polars
 polars copied to clipboard
polars copied to clipboard
'n_rows' not respected in reading / scanning .csv files
Polars version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of polars.
Issue Description
It seems that 'n_rows' in loading .csv files is not currently respected - it seems to load the dataset fully into memory and chunk it afterwards.
This holds for both 'read_csv' and 'scan_csv'...collect() - for .parquet files the 'n_rows' does work.
Below is an example of polars (37 seconds) versus pandas (0.14 seconds).

Reproducible Example
import polars as pl
tic = time.perf_counter()
df2 = pl.read_csv("large_csv_file.csv",n_rows=10)
toc = time.perf_counter()
seconds_taken = round(toc - tic, 3)
print(f"seconds taken: {seconds_taken}")
Expected Behavior
The .csv dataset with n_rows = 10 should load instantly.
Installed Versions
Can you share the example file or at least the first 20 lines or so?
n_rows works in general, but apparently not all the time.
I have a file with 52 rows of garbage at the top (commented). Depending on the chosen delimiter it respects n_rows and is fast or not.
In [84]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep=",", skip_rows=0, n_rows=300)
CPU times: user 2.24 ms, sys: 40.6 ms, total: 42.9 ms
Wall time: 41 ms
In [83]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep="\t", skip_rows=0, n_rows=300)
CPU times: user 7.05 s, sys: 719 ms, total: 7.77 s
Wall time: 7.76 s
In [97]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep="\t", skip_rows=0, n_rows=300, comment_char="#")
CPU times: user 5.44 ms, sys: 873 µs, total: 6.32 ms
Wall time: 1.68 ms
In [86]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep=",", skip_rows=52, n_rows=300)
CPU times: user 1.47 ms, sys: 0 ns, total: 1.47 ms
Wall time: 557 µs
In [87]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep="\t", skip_rows=52, n_rows=300)
CPU times: user 5.59 ms, sys: 586 µs, total: 6.18 ms
Wall time: 1.74 ms
In [92]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep="d", skip_rows=0, n_rows=300)
CPU times: user 5.56 s, sys: 3.04 s, total: 8.6 s
Wall time: 8.6 s
In [93]: %time df = pl.read_csv("test_with_52rows_to_skip.tsv", sep="\t", skip_rows=52)
CPU times: user 20.8 s, sys: 4.41 s, total: 25.2 s
Wall time: 3.49 s
It must be something with the file indeed, I cannot share content from that particular file unfortunately. If I try to replicate it, e.g. with the following, n_rows does work:
df = pd.DataFrame(np.random.choice(['foo','bar','baz'], size=(4000000,60)))
df.to_csv('test.csv',index=False)
tic = time.perf_counter()
df = pl.read_csv('test.csv',n_rows = 10)
toc = time.perf_counter()
seconds_taken = round(toc - tic, 3)
print(f"seconds taken: {seconds_taken}")
tic = time.perf_counter()
df = pl.read_csv('test.csv',n_rows = None)
toc = time.perf_counter()
seconds_taken = round(toc - tic, 3)
print(f"seconds taken: {seconds_taken}")
We sample statistics. They must be completely off for your file.
Could you maybe send your file if you replaced all character with an a? Except for the delimiter and the new line characters.
It looks like you are reading from a local directory, but it's worth noting that some filesystems that are commonly used for remote storage don't allow partial file reads. Specifically, WebDAV is one of those. When this is the case, anything that relies on partial reads becomes painfully slow (such as pl.scan_*, pl.read_schema, or n_rows=), since the system has to load the entire file regardless.
It looks like you are reading from a local directory, but it's worth noting that some filesystems that are commonly used for remote storage don't allow partial file reads. Specifically, WebDAV is one of those. When this is the case, anything that relies on partial reads becomes painfully slow (such as pl.scan_*, pl.read_schema, or n_rows=), since the system has to load the entire file regardless.
Good observation. @matteha does the issue persist if you read the csv file from NOT a dropbox folder?
Thanks for the suggestions. It also persists indeed when off-Dropbox:
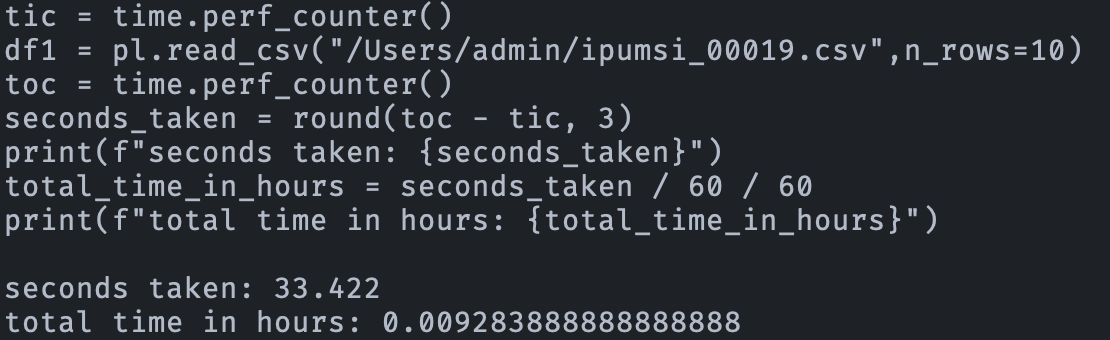
Looking into replacing all the chars now to be able to share the file.
Seeing the same here (slightly different versions: python 3.7 and polars 0.14.6)
It could have something to do with the number of columns being inconsistent. Say a 10G csv with 12 columns for 99% of the rows, except the remaining say 1% of rows have only 3 columns (the csv is produced by an external app and there is no way to suppress these 3-column error rows)
Seeing the same here (slightly different versions: python 3.7 and polars 0.14.6)
It could have something to do with the number of columns being inconsistent. Say a 10G csv with 12 columns for 99% of the rows, except the remaining say 1% of rows have only 3 columns (the csv is produced by an external app and there is no way to suppress these 3-column error rows)
Have you tried latest version?
Have you tried latest version?
Thanks for the reply - 0.14.25 works beautifully, didn't realize there were so many releases in such a short time.
Seeing a huge speedup and RAM usage stable even with an 80gig csv (loaded in slices).
Awesome library. Thanks