Chinese_LLM_From_Scratch
 Chinese_LLM_From_Scratch copied to clipboard
Chinese_LLM_From_Scratch copied to clipboard
从零手搓中文大模型计划
项目简介
心血来潮想要走一遍大模型训练的流程,于是有了这个项目。
由于我自己只有一张3090,也不好用单位的显卡,所以训练只能选很小的模型。
其实我自己对SLM是很感兴趣的,感觉现在也有越来越多地研究开始关注小尺寸大模型的性能以及如何把大模型做小。
如果是希望学习大规模并行训练相关的内容(例如DeepSpeed,Megatron),这个项目可能不太适合你。
另外个人经历和精力有限,所以可能很多地方做的不是很好,请大家多多包涵。也欢迎大家提出意见和建议。
最后给自己的自媒体号打个广告,欢迎大家关注一波~(公众号/B站/小红书/抖音:喵懂AI)

最近更新
2024-09-25
上传了Day12 - Day13的内容:Day12:litgpt模型转换到huggingface格式Day13:DPO训练
2024-09-20
上传了Day10 - Day11的内容:Day10: 中秋特刊,自己关于大模型的一些思考Day11:DPO数据构建
2024-09-12
上传了Day07 - Day09的内容:Day07:SFT数据构建Day08:SFT训练相关知识点调研Day09:SFT训练及效果测试
