheMode: local
[09/16/2022-09:55:06] [I] timingCacheFile:
[09/16/2022-09:55:06] [I] Input(s)s format: fp32:CHW
[09/16/2022-09:55:06] [I] Output(s)s format: fp32:CHW
[09/16/2022-09:55:06] [I] Input build shapes: model
[09/16/2022-09:55:06] [I] Input calibration shapes: model
[09/16/2022-09:55:06] [I] === System Options ===
[09/16/2022-09:55:06] [I] Device: 0
[09/16/2022-09:55:06] [I] DLACore:
[09/16/2022-09:55:06] [I] Plugins:
[09/16/2022-09:55:06] [I] === Inference Options ===
[09/16/2022-09:55:06] [I] Batch: Explicit
[09/16/2022-09:55:06] [I] Input inference shapes: model
[09/16/2022-09:55:06] [I] Iterations: 10
[09/16/2022-09:55:06] [I] Duration: 3s (+ 200ms warm up)
[09/16/2022-09:55:06] [I] Sleep time: 0ms
[09/16/2022-09:55:06] [I] Idle time: 0ms
[09/16/2022-09:55:06] [I] Streams: 1
[09/16/2022-09:55:06] [I] ExposeDMA: Disabled
[09/16/2022-09:55:06] [I] Data transfers: Enabled
[09/16/2022-09:55:06] [I] Spin-wait: Disabled
[09/16/2022-09:55:06] [I] Multithreading: Disabled
[09/16/2022-09:55:06] [I] CUDA Graph: Disabled
[09/16/2022-09:55:06] [I] Separate profiling: Disabled
[09/16/2022-09:55:06] [I] Time Deserialize: Disabled
[09/16/2022-09:55:06] [I] Time Refit: Disabled
[09/16/2022-09:55:06] [I] Inputs:
[09/16/2022-09:55:06] [I] === Reporting Options ===
[09/16/2022-09:55:06] [I] Verbose: Disabled
[09/16/2022-09:55:06] [I] Averages: 10 inferences
[09/16/2022-09:55:06] [I] Percentile: 99
[09/16/2022-09:55:06] [I] Dump refittable layers:Disabled
[09/16/2022-09:55:06] [I] Dump output: Disabled
[09/16/2022-09:55:06] [I] Profile: Disabled
[09/16/2022-09:55:06] [I] Export timing to JSON file:
[09/16/2022-09:55:06] [I] Export output to JSON file:
[09/16/2022-09:55:06] [I] Export profile to JSON file:
[09/16/2022-09:55:06] [I]
[09/16/2022-09:55:07] [I] === Device Information ===
[09/16/2022-09:55:07] [I] Selected Device: NVIDIA A100-PCIE-40GB
[09/16/2022-09:55:07] [I] Compute Capability: 8.0
[09/16/2022-09:55:07] [I] SMs: 108
[09/16/2022-09:55:07] [I] Compute Clock Rate: 1.41 GHz
[09/16/2022-09:55:07] [I] Device Global Memory: 40396 MiB
[09/16/2022-09:55:07] [I] Shared Memory per SM: 164 KiB
[09/16/2022-09:55:07] [I] Memory Bus Width: 5120 bits (ECC enabled)
[09/16/2022-09:55:07] [I] Memory Clock Rate: 1.215 GHz
[09/16/2022-09:55:07] [I]
[09/16/2022-09:55:07] [I] TensorRT version: 8.4.2
[09/16/2022-09:55:07] [I] [TRT] [MemUsageChange] Init CUDA: CPU +327, GPU +0, now: CPU 336, GPU 3207 (MiB)
[09/16/2022-09:55:09] [I] [TRT] [MemUsageChange] Init builder kernel library: CPU +414, GPU +132, now: CPU 769, GPU 3339 (MiB)
[09/16/2022-09:55:09] [I] Start parsing network model
[09/16/2022-09:55:09] [I] [TRT] ----------------------------------------------------------------
