[prometheus-kube-stack] admission-webhooks last-applied-configuration missing
Describe the bug a clear and concise description of what the bug is.
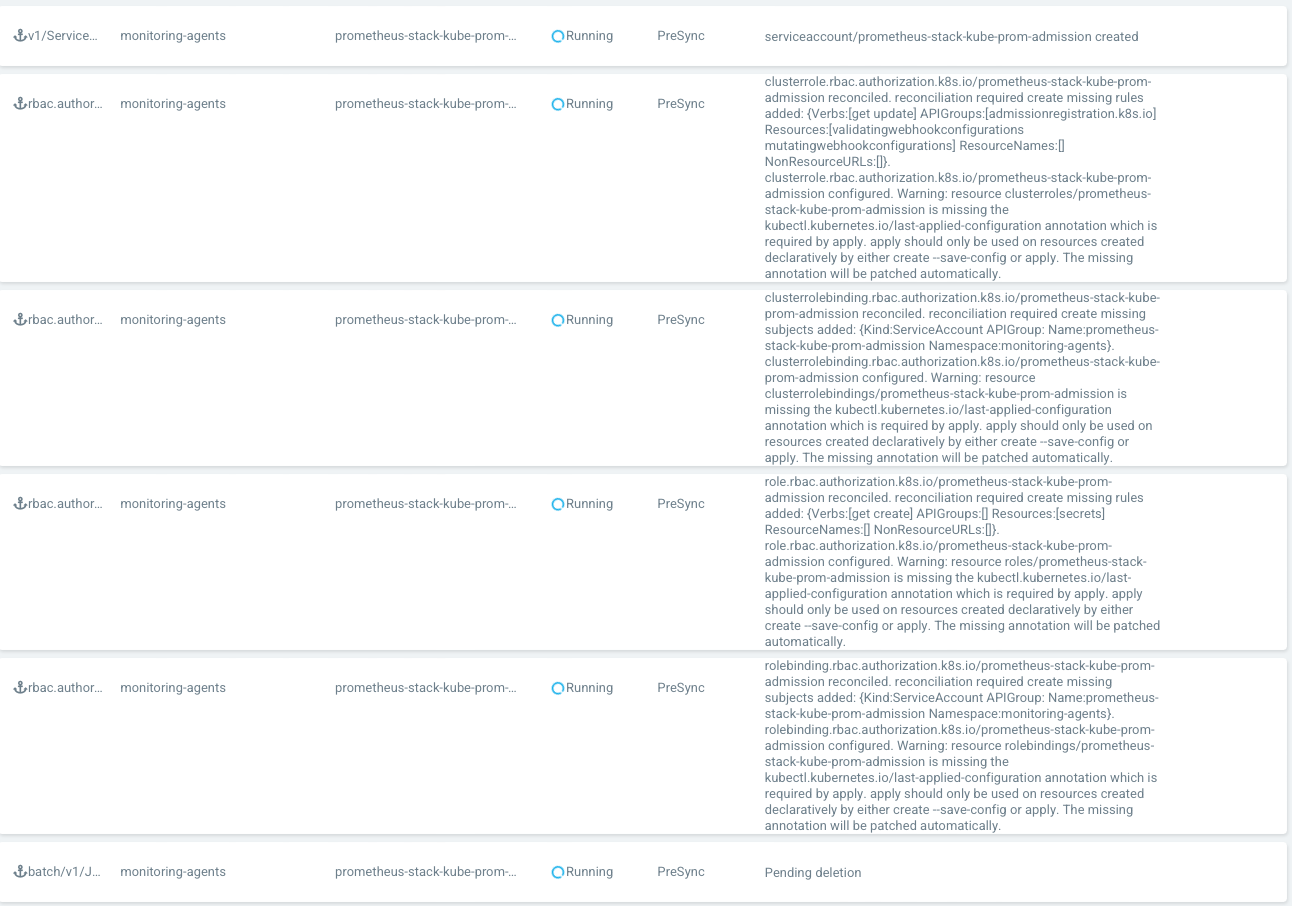
Deploying the chart via ArgoCD produces an error resource clusterroles/<deployment name>-admission is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by apply for all the admission jobs
clusterrole.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission reconciled. reconciliation required create missing rules added: {Verbs:[get update] APIGroups:[admissionregistration.k8s.io] Resources:[validatingwebhookconfigurations mutatingwebhookconfigurations] ResourceNames:[] NonResourceURLs:[]}. clusterrole.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission configured. Warning: resource clusterroles/prometheus-stack-kube-prom-admission is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by apply. apply should only be used on resources created declaratively by either create --save-config or apply. The missing annotation will be patched automatically.
