pyppeteer
 pyppeteer copied to clipboard
pyppeteer copied to clipboard
How to handle onclick attributes of anchor tags?
import asyncio
from pyppeteer import launch
async def extract_data(url):
browser = await launch({'headless' : True})
page = await browser.newPage()
await page.goto(url, timeout=1000000)
elements = await page.xpath('//td/a[@onclick]')
for element in elements:
'''
html = await page.evaluate('element => element.click()')
print(html)
'''
stuff = await page.click(element)
asyncio.get_event_loop().run_until_complete(extract_data('https://ngodarpan.gov.in/index.php/home/sectorwise_ngo/15838/2/1'))
The above code results in the following error.
Traceback (most recent call last):
File "testppterr.py", line 20, in <module>
asyncio.get_event_loop().run_until_complete(extract_data('https://ngodarpan.
gov.in/index.php/home/sectorwise_ngo/15838/2/1'))
File "C:\Anaconda3\envs\darpan\lib\asyncio\base_events.py", line 568, in run_u
ntil_complete
return future.result()
File "testppterr.py", line 19, in extract_data
stuff = await page.click(element)
File "C:\Anaconda3\envs\darpan\lib\site-packages\pyppeteer\page.py", line 1546
, in click
await frame.click(selector, options, **kwargs)
File "C:\Anaconda3\envs\darpan\lib\site-packages\pyppeteer\frame_manager.py",
line 581, in click
handle = await self.J(selector)
File "C:\Anaconda3\envs\darpan\lib\site-packages\pyppeteer\frame_manager.py",
line 317, in querySelector
value = await document.querySelector(selector)
File "C:\Anaconda3\envs\darpan\lib\site-packages\pyppeteer\element_handle.py",
line 360, in querySelector
self, selector,
File "C:\Anaconda3\envs\darpan\lib\site-packages\pyppeteer\execution_context.p
y", line 113, in evaluateHandle
helper.getExceptionMessage(exceptionDetails)))
pyppeteer.errors.ElementHandleError: Evaluation failed: DOMException: Failed to
execute 'querySelector' on 'Document': 'javascript:void(0)' is not a valid selec
tor.
at __pyppeteer_evaluation_script__:1:33
The href of the anchor tag is set to javascript:void(0) and has a onclick attribute that invokes a JS function, how do I access the html of the pop-up that comes after clicking the link? @miyakogi @beenje
I made some progress. Please take a look at the code and error report @miyakogi
sync def extract_data(url):
browser = await launch({'headless' : False})
page = await browser.newPage()
await page.coverage.startJSCoverage()
await page.goto(url, timeout=1000000)
elements = await page.xpath('//td/a/@onclick')
for element in elements:
await page.evaluate(element, 'element => (element as HTMLElement).click()')
break
asyncio.get_event_loop().run_until_complete(extract_data('https://ngodarpan.gov.in/index.php/home/sectorwise_ngo/15838/2/1'))
Here's the website screenshot
before clicking:
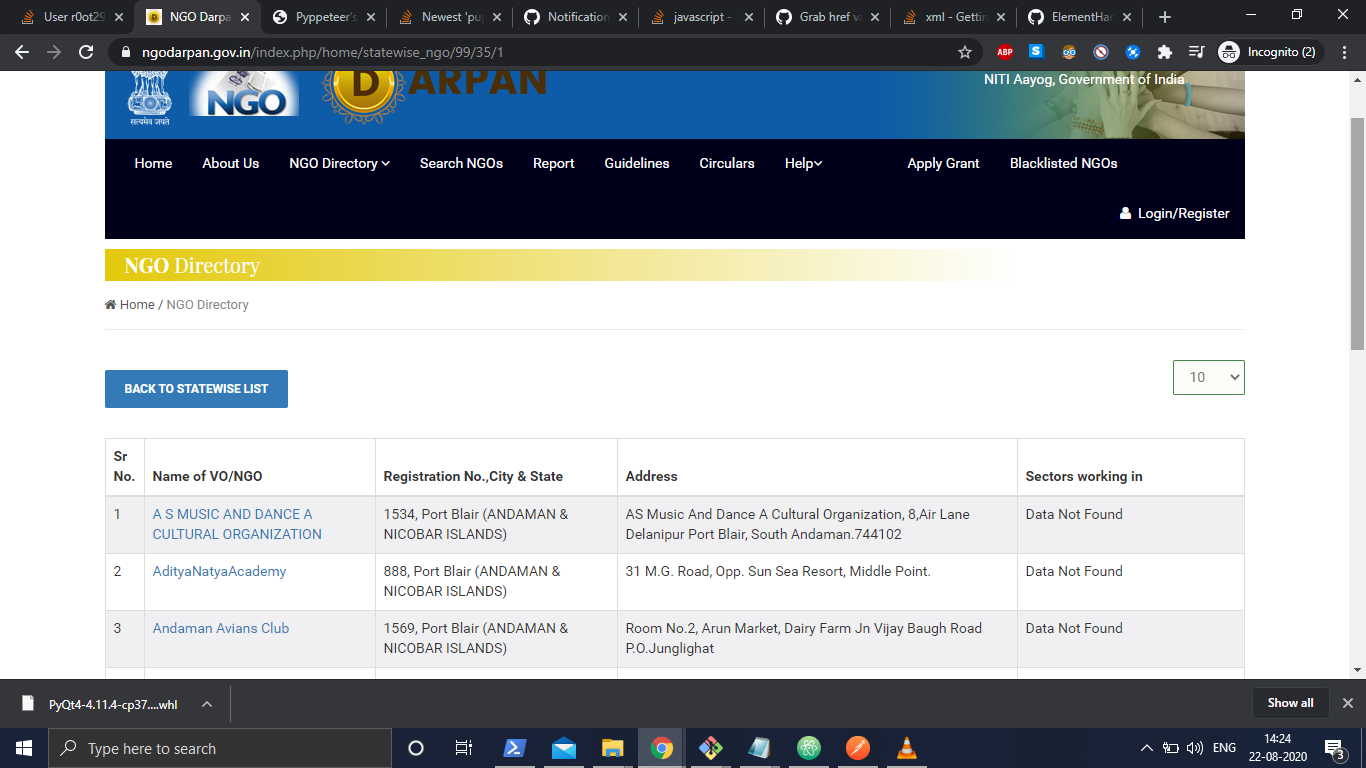
The Name of NGO/VO column includes its name as a link.
