polars
 polars copied to clipboard
polars copied to clipboard
Optimize python imports
Problem Description
Our optional dependencies influence our import time. Pandas import is ~500ms!!
Import times:
only polars installed:
0.268s
polars + pandas installed
0.755s
We should explore if we can do this lazily.


I remember that numpy used to take around 1 second to import in the past (which is quite noticeble when you just want to display the help of a script). So it might be that most of the pandas time comes from this.
I remember that numpy used to take around 1 second to import in the past (which is quite noticeble when you just want to display the help of a script). So it might be that most of the pandas time comes from this.
I think we should lazy import all of these. I expect pyarrow also does non trivial work. Our polars.testing also seems unnecessary.
importlib.set_lazy_imports() looks interesting.
Indeed!
There is also pyforest which does not require importing the modules yourself at all, till you call the function: https://medium.com/@virajmane02/pyforest-lazy-import-of-python-data-science-libraries-72428be0299b
But I assume it will not play nicely with typechecking and linting if enabled unconditionally.
There is also
pyforestwhich does not require importing the modules yourself at all, till you call the function: https://medium.com/@virajmane02/pyforest-lazy-import-of-python-data-science-libraries-72428be0299b But I assume it will not play nicely with typechecking and linting if enabled unconditionally.
I don't think I like that idea. I think we could do something like this:
if TYPE_CHECKING:
import numpy as np
def numpy_available() -> bool:
try:
import numpy
return True
except ImportError:
return False
def get_np() -> np:
import numpy
Which is our current behavior behind function calls. If I am correct we only pay the import cost once.
importlib.set_lazy_imports() looks interesting.
Cool, I didn't know about this PEP! Thanks for linking it.
Taking advantage of this would take some thought and rewriting, though. Enabling this would indeed improve the initial import time, but you'd 'pay back' that time upon the first invocation of a class/function in a module where pandas is imported. And since we import pandas in most of the major modules (io, frame, series), you won't get around it easily.
Taking advantage of this would take some thought and rewriting, though. Enabling this would indeed improve the initial import time, but you'd 'pay back' that time upon the first invocation of a class/function in a module where pandas is imported. And since we import pandas in most of the major modules (io, frame, series), you won't get around it easily.
But we rarely use it. Only on certain branches if all other branches fail. You only pay back this import time when you:
- pass a pandas dataframe (then the user already imported pandas, so no payback at all).
- call to_pandas() (which might pay the import cost once if the user did not import it already).
Both cases are far better than always paying it if it is installed in the environment.
Lazy imports are great - the only issue is where you want to know up-front if a certain module is available (eg: setting _PANDAS_AVAILABLE, etc), as that is currently determined by actually trying the import. (There are a few different techniques for doing lazy import; some can actually add overhead to each call into the lazy-loaded module, so good to be aware of that and check/benchmark beforehand).
Lazy imports are great - the only issue is where you want to know up-front if a certain module is available (eg: setting
_PANDAS_AVAILABLE, etc), as that is currently determined by actually trying the import. (There are a few different techniques for doing lazy import; some can actually add overhead to each call into the lazy-loaded module, so good to be aware of that and check/benchmark beforehand).
Could we get that information without importing those modules?
importlib.util.find_spec("pandas") might be a solution to set _PANDAS_AVAILABLE:
In [1]: import importlib
In [2]: %time importlib.util.find_spec("numpy")
CPU times: user 204 µs, sys: 12 µs, total: 216 µs