clusterrolebinding.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission reconciled. reconciliation required create missing subjects added: {Kind:ServiceAccount APIGroup: Name:prometheus-stack-kube-prom-admission Namespace:monitoring-agents}. clusterrolebinding.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission configured. Warning: resource clusterrolebindings/prometheus-stack-kube-prom-admission is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by apply. apply should only be used on resources created declaratively by either create --save-config or apply. The missing annotation will be patched automatically.
role.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission reconciled. reconciliation required create missing rules added: {Verbs:[get create] APIGroups:[] Resources:[secrets] ResourceNames:[] NonResourceURLs:[]}. role.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission configured. Warning: resource roles/prometheus-stack-kube-prom-admission is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by apply. apply should only be used on resources created declaratively by either create --save-config or apply. The missing annotation will be patched automatically.
rolebinding.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission reconciled. reconciliation required create missing subjects added: {Kind:ServiceAccount APIGroup: Name:prometheus-stack-kube-prom-admission Namespace:monitoring-agents}. rolebinding.rbac.authorization.k8s.io/prometheus-stack-kube-prom-admission configured. Warning: resource rolebindings/prometheus-stack-kube-prom-admission is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by apply. apply should only be used on resources created declaratively by either create --save-config or apply. The missing annotation will be patched automatically.
searching the issues on the repo I only found references to the CRDs that I deployed as mentioned in the documentation.
What's your helm version?
version.BuildInfo{Version:"v3.9.0", GitCommit:"7ceeda6c585217a19a1131663d8cd1f7d641b2a7", GitTreeState:"clean", GoVersion:"go1.18.2"}
What's your kubectl version?
Client Version: version.Info{Major:"1", Minor:"24", GitVersion:"v1.24.1", GitCommit:"3ddd0f45aa91e2f30c70734b175631bec5b5825a", GitTreeState:"clean", BuildDate:"2022-05-24T12:17:11Z", GoVersion:"go1.18.2", Compiler:"gc", Platform:"darwin/arm64"}
Which chart?
kibe-prometheus-stack
What's the chart version?
35.0.3
What happened?
Updating the chart configuration via ArgoCD produces an endless sync status due to the pre-sync hooks unable to complete.
What you expected to happen?
Admission hooks finish successfully
How to reproduce it?
Deploy kibe-prometheus-stack with default admission settings via ArgoCD
Enter the changed values of values.yaml?
Click to expand!
defaultRules:
create: true
rules:
alertmanager: true
etcd: false
configReloaders: true
general: true
k8s: true
kubeApiserver: true
kubeApiserverAvailability: true
kubeApiserverSlos: true
kubelet: true
kubeProxy: false
kubePrometheusGeneral: true
kubePrometheusNodeRecording: true
kubernetesApps: false
kubernetesResources: true
kubernetesStorage: true
kubernetesSystem: true
kubeScheduler: false
kubeStateMetrics: true
network: true
node: true
nodeExporterAlerting: true
nodeExporterRecording: true
prometheus: true
prometheusOperator: true
additionalRuleLabels:
cloud: gcp
env: staging
kube-state-metrics:
prometheus:
monitor:
enabled: true
honorLabels: true
additionalLabels:
cluster: staging-application-cluster
release: kube-prometheus-stack
env: staging
alertmanager:
enabled: true
extraSecret:
name: alertmanager-auth
data:
auth: <path:kv/data/infrastructure/monitoring/alertmanager#grafana_basic_auth_htpassword>
alertmanagerSpec:
replicas: 2
storage:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
config:
global:
slack_api_url: '<path:kv/data/infrastructure/monitoring/alertmanager#slack_api_url>'
receivers:
- ...
