coll: Iallreduce TSP recursive exchange with no dtcopy
Pull Request Description
Two TSP-based Iallreduce high radix recursive exchange algorithms with data copy between phases.
Author Checklist
- [ ] Provide Description Particularly focus on why, not what. Reference background, issues, test failures, xfail entries, etc.
- [ ] Commits Follow Good Practice
Commits are self-contained and do not do two things at once.
Commit message is of the form:
module: short descriptionCommit message explains what's in the commit. - [ ] Passes All Tests Whitespace checker. Warnings test. Additional tests via comments.
- [ ] Contribution Agreement For non-Argonne authors, check contribution agreement. If necessary, request an explicit comment from your companies PR approval manager.
@hzhou My understanding from @zhenggb72 is that this PR has some of the building blocks that will unlock a bunch of our other work. Can you take a look at it please?
@hzhou My understanding from @zhenggb72 is that this PR has some of the building blocks that will unlock a bunch of our other work. Can you take a look at it please?
Of course.
The first two commits are independent. If you split, we can merge them right away.
I'll need more time to go over the algorithms to determine the merit and whether it requires some code cleanup. If you have performance analysis already and can share it, that will certainly help.
I don't think that is necessary. That two commits I think are used in the later commits only, so they can wait.
Some document about the algorithms:
-
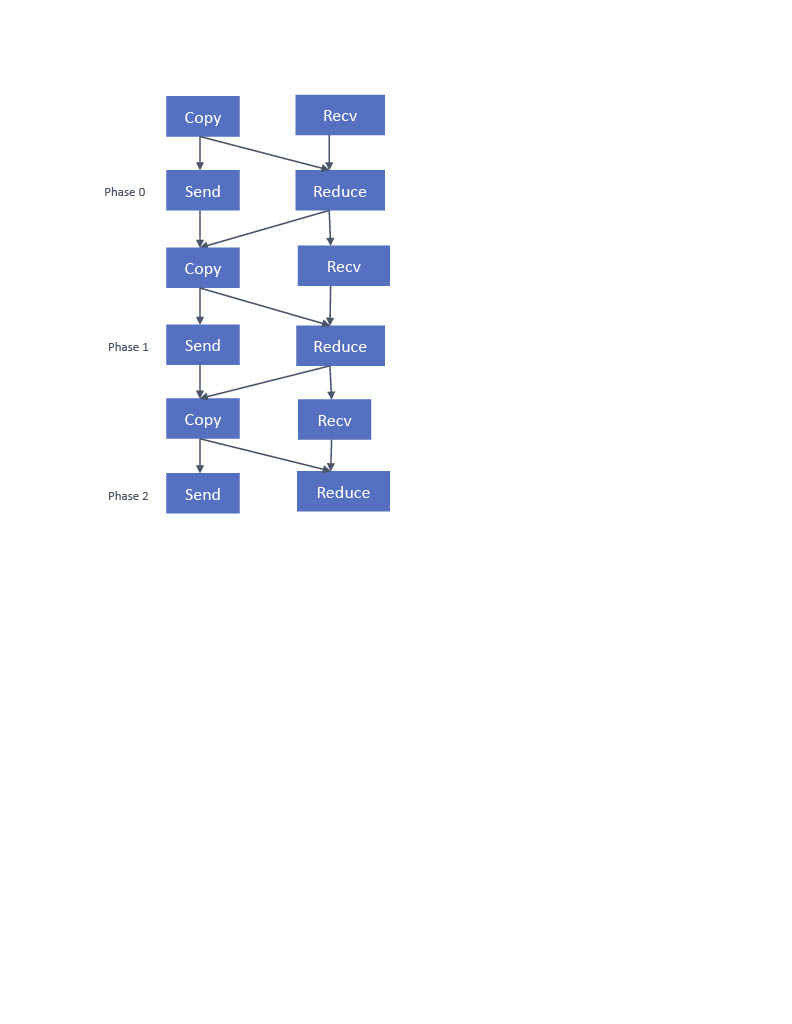
Single receive buffer with data copy: (figure 1) A single receive buffer is used to receive the data from all (k-1) neighbors across all phases. In addition, this approach uses a buffer for reduce and another to send the data. A disadvantage of this algorithm is that at each phase, before the Send, the data in the reduce buffer is copied to the send buffer. However, the advantage of having a different buffer for reduce and send is that the reduce operation can start right after the copy operation. Not having the copy delays the start of the reduce operation until the send buffer can be reused, which requires that the message is sent, received, and the ACK received by the sender.
