alertmanager
 alertmanager copied to clipboard
alertmanager copied to clipboard
Minimum value for repeat_interval
So I was playing around with alertmanager and tried to set repeat_interval : 1m for an webhook endpoint. With this configuration alerts repeated in 5m duration. When I changed the repeat_interval to 7m, alerts repeated in 10m duration. So is it by design that minimum repeat interval is 5m and anything above would be factor of 5m? Or am I missing something? Can I override this behavior?
Hi @soumyadipDe, thanks for reporting. I am not aware of this being by design. I will dig further into it. Can you provide your full Alertmanager config so I can reproduce the issue better?
Question on the side: What is your use case for setting the repeat interval so low?
I can't find it in the code now, but we did add some safety to deal with users trying to set the repeat_interval to 0. There's also a restriction that the repeat_interval must be at least the group_interval.
The use case being creation of auto-scaling of docker containers based on load on each container and repeating the alert after ~ 3m for re-scaling if scaling didn't reduce load as per expectation. For now, I explicitly mentioned group_interval: 1m and put repeat_interval: 3m following comment from @brian-brazil which causes repeating of alert every 4m which is acceptable for our case.
Hello! Sorry for reopening old issue, but it still unclear. I am trying to have 5m repeat_interval.
My route has:
group_interval: 5m
repeat_interval: 5m
However still I can see 10m for some reason (I have 27 alerts, opsgenie integration):

No failures:
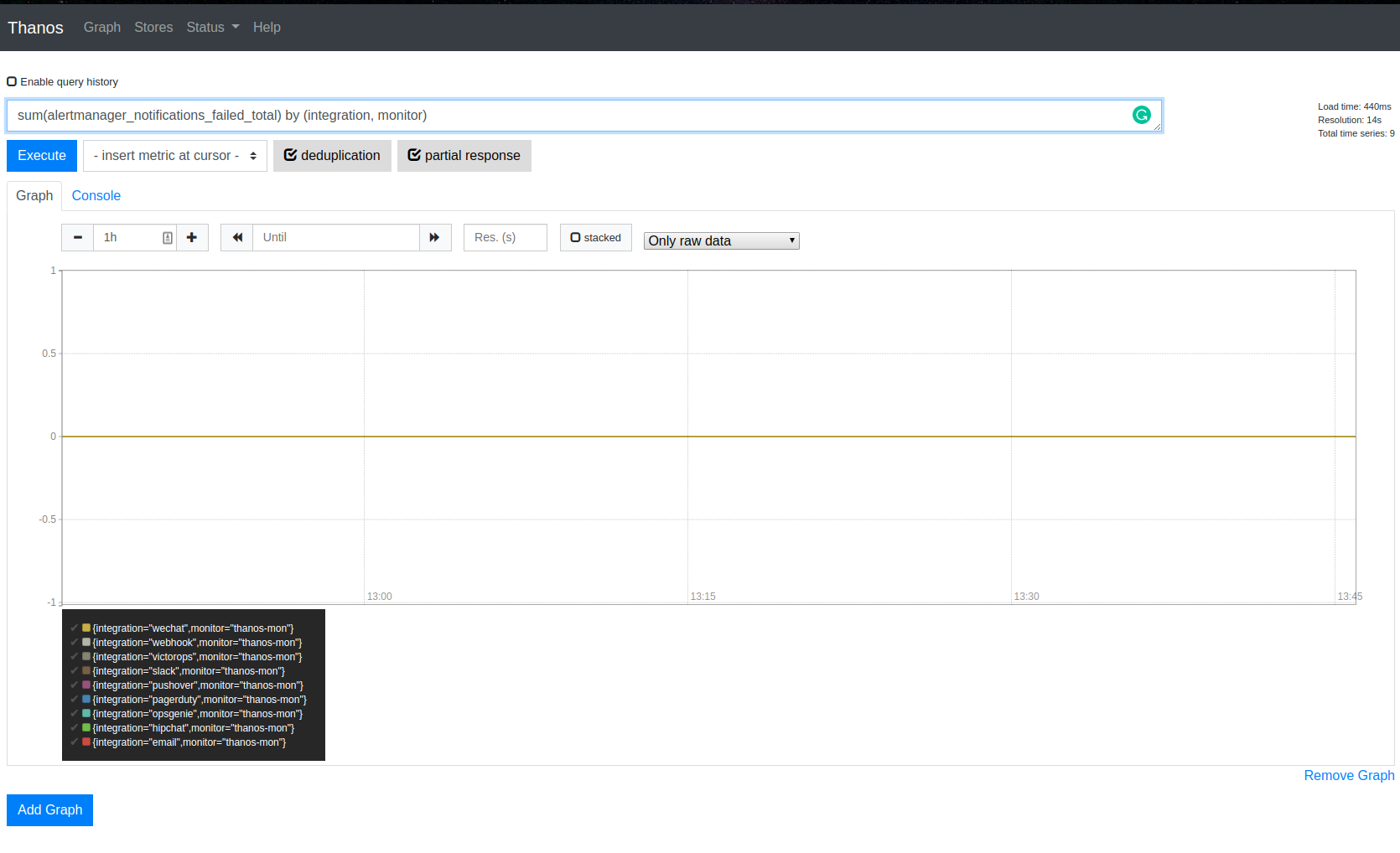
Any ideas what this repeat_interval depends on as well?