route:
group_by: ['alertname', 'severity']
group_wait: 10s
group_interval: 5m
receiver: "slack-staging-sre"
repeat_interval: 3h
routes:
- ...
inhibit_rules:
- source_matchers: [severity="critical"]
target_matchers: [severity="warning"]
ingress:
enabled: true
ingressClassName: nginx
annotations:
kubernetes.io/tls-acme: "true"
cert-manager.io/cluster-issuer: "letsencrypt-issuer"
external-dns.alpha.kubernetes.io/hostname: ****
external-dns.alpha.kubernetes.io/ttl: "120"
nginx.ingress.kubernetes.io/auth-type: "basic"
nginx.ingress.kubernetes.io/auth-secret: "alertmanager-auth"
hosts:
- ****
tls:
- secretName: alertmanager-general-tls
hosts:
- ****
prometheus:
thanosServiceExternal:
enabled: true
loadBalancerIP: <path:kv/data/infrastructure/clusters/application#ingress>
prometheusSpec:
externalLabels:
cloud: gcp
env: staging
Enter the command that you execute and failing/misfunctioning.
Installed via ArgoCD
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: prometheus-stack
namespace: argo-cd
annotations:
argocd.argoproj.io/sync-wave: "10"
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
destination:
server: https://kubernetes.default.svc
namespace: monitoring-agents
project: monitoring-agents
source:
path: charts/monitoring/kube-prometheus-stack
repoURL: https://github.com/****
targetRevision: HEAD
plugin:
name: argocd-vault-plugin-helm
env:
- name: ARGOCD_APP_NAMESPACE
value: $ARGOCD_APP_NAMESPACE
- name: HELM_ARGS
value: -f ../../../staging-application-cluster/monitoring-agents/kube-prometheus-stack.yaml --skip-crds
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
Anything else we need to know?
No response
It looks like the job *-admission-create is failing with secret already exists
W0720 15:57:51.766034 1 client_config.go:615] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
{"level":"info","msg":"secret already exists","source":"cmd/create.go:33","time":"2022-07-20T15:57:51Z"}
and I can verify the secret does exists
$ k get secrets -n monitoring-agents prometheus-stack-kube-prom-admission
NAME TYPE DATA AGE
prometheus-stack-kube-prom-admission Opaque 3 121d
As I could not find a way around it, I switched to use cert-manager and it solved the issue
I deleted the secret but that not help, the secret is re-created but the job still fail without any log error
$ kubeclt logs kube-prometheus-stack-admission-create-t48kf W0801 14:15:55.854314 1 client_config.go:615] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. {"err":"secrets \"kube-prometheus-stack-admission\" not found","level":"info","msg":"no secret found","source":"k8s/k8s.go:229","time":"2022-08-01T14:15:55Z"} {"level":"info","msg":"creating new secret","source":"cmd/create.go:28","time":"2022-08-01T14:15:55Z"}
$ kubeclt get jobs NAME COMPLETIONS DURATION AGE kube-prometheus-stack-admission-create 0/1 3m16s 3m17s
Kub version : 1.23.5
Which chart? kube-prometheus-stack
What's the chart version? 39.2.1
I suspect that issue is linked to this one => https://github.com/prometheus-community/helm-charts/issues/1820
I switch also to cert manager as work around
prometheusOperator:
admissionWebhooks:
certManager:
enabled: true
patch:
enabled: false
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Any further update will cause the issue/pull request to no longer be considered stale. Thank you for your contributions.
Updating the chart configuration via ArgoCD produces an endless sync status due to the pre-sync hooks unable to complete.
We had the same problem. I think this is caused by ArgoCD when using prune. ArgoCD will prune any object (i.e. job/pod) that is not part of the deployment. Since the jobs/pods for the admission hook are created dynamically and art not part of the deployment, they just get deleted and recreated endlessly.
syncOptions:
- CreateNamespace=true
- ServerSideApply=true
+ # Prune Last (i.e. after it was synced) to not removed dynamically created admissions/patch jobs/pods
+ - PruneLast=true