after clicking:
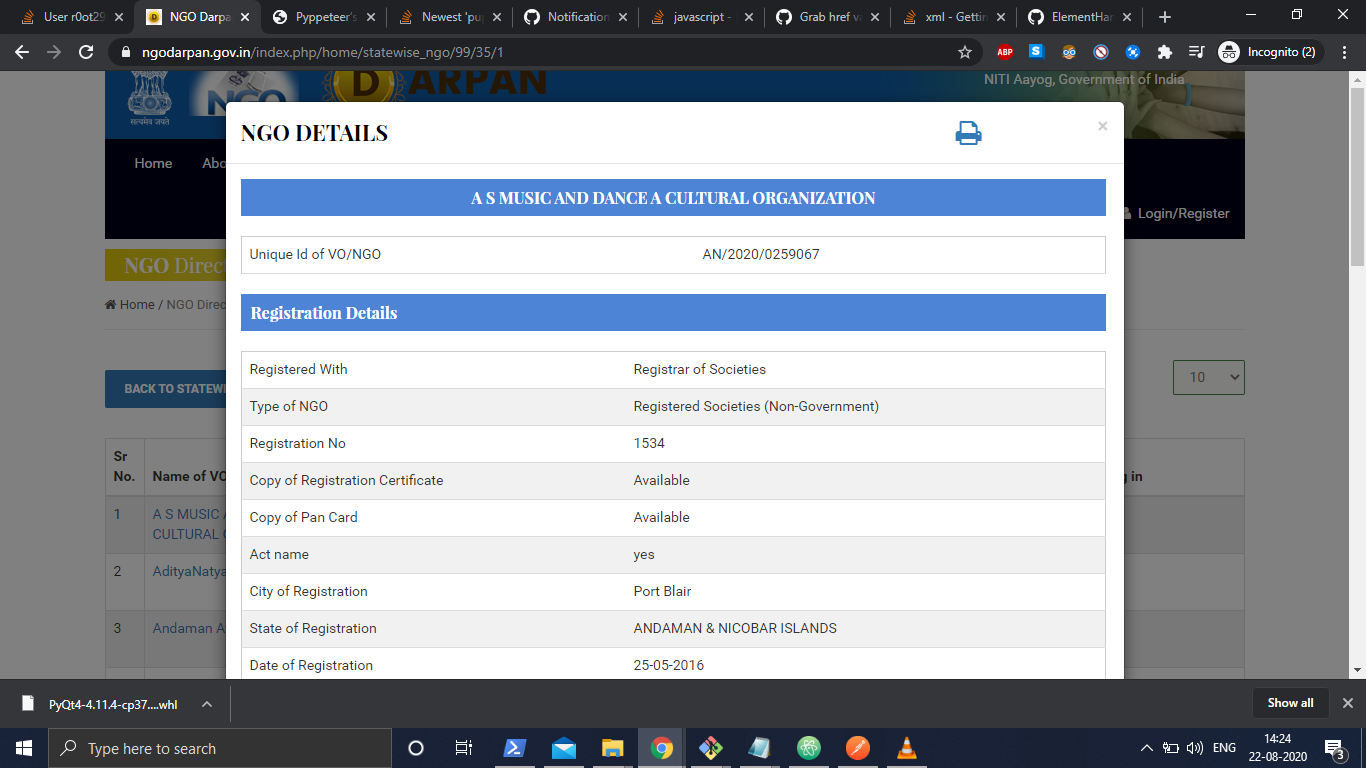
Sorry for comment a long time.I use pyppeteer and have this issue too.
You can try the code like this:
await page.evaluate('''handle => handle.click()''', some_handle)
some_handle is a 'element_handle' you get from xpath(), querySelector().This working for me on pyppeteer 0.2.5 with py3.8.
In your method may like this:
await page.evaluate('''handle => handle.click()''', element)
We know that this problem caused by dynamic DOM elememt, when your page has navigation etc.. the dom will change and old elementhandle will expired in pyppeteer, but can excute in page's js.
I'm not sure what's the correct expression in page.evaluate(). Pyppeteer's offical reference not exactly, and this just worked for me.