percona-server-mongodb-operator
 percona-server-mongodb-operator copied to clipboard
percona-server-mongodb-operator copied to clipboard
K8SPSMDB-758: Prioritize ServiceMesh FQDN for config servers if DNSMode is set to ServiceMesh
![]()
Hi
This is in relation to this https://github.com/percona/percona-server-mongodb-operator/pull/920
We've noticed some traffic leaving the ServiceMesh. After some debugging I found what I think is the reason. Looking at the arguments for the mongos, I noticed that some of them don't resolve using the mesh address.
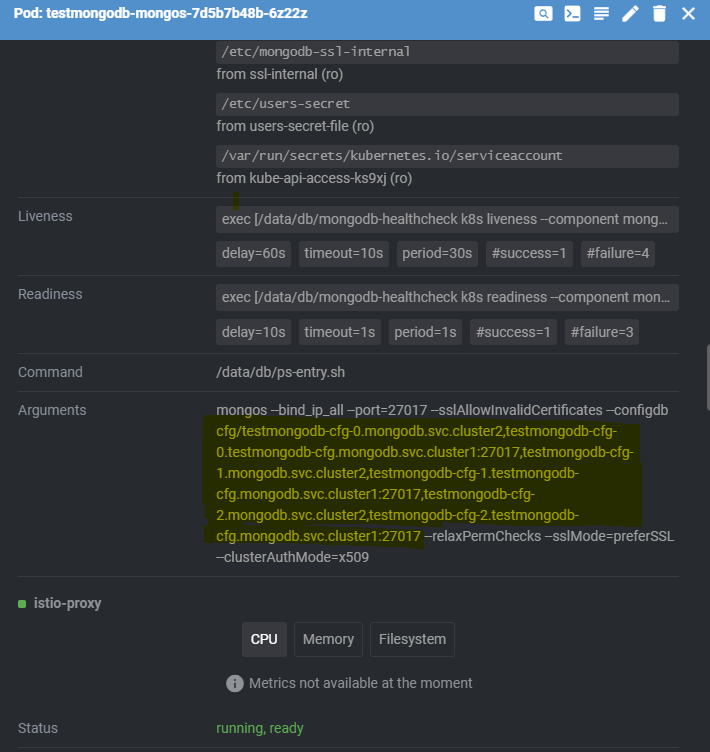
The relevant config section:
testmongodb-cfg-0.mongodb.svc.cluster2
testmongodb-cfg-0.testmongodb-cfg.mongodb.svc.cluster1:27017
testmongodb-cfg-1.mongodb.svc.cluster2
testmongodb-cfg-1.testmongodb-cfg.mongodb.svc.cluster1:27017
testmongodb-cfg-2.mongodb.svc.cluster2
testmongodb-cfg-2.testmongodb-cfg.mongodb.svc.cluster1:27017
Addresses from cluster2 (the remote cluster) resolves correctly, through exposed services and routed through the mesh. However, the local services seems to not be using the exposed service.
Looking at this block, I think I found the reason.
https://github.com/percona/percona-server-mongodb-operator/blob/98637ec48ea6644f8e320ffd97de19f3fcecbc46/pkg/controller/perconaservermongodb/psmdb_controller.go#L1113-L1126
The "false" parameter on line 1115 seems to be an override / hard coded value intended to be "don't use public IP for internal communication" even if config pods are exposed publicly. When building cfgInstances the internal cfg endpoints will be resolved using the MongoHost, with rsExposed=false while the external nodes use the service mesh address (external address)
I was first wondering why the hard coded false, rather than use the exposed variable from the configuration. I do get the point of having traffic, by default, not route using external addresses, however for a service mesh we would like to have the decision made by the mesh.
The remote nodes are more or less just read straight from the config. It doesn't seem to respect the port number for remote nodes set in the config, but since we're using default ports that isn't really a problem nor something I've looked into. A simple workaround is to just add the port number directly in the host parameter in the config, but then I'm not sure why "Port" is necessary (i.e. host=remotemongo.example.com:27018, port=27018)
replsets:
- name: rs0
size: 3
externalNodes:
- host: remotemongo.example.com:27018
port: 27018
Looking at the initial implementation I think I made a bit of an oversight there, as the mesh dns mode is only applied for exposed nodes. This leaves the internal config nodes on the main deployment site outside, as they resolve with the default GetAddr function.
https://github.com/percona/percona-server-mongodb-operator/blob/98637ec48ea6644f8e320ffd97de19f3fcecbc46/pkg/psmdb/service.go#L255-L278
I see a few different possible solutions:
-
Let the service mesh dns mode ignore the rsExposed when resolving node addresses, and have it outside the if rsExposed. This is the solution proposed in the PR, as I think it has the least impact on the existing installs.
