:grey_question: API for pantry packages :bar_chart:
Hi guys, sorry for dummy question, but I could not find an API description on how to browse pantry packages.
That would lead to some very cool stuff :nerd_face:
@adriens we publish .txt and .json files, eg.
- https://dist.tea.xyz/zlib.net/versions.txt
- https://dist.tea.xyz/zlib.net/darwin/aarch64/versions.txt
We used to publish this, but it appears to be out of date (/cc @jhheider)
- https://dist.tea.xyz/versions.json
@jhheider I asked ChatGPT for the lambda to make an s3 bucket browsable, can you please set this up? Thank you.
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
exports.handler = async (event, context, callback) => {
const bucketName = 'your-bucket-name';
const bucketObjects = await s3.listObjects({Bucket: bucketName}).promise();
let html = '<html><body>';
bucketObjects.Contents.forEach(obj => {
const url = `https://${bucketName}.s3.amazonaws.com/${obj.Key}`;
html += `<a href="${url}">${obj.Key}</a><br>`;
});
html += '</body></html>';
const response = {
statusCode: 200,
headers: {
'Content-Type': 'text/html',
},
body: html,
};
callback(null, response);
};
As a Viewer Request event on Lambda@Edge (it claims).
I believe we have (had?) logic for this, but my guess is it bitrotted since deployment: https://dist.tea.xyz/
We can get something working again.
That looks perfectly goo. I'll have a lok at tt to perform some intergations. I'll psot you resources here :+1:
@mxcl :
these files are almost empty :
https://dist.tea.xyz/zlib.net/versions.txt
https://dist.tea.xyz/zlib.net/darwin/aarch64/versions.txt
Do you have the resources to browse the pantry ?... or get dumps (csv/jon) ?
Yes, this one :
https://dist.tea.xyz/versions.json
has a lot of interesting data :smile_cat: : wha'ts the refresh policy ?
txt: https://dist.tea.xyz/ (browser) or https://dist.tea.xyz/bottles.txt (any) json: https://dist.tea.xyz/bottles.json (any)
the backend service that's generating those lists uses a 5m cache due to ever-increasing cost of walking the tree. if that's too long for a given application, we can explore.
We could, but there's race condition considerations with CI instances uploading and updating the registry. Possibly a periodic refresh would be smarter, but a cached scan is working (so far).
Just let me know, I can alos benchmark the client (API consumer) side :bulb:
hopefully, CloudFront is compressing on the fly. I didn't bother checking, however.
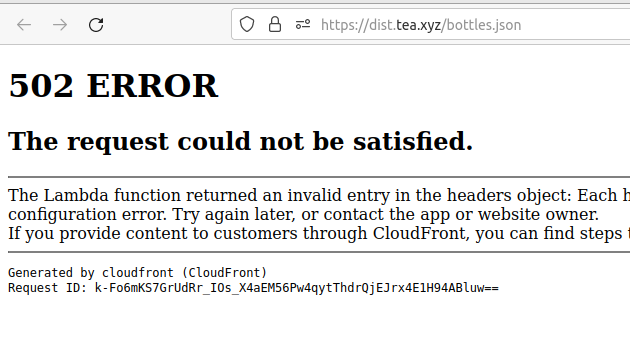
Fixed. I forgot the obnoxious way CloudFront requires header keys from Lambda:
headers: {
"content-type": [
{ key: "content-type", value: "application/json" }
}
}
The dwonload takes qyite a while, would you consider sevring it a gz :
❯ du -sh bottles.json 256K bottles.json ❯ gzip bottles.json ❯ du -sh bottles.json.gz 16K bottles.json.gz ~
I'm actually surprised that CloudFront isn't. Let me look at the distribution.
Ah, for the lambda you have to tell it the content-encoding. Set now. Super fast if the cache is fresh.
Just for fun
D select org, > count(*) as nb_products > from product > group by org > having nb_products > 1 > order by nb_products desc; ┌───────────────────┬─────────────┐ │ org │ nb_products │ │ varchar │ int64 │ ├───────────────────┼─────────────┤ │ │ 143 │ │ github.com │ 42 │ │ gnu.org │ 30 │ │ crates.io │ 16 │ │ x.org │ 10 │ │ gnome.org │ 7 │ │ freedesktop.org │ 6 │ │ gnupg.org │ 5 │ │ google.com │ 5 │ │ charm.sh │ 3 │ │ kubernetes.io │ 3 │ │ code.videolan.org │ 2 │ │ gitlab.com │ 2 │ │ rust-lang.org │ 2 │ │ sourceware.org │ 2 │ │ tea.xyz │ 2 │ │ xiph.org │ 2 │ ├───────────────────┴─────────────┤ │ 17 rows 2 columns │ └─────────────────────────────────┘
D select has_org, count(*) from > (select > case > when (org is null) then false > else true > end has_org > from product) > group by has_org; ┌─────────┬──────────────┐ │ has_org │ count_star() │ │ boolean │ int64 │ ├─────────┼──────────────┤ │ false │ 143 │ │ true │ 181 │ └─────────┴──────────────┘ D
Some times I get the following error message :
IOException: IO Error: Read error for HTTP GET Range to 'https://dist.tea.xyz/bottles.json'
ANy idea what's going wrong :grey_question: :pray:
My guess would be too short a timeout when it requires a cache refresh. Possibly in the lambda, possibly in duckdb. I can extend the lambda's timeout just in case.
What is the refresh schedule ? is it live.daily, weekly ?
The cache is a 5 minute hold.