Happy to look into code if there is nothing obvious but bit busy now.
group_interval defines how frequently AlertManager will evaluate the alert groups.
The logic defining whether AlertManager should notify or not is (mostly) here:
https://github.com/prometheus/alertmanager/blob/ab11da7c3a05b0251919ff6317092fc06f77c05f/notify/notify.go#L511-L539
repeat_interval kicks in only if the last notification has been sent more than 5m ago but given that the delta is the current time minus the time when AlertManager logged the notification as being successfully sent, it is likely that less than 5 minutes have elapsed. Hence you have to wait 2 group_interval periods.
After a quick test, nothing prevents repeat_interval to be less than group_interval and it might solve your request. The other way is to have a shorter group_interval (eg 1m) in which case the repeated notification will be sent every 6 minutes at most.
After a quick test, nothing prevents repeat_interval to be less than group_interval and it might solve your request.
That doesn't sound right. This sounds like a race.
Having a repeat_interval less than group_interval should result in a notification being sent each group_interval. Setting the two to be equal to force this behavior seems to make sense in my mind, but that probably results in a race condition as this is never explicitly configured in the code.
Perhaps we want to add this?
return (repeatInterval <= groupInterval) || entry.Timestamp.Before(n.now().Add(-repeat))
Thanks for explaining this guys. I think indeed it would be nice to have repeat interval to be clear. IMO either:
A) repeatInterval should be totally asyncronous to group interval (which probably would increase complexity)
B) repeatInterval should be somehow defined as the multipler of group interval, so something like repeatSampling that will tell how many of groupIntervals should actually notify if no change happend and the alert is firing. So is it 1 (1:1) or 0.2 (1:5) or 0.1 (1:10) etc.. so if the repeatSampling is 0.25 and group interval 5m, repeat will be every 20m (: That would be the most explicit given the current sync implementation.
Happy to put a PR for B if that makes sense.
Or just being explicit that repeat_interval has to be multipler of group_interval but we need to solve the race in this case.
The most confusing part of this story for me is that I need to set group_interval: 1s even if I "effectively disables aggregation entirely, passing through all alerts as-is" by setting group_by to special value '[...]'
I was reading through old issues and found this discussion. I also observed the same behavior and have been wondering for a while if this is how repeat_interval is supposed to work? It sounds to me like the current behavior might be an implementation artifact rather than a design choice? Nonetheless, I updated the docs a month ago to better explain how it works https://github.com/prometheus/alertmanager/pull/3552.
Yes, this does not sound right @fabxc @stuartnelson3 @simonpasquier @juliusv
In case group_interval: 3h and repeat_interval: 6 hours, then effectively my repeat_interval is 9 hours.
If i lower down the group_interval to 5 minutes in order to get close to repeat_interval (6 hours 5 minutes) then i or my integrations ( slack/opsgenie) get spammed.
Also, In case if i am interested only in repeat_interval , and do not need group_interval, how do i express this via configurations?
The grafana alert manager has a fix for this ? i am planning to evaluate grafana alert manager.