-
Change cfg nodes to respect the exposed settings only then dns mode is service mesh mode.
-
Change how the cfg nodes address is resolved, and respect the rsExposed setting. I.e. change line 1115 to something like
host, err := psmdb.MongoHost(ctx, r.client, cr, api.ConfigReplSetName, cr.Spec.Sharding.ConfigsvrReplSet.Expose.Enabled , pod)
Any insights to share? Something I'm missing?
@spron-in @hors should we include this in v1.13?
@egegunes v1.13 under testing right now and we have a lot of changes. I do not want to add more and more.
| Test name | Status |
|---|---|
| init-deploy | passed |
| cross-site-sharded | passed |
| one-pod | passed |
| storage | passed |
| upgrade-consistency | passed |
| demand-backup | passed |
| self-healing | passed |
| self-healing-chaos | passed |
| limits | passed |
| monitoring-2-0 | passed |
| scaling | passed |
| scheduled-backup | passed |
| arbiter | passed |
| operator-self-healing | passed |
| operator-self-healing-chaos | passed |
| security-context | passed |
| service-per-pod | passed |
| rs-shard-migration | passed |
| demand-backup-sharded | passed |
| liveness | passed |
| smart-update | passed |
| upgrade | failed |
| version-service | passed |
| upgrade-sharded | failed |
| users | passed |
| data-sharded | passed |
| non-voting | passed |
| demand-backup-eks-credentials | passed |
| data-at-rest-encryption | passed |
| pitr | failed |
| pitr-sharded | failed |
| We run 31 out of 30 |
commit: https://github.com/percona/percona-server-mongodb-operator/pull/1014/commits/7f6312114ac0c5b24f698814a33e3c186c784db9
image: perconalab/percona-server-mongodb-operator:PR-1014-7f631211
Just my 2 cents on the related topic.
I believe using the clusterServiceDNSMode to drive the way services are advertized and consumed by replsets and sharding.configsvrReplSet creates a bit of ambiguity.
It looks like this parameter only plays a role when the replica sets and cfg replica set are exposed (expose.enabled: true).
I believe it would make sense to describe the way services are advertized inside of the expose component in replsets and sharding.configsvrReplSet respectively.
multiCluster probably also falls into this category.
The other thing (and it is probably because I do not properly understand how mongo host advertizing is working in case of multi cluster deployments (not MCS)), is the fact that we can only consume esxternal replica set end-points when expose.enabled: true.
For instance, I am perfectly happy to address mongo replica set pods by <pod>.<headlessservice>.<namespace>.<cluster-domain-suffix> without having to create a NodePort, ClusterIP or LoadBalancer services in case when:
- there is a flat network with pod IPs accessible across multiple clusters (bad idea)
- there is a cluster mesh, like cilium is in place, which creates a secure policy-driven pod-to-pod mesh across k8s clusters
I would need to configure a federated DNS across k8s clusters, etc, but that is rather a problem to solve with a flavor of a ServiceMesh, than the psmdb operator.
Hi @jlyshoel, thank you for the contribution. We'll include this in v1.14.
| Test name | Status |
|---|---|
| init-deploy | passed |
| one-pod | passed |
| upgrade-consistency | passed |
| storage | passed |
| cross-site-sharded | passed |
| demand-backup | passed |
| self-healing-chaos | passed |
| limits | passed |
| ignore-labels-annotations | passed |
| scaling | passed |
| monitoring-2-0 | passed |
| scheduled-backup | passed |
| security-context | passed |
| operator-self-healing-chaos | passed |
| arbiter | passed |
| rs-shard-migration | passed |
| demand-backup-sharded | passed |
| service-per-pod | passed |
| upgrade | passed |
| liveness | passed |
| smart-update | passed |
| upgrade-sharded | passed |
| version-service | passed |
| pitr | passed |
| users | passed |
| pitr-sharded | passed |
| data-sharded | passed |
| non-voting | passed |
| demand-backup-eks-credentials | passed |
| data-at-rest-encryption | passed |
| We run 30 out of 30 |
commit: https://github.com/percona/percona-server-mongodb-operator/pull/1014/commits/9a2c1e0a1e2d84cd3181adc95155307a5aea6bf8
image: perconalab/percona-server-mongodb-operator:PR-1014-9a2c1e0a
Hello, @jlyshoel! Thank you for your contributions! We would like to send you a gift from Percona. Please, contact us at [email protected].