Peter M. Stahl
Peter M. Stahl
Hi Tom, I'm a graduate in computational linguistics and would like to contribute to Pattern. Can you be more explicit about how Pattern should support Python 3? That is, do...
Hi Tom, as I wrote at the beginning of this year, I'm still interested in contributing to pattern. However, I have not started yet because I didn't really know where...
@hayd OK, I get your point. I'm okay with that. It just reminds me again of how unhappy I am about the Python 3.\* transition in general across the Python...
Hello, I'm the author of [Lingua](https://github.com/pemistahl/lingua-py). I've managed to reduce the memory consumption of the library. All language models together now just take around 800 MB in memory. Perhaps you...
@osma I have just released [Lingua 1.1.0](https://github.com/pemistahl/lingua-py/releases/tag/v1.1.0). In high accuracy mode, memory consumption is now at 800 MB. In low accuracy mode, it's even just 60 MB. 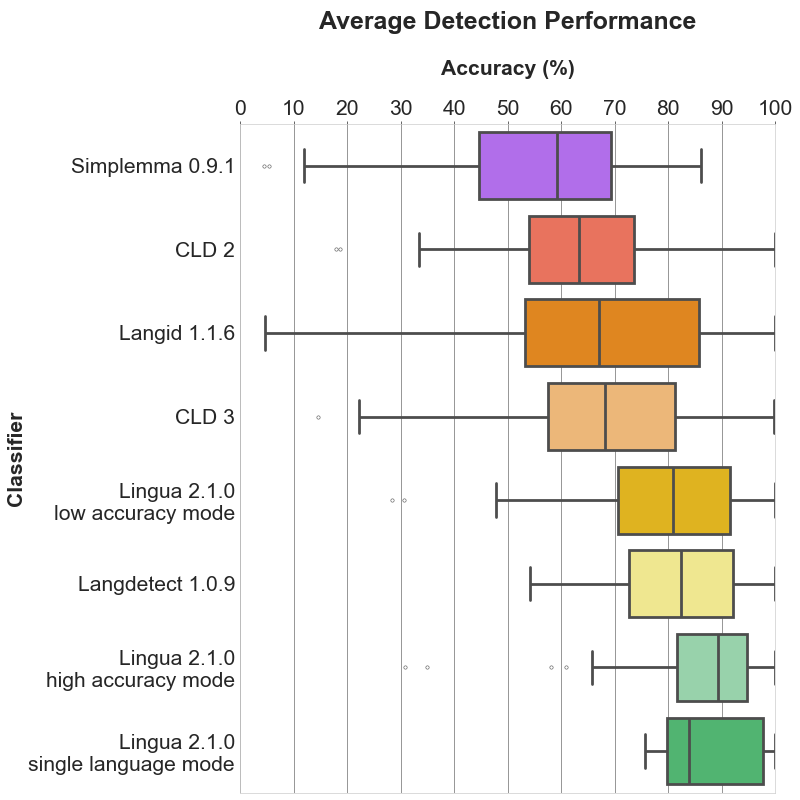
Yes, that's because the models are now stored in NumPy arrays instead of dictionaries. Querying the arrays is slower than querying dictionaries, that's the downside. But I still use a...
FYI: There was a little bug in version 1.1.0 that caused wrong probabilities to be returned for certain ngrams. I've just fixed that. So please use version 1.1.1 now for...
@osma My library is slower because it is written in pure Python. pycld3 is written in C++ and simplemma uses [`mypyc`](https://github.com/mypyc/mypyc) to compile the Python modules to C extensions. I've...
> I apologize for the harsh wording. No worries, @osma. I'm not resentful. :) > I understand that Lingua's strong point is the high accuracy it achieves. But for an...
Hi @BLKSerene, thank you for your request. The library already distinguishes between Bokmal and Nynorsk. As for Simplified and Traditional Chinese, I could not find suitable training corpora yet which...