[09/16/2022-09:55:09] [I] [TRT] Input filename: ./onnx/bert-sparse-ASP-qabase-sq128-b1.onnx
[09/16/2022-09:55:09] [I] [TRT] ONNX IR version: 0.0.7
[09/16/2022-09:55:09] [I] [TRT] Opset version: 12
[09/16/2022-09:55:09] [I] [TRT] Producer name: pytorch
[09/16/2022-09:55:09] [I] [TRT] Producer version: 1.13.0
[09/16/2022-09:55:09] [I] [TRT] Domain:
[09/16/2022-09:55:09] [I] [TRT] Model version: 0
[09/16/2022-09:55:09] [I] [TRT] Doc string:
[09/16/2022-09:55:09] [I] [TRT] ----------------------------------------------------------------
[09/16/2022-09:55:10] [W] [TRT] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[09/16/2022-09:55:11] [I] Finish parsing network model
[09/16/2022-09:55:13] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +839, GPU +362, now: CPU 2120, GPU 3701 (MiB)
[09/16/2022-09:55:13] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +128, GPU +60, now: CPU 2248, GPU 3761 (MiB)
[09/16/2022-09:55:13] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[09/16/2022-09:55:36] [I] [TRT] Detected 3 inputs and 1 output network tensors.
[09/16/2022-09:55:37] [I] [TRT] Total Host Persistent Memory: 32
[09/16/2022-09:55:37] [I] [TRT] Total Device Persistent Memory: 0
[09/16/2022-09:55:37] [I] [TRT] Total Scratch Memory: 7864832
[09/16/2022-09:55:37] [I] [TRT] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 0 MiB, GPU 530 MiB
[09/16/2022-09:55:37] [I] [TRT] [BlockAssignment] Algorithm ShiftNTopDown took 0.002828ms to assign 1 blocks to 1 nodes requiring 7864832 bytes.
[09/16/2022-09:55:37] [I] [TRT] Total Activation Memory: 7864832
[09/16/2022-09:55:37] [I] [TRT] (Sparsity) Layers eligible for sparse math:
[09/16/2022-09:55:37] [I] [TRT] (Sparsity) TRT inference plan picked sparse implementation for layers:
[09/16/2022-09:55:37] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +512, now: CPU 0, GPU 512 (MiB)
[09/16/2022-09:55:37] [W] [TRT] The getMaxBatchSize() function should not be used with an engine built from a network created with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH flag. This function will always return 1.
[09/16/2022-09:55:37] [W] [TRT] The getMaxBatchSize() function should not be used with an engine built from a network created with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH flag. This function will always return 1.
[09/16/2022-09:55:38] [I] Engine built in 31.1935 sec.
[09/16/2022-09:55:38] [I] [TRT] [MemUsageChange] Init CUDA: CPU +0, GPU +0, now: CPU 1831, GPU 3621 (MiB)
[09/16/2022-09:55:38] [I] [TRT] Loaded engine size: 507 MiB
[09/16/2022-09:55:38] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +507, now: CPU 0, GPU 507 (MiB)
[09/16/2022-09:55:38] [I] Engine deserialized in 0.535168 sec.