-
Multiple receive buffer with data copy (figure 2) A separate receive buffer for each (k-1) neighbors across all the phases is used. The total number of receive buffers is (k-1)*(number of phases). In addition, the data are reduced as soon as they arrive. This results in a non-deterministic implementation, but provides maximum concurrency, especially in case of imbalance. With a single receive buffer, in case of imbalance and K>2, the reduce operations execute in the order in which the receive operations are posted. Thus, when the message corresponding to the first receive is received the last, all the reduce operations need to wait until that message is received. However, when multiple buffers are posted, the reduce can execute in the order in which the messages are received, which helps to hide the imbalance
-
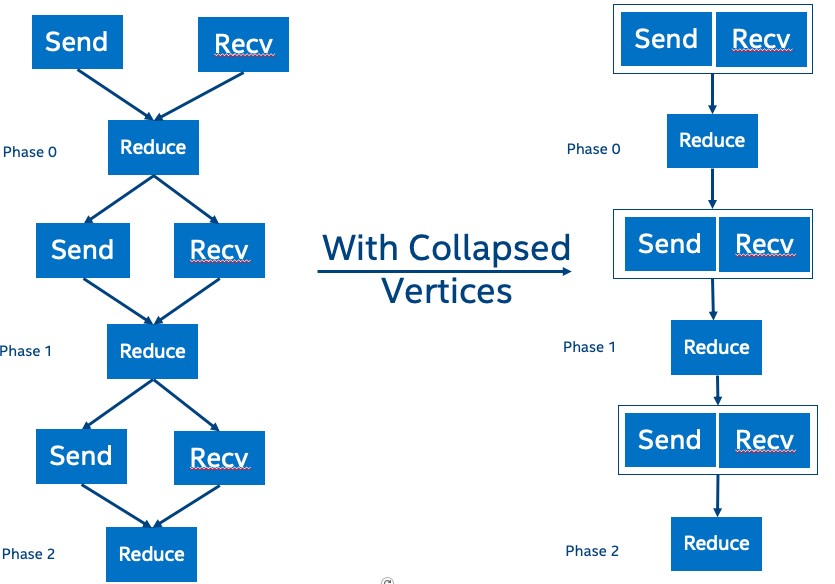
Single buffer without data copy (figure 3) This algorithm eliminates the data copy from the receive buffer. This algorithm eliminates the overhead of data copying, but sacrifices some concurrency. This algorithm is the most restrictive because there are tight dependencies between every call. Because of this, this algorithm will result in a deadlock for K>2, so this is only supported for k=2.
-
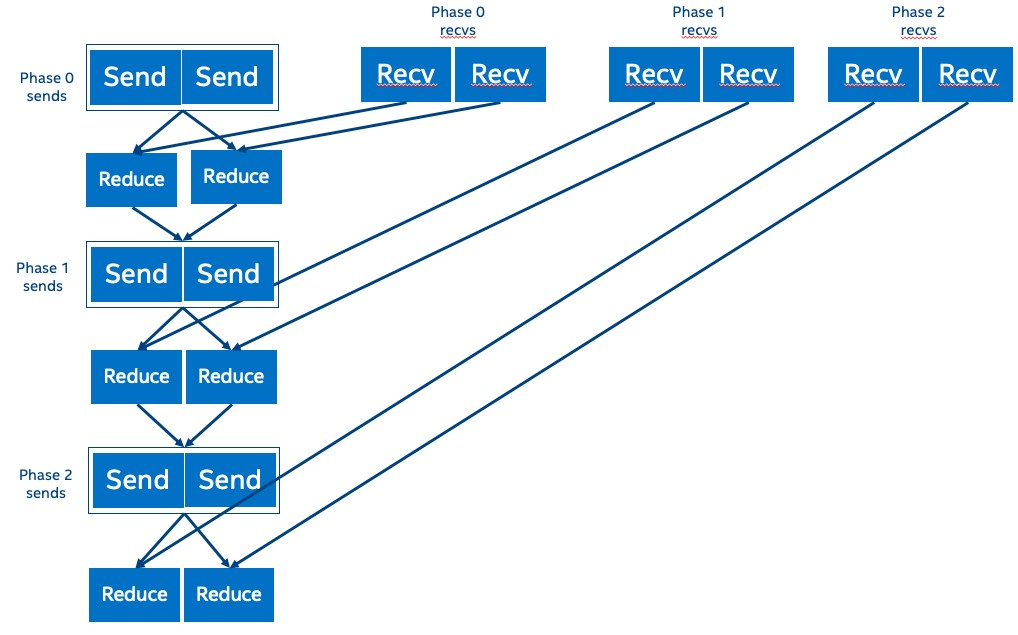
Multiple receive buffer without data copy (figure 4) This algorithm has multiple receive buffers with a separate buffer for each (k-1) neighbors in every phase. Since there is no data copy, the reduce operations have to wait for the data to be sent because that buffer is also going to be used as output of the reduction operations.