Wall time: 146 µs
Out[2]: ModuleSpec(name='numpy', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7f50f10df280>, origin='/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/numpy/__init__.py', submodule_search_locations=['/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/numpy'])
In [3]: %time importlib.util.find_spec("numpy")
CPU times: user 356 µs, sys: 0 ns, total: 356 µs
Wall time: 231 µs
Out[3]: ModuleSpec(name='numpy', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7f50eb04a4c0>, origin='/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/numpy/__init__.py', submodule_search_locations=['/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/numpy'])
In [4]: %time importlib.util.find_spec("pandas")
CPU times: user 212 µs, sys: 12 µs, total: 224 µs
Wall time: 154 µs
Out[4]: ModuleSpec(name='pandas', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7f50f10df0a0>, origin='/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/pandas/__init__.py', submodule_search_locations=['/home/luna.kuleuven.be/u0079808/software/anaconda3/envs/polars_test/lib/python3.9/site-packages/pandas'])
In [5]: %time importlib.util.find_spec("pandas2")
CPU times: user 175 µs, sys: 0 ns, total: 175 µs
Wall time: 153 µs
In [6]: %time import numpy
CPU times: user 173 ms, sys: 566 ms, total: 739 ms
Wall time: 91 ms
In [7]: %time import pandas
CPU times: user 134 ms, sys: 5.35 ms, total: 140 ms
Wall time: 157 ms
hi. I just want to remark that pruning these imports would make polars significantly more useful for building cli tools. in the context of cli, startup times + import times matter a lot
on my somewhat fast machine polars 0.14.21 takes >900ms to import. most of these imports seem to be related to either polars.testing or pandas. if these imports could be eliminated or made lazy, this would lead to a significantly better cli ux
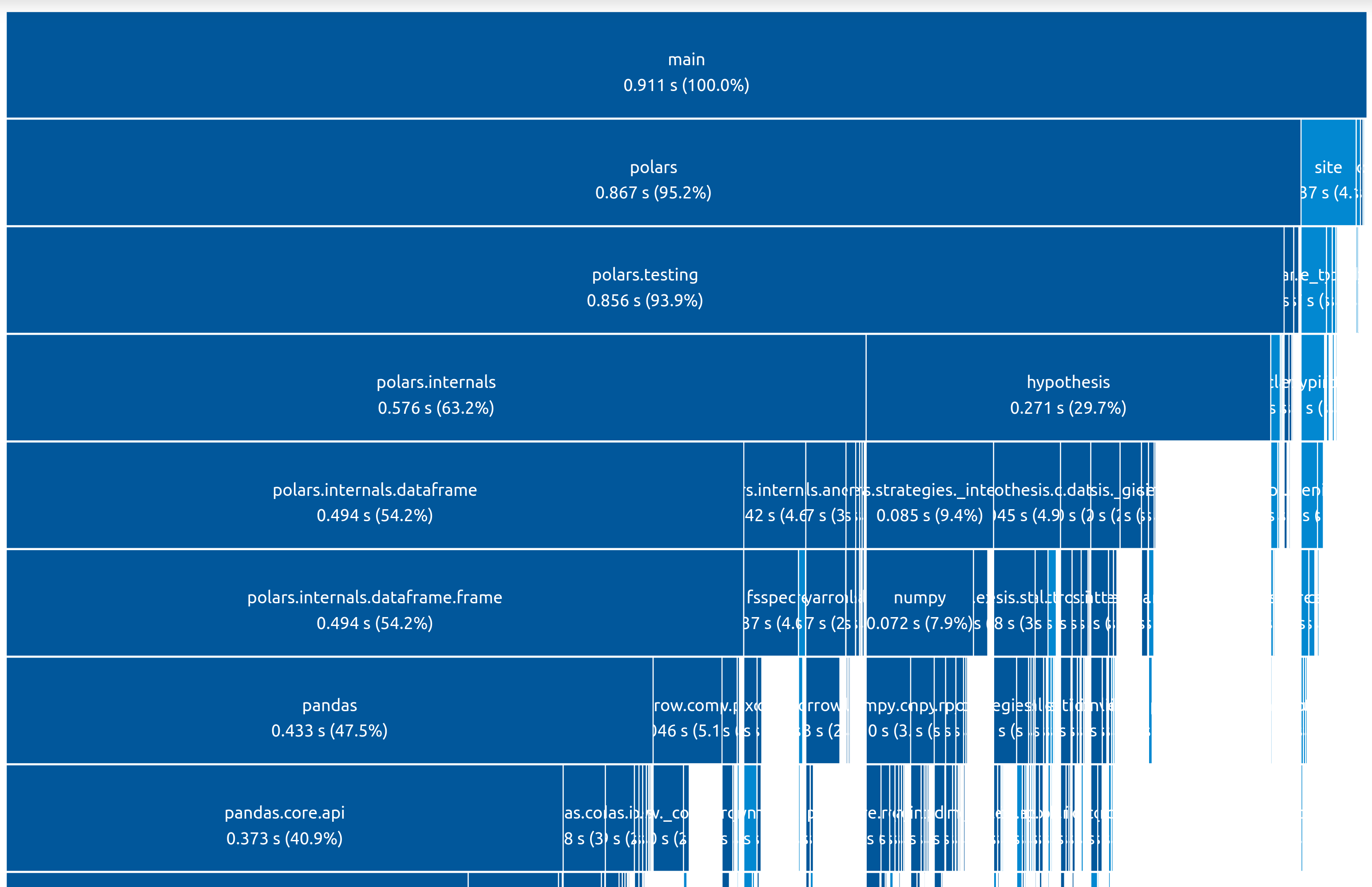
I maintain a few different cli tools that require dataframe operations. I would prefer to switch them over from pandas to polars, but pandas is currently net faster for many small operations because of polars' longer import times
I don't know whether this is a priority right now but just wanted to share this perspective
mes + import times matter a lot
How do you get that visualization? I try with tuna, but I don't get that depth?
hmm I'm just using tuna 0.5.11, nothing special (and I was testing polars 0.14.21). clicking on entries will zoom in on them
btw Ive found it helpful to put:
function importtime() {
python3 -X importtime -c "import $1" 2>/tmp/tuna.log;
tuna /tmp/tuna.log;
}
inside my bash .profile so that I can type importtime <package_name> to quickly test packages. thats the command i used to generate the plot above. happy to run more tests or benchmarks if you think it would be helpful
@ritchie46: FYI - I'm doing a second pass through this; got a nice way to make it more idiomatic/seamless (eg: no need for lazy_isinstance, can just use regular isinstance, etc) without giving up any of the fantastic gains. Will post a PR when I've finished working through it and confirmed the timings with a tuna plot).
@ritchie46: FYI - I'm doing a second pass through this; got a nice way to make it more idiomatic/seamless (eg: no need for
lazy_isinstance, can just use regularisinstance, etc) without giving up any of the fantastic gains. Will post a PR when I've finished working through it and confirmed the timings with a tuna plot).
Ooh.. I am curious what you came up with.
Ooh.. I am curious what you came up with.
Only four unit test failures away from finding out; almost there ;)
Update: almost finished [#5302] one minor sphinx issue to go - everything else now looking good.
@ritchie46 Done! 😅
@ghuls helpfully pointed out that my first pass wasn't properly replicating the lazy_instance behaviour; did another pass and tweaked things so that full laziness of the guard/pattern is still preserved, but using a regular isinstance. Addressed remaining lint/docs/tests and rebased against the latest code...
I've create a package for this purpse, please checkout https://github.com/anhvth/lazy_module