[WIP] nine
Pxer 9 2nd demo
Main project structure
src/
resolvers/
base.ts // a single object containing all base resolvers
sugar.ts // a single object containing all sugar resolvers
common/
error.ts // error type definition
illusttype.ts // code for illust type detection
network.ts // network request encapsulated
threadmamager.ts // thread manager
types.d.ts // type definitions
router.ts // resovler router
engine.ts // PxerEngine (main