2024-09-02
上传了Day01 - Day05的内容:Day01: 项目调研Day02:Tokenizer分词Day03: 数据预处理Day04: 模型搭建和预训练启动Day05: 预训练效果测试
计划执行
在一个垂直领域的小数据集上完成:
- [x] 一个小尺寸模型的预训练(能在单卡上跑)
- [x] 在上面的基础上完成指令微调
- [x] 在上面的基础上完成
DPO - [ ] 其他待定
Journey文件夹下有每次任务的详细记录。
下载相应的文件(chatglm的tokenizer,TinyStoriesChinese的数据集)之后,可以跟着Journey中的步骤一步步来。
理论上可以复现已经放出的结果(GPU如果比我还小的,需要自己调整下batch_size)。
训练信息
机器配置:
OS: Ubuntu 22.04.3 LTS x86_64
Kernel: 6.5.0-35-generic
Uptime: 60 days, 4 hours, 55 mins
Packages: 2719 (dpkg), 17 (snap)
Shell: fish 3.6.1
Terminal: WezTerm
CPU: AMD Ryzen 9 5950X (32) @ 3.400G
GPU: NVIDIA 09:00.0 NVIDIA Corporati
Memory: 9347MiB / 64195MiB
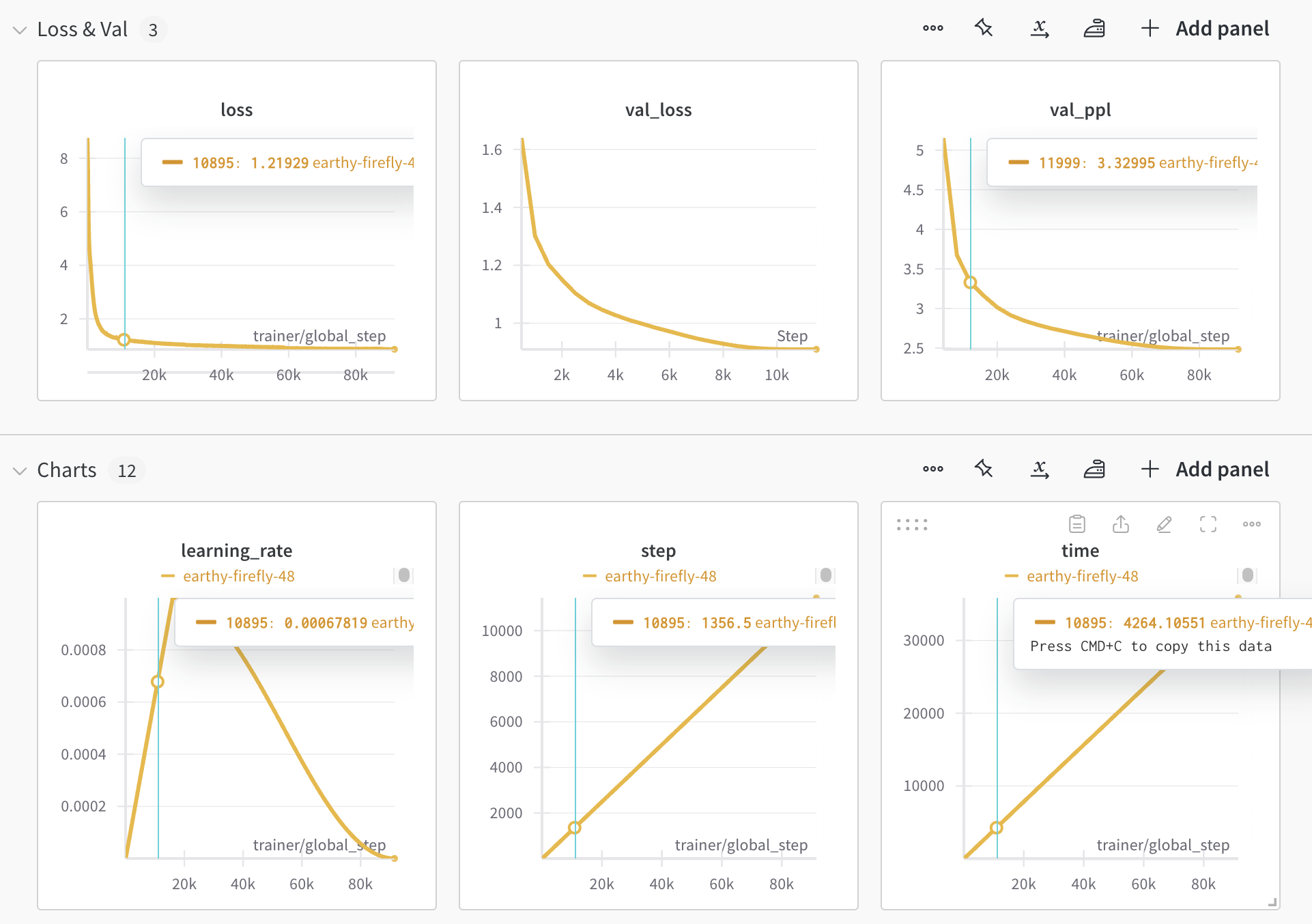
预训练
详细参数请参考 pretrain.yaml。
指令微调
详细参数请参考 sft.yaml。
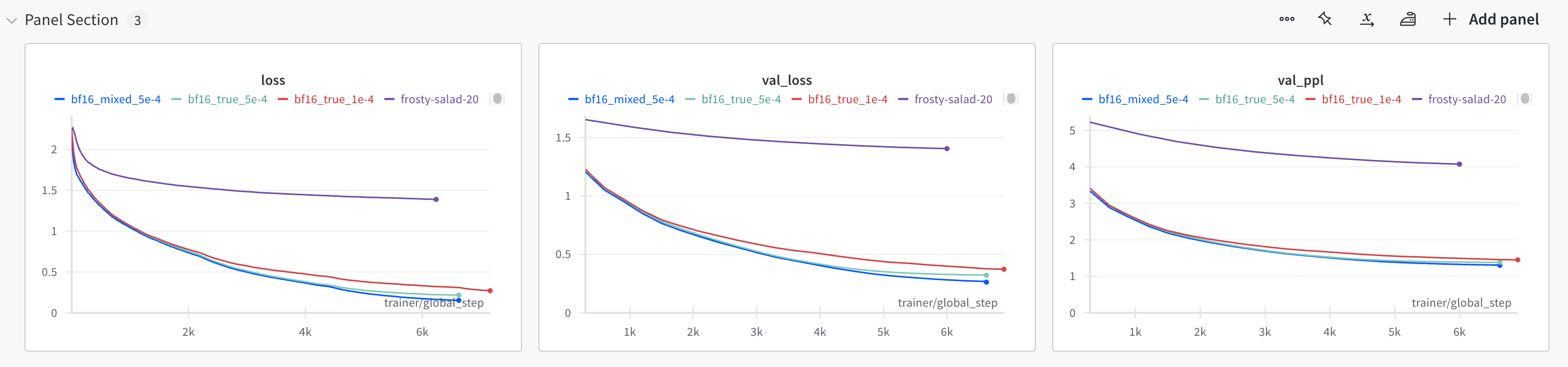
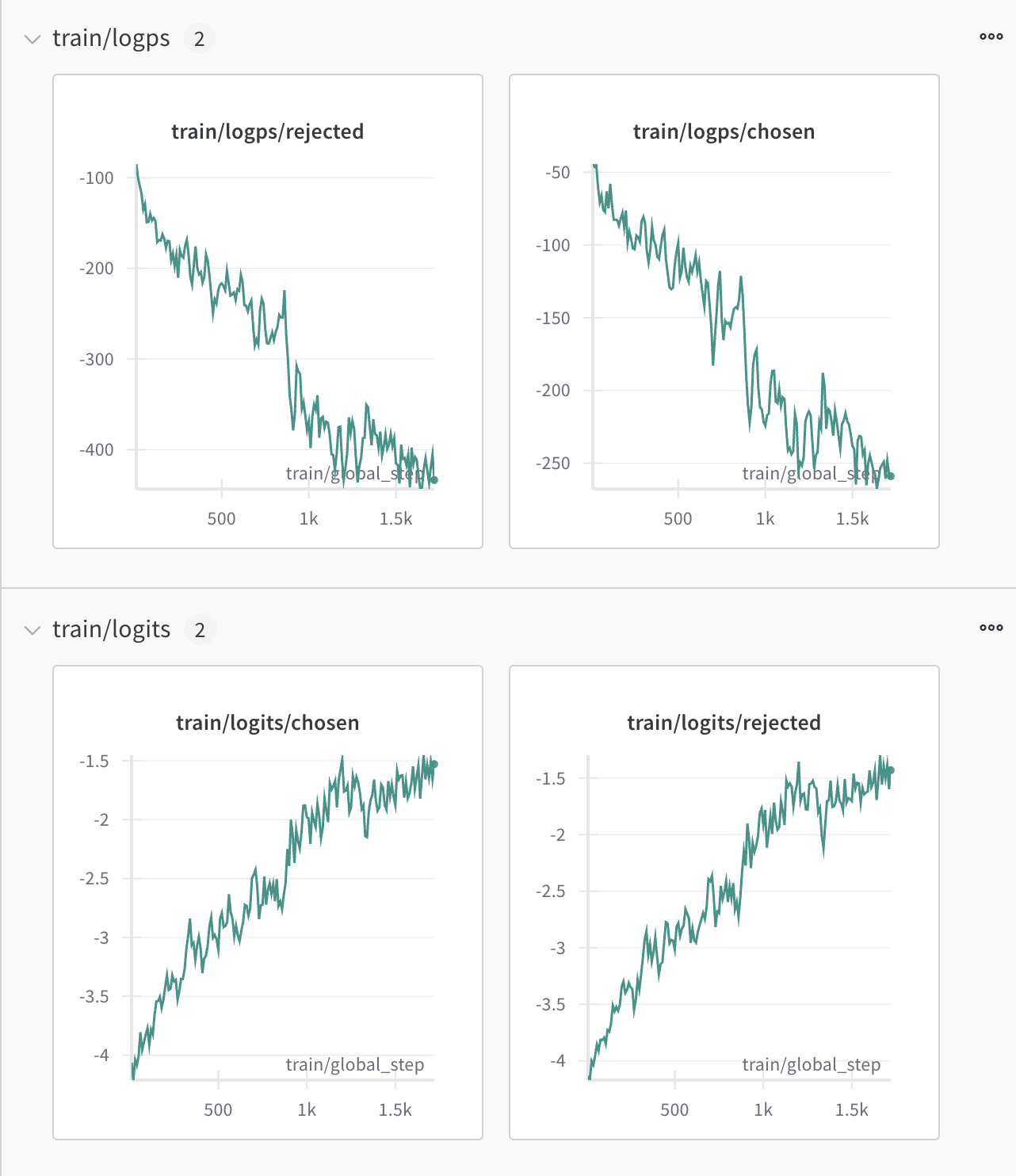
DPO
训练脚本参考dpo_train.py
目录结构
Chinese_LLM_From_Scratch
├── Data
│ └── TinyStoriesChinese
│ ├── processed_data
│ └── raw_data
├── Experiments
│ ├── configs
│ │ ├── debug.yaml
│ │ ├── microstories.yaml
│ │ └── ...
│ └── Output
│ └── pretrain
│ ├── debug
│ └── microstories
├── References
│ ├── chatglm3-6b
│ └── ...
├── Journey
│ ├── Day01
│ ├── Day02
│ ├── Day03
│ ├── Day04
│ └── ...