chainer-gogh
 chainer-gogh copied to clipboard
chainer-gogh copied to clipboard
chainer-gogh
Implementation of "A neural algorithm of Artistic style" (http://arxiv.org/abs/1508.06576) in Chainer. The Japanese readme can be found here.
Accompanying article: https://research.preferred.jp/2015/09/chainer-gogh/









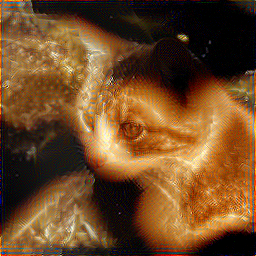






(VGG, lam=0.0075, after 5000 iterations)
Usage:
Install Chainer
pip install chainer
See https://github.com/pfnet/chainer for details.
Download the model(s)
There are multiple models to chose from:
- NIN https://gist.github.com/mavenlin/d802a5849de39225bcc6
Simply specify: (-m nin)
- VGG https://gist.github.com/ksimonyan/211839e770f7b538e2d8#file-readme-md
With VGG, it takes a long time to make good looking images. (-m vgg, -m vgg_chainer)
After downloading and using the vgg_chainer model for the first time, all subsequent uses will load the model very fast.(functionality available in chainer 1.19 and above).
- GoogLeNet https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
About the same as NIN, but there should be potential for good images. The optimum parameters are unknown. (-m googlenet)
- illustration2vec http://illustration2vec.net/ (pre-trained model for tag prediction, version 2.0)
Lightweight compared to VGG, should be good for illustrations/anime drawings. Optimal parameters are unknown. (-m i2v)
Run on CPU
python chainer-gogh.py -m nin -i input.png -s style.png -o output_dir -g -1
Run on GPU
python chainer-gogh.py -m nin -i input.png -s style.png -o output_dir -g <GPU number>
Stylize an image with VGG
python chainer-gogh.py -m vgg_chainer -i input.png -s style.png -o output_dir -g 0 --width 256
How to specify the model
-m nin
It is possible to change from nin to vgg, vgg_chainer, googlenet or i2v. To do this, put the model file in the working directory, keeping the default file name.
Generate multiple images simultaneously
- First, create a file called input.txt and list the input and output file names:
input0.png style0.png
input1.png style1.png
...
then, run chainer-gogh-multi.py:
python chainer-gogh-multi.py -i input.txt
The VGG model uses a lot of GPU memory, be careful!
About the parameters
-
--lr: learning rate. Increase this when the generation progress is slow. -
--lam: increase to make the output image similar to the input, decrease to add more style. - alpha, beta: coefficients relating to the error propagated from each layer. They are hard coded for each model.
Advice
- At the moment, using square images (e.g. 256x256) is best.