[09/16/2022-09:55:39] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +7, now: CPU 0, GPU 514 (MiB)
[09/16/2022-09:55:39] [I] Using random values for input input_ids
[09/16/2022-09:55:39] [I] Created input binding for input_ids with dimensions 1x128
[09/16/2022-09:55:39] [I] Using random values for input attention_mask
[09/16/2022-09:55:39] [I] Created input binding for attention_mask with dimensions 1x128
[09/16/2022-09:55:39] [I] Using random values for input token_type_ids
[09/16/2022-09:55:39] [I] Created input binding for token_type_ids with dimensions 1x128
[09/16/2022-09:55:39] [I] Using random values for output pooler_output
[09/16/2022-09:55:39] [I] Created output binding for pooler_output with dimensions 1x128x30522
[09/16/2022-09:55:39] [I] Starting inference
[09/16/2022-09:55:42] [I] Warmup completed 87 queries over 200 ms
[09/16/2022-09:55:42] [I] Timing trace has 1991 queries over 3.00407 s
[09/16/2022-09:55:42] [I]
[09/16/2022-09:55:42] [I] === Trace details ===
[09/16/2022-09:55:42] [I] Trace averages of 10 runs:
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.44015 ms - Host latency: 2.67636 ms (enqueue 1.45173 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43944 ms - Host latency: 2.67588 ms (enqueue 1.45135 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43975 ms - Host latency: 2.67618 ms (enqueue 1.45181 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43954 ms - Host latency: 2.67613 ms (enqueue 1.45128 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43923 ms - Host latency: 2.67582 ms (enqueue 1.45137 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43964 ms - Host latency: 2.67586 ms (enqueue 1.45145 ms)
[09/16/2022-09:55:42] [I] Average on 10 runs - GPU latency: 1.43852 ms - Host latency: 2.67532 ms (enqueue 1.4507 ms)
[09/16/2022-09:55:42] [I] === Performance summary ===
[09/16/2022-09:55:42] [I] Throughput: 662.767 qps
[09/16/2022-09:55:42] [I] Latency: min = 2.65906 ms, max = 8.73267 ms, mean = 2.69056 ms, median = 2.6759 ms, percentile(99%) = 2.72009 ms
[09/16/2022-09:55:42] [I] Enqueue Time: min = 1.43567 ms, max = 7.5061 ms, mean = 1.46642 ms, median = 1.45178 ms, percentile(99%) = 1.49292 ms
[09/16/2022-09:55:42] [I] H2D Latency: min = 0.0141602 ms, max = 0.024292 ms, mean = 0.0171952 ms, median = 0.0170898 ms, percentile(99%) = 0.0185547 ms
[09/16/2022-09:55:42] [I] GPU Compute Time: min = 1.42346 ms, max = 7.4978 ms, mean = 1.45419 ms, median = 1.4397 ms, percentile(99%) = 1.48682 ms
[09/16/2022-09:55:42] [I] D2H Latency: min = 1.20898 ms, max = 1.23926 ms, mean = 1.21919 ms, median = 1.21924 ms, percentile(99%) = 1.22119 ms
[09/16/2022-09:55:42] [I] Total Host Walltime: 3.00407 s
[09/16/2022-09:55:42] [I] Total GPU Compute Time: 2.89529 s
[09/16/2022-09:55:42] [W] * Throughput may be bound by Enqueue Time rather than GPU Compute and the GPU may be under-utilized.
[09/16/2022-09:55:42] [W] If not already in use, --useCudaGraph (utilize CUDA graphs where possible) may increase the throughput.
[09/16/2022-09:55:42] [W] * GPU compute time is unstable, with coefficient of variance = 13.1997%.
[09/16/2022-09:55:42] [W] If not already in use, locking GPU clock frequency or adding --useSpinWait may improve the stability.
[09/16/2022-09:55:42] [I] Explanations of the performance metrics are printed in the verbose logs.
[09/16/2022-09:55:42] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v8402] # trtexec --onnx=./onnx/bert-sparse-ASP-qabase-sq128-b1.onnx --sparsity=force --workspace=4096
by the way ,when I create vit model by timm, I can see only a Conv was successfully detected.
trtexec --onnx=vit_tiny_patch16_224_sparse.onnx --sparsity=force
[09/16/2022-10:02:02] [I] [TRT] (Sparsity) Layers eligible for sparse math: Conv_22
[09/16/2022-10:02:02] [I] [TRT] (Sparsity) TRT inference plan picked sparse implementation for layers:
I think there should have more MatMul sparsity according to this issue https://github.com/NVIDIA/TensorRT/issues/2169
This issue has not seen activity for 90 days, Remove stale label or comment or this will be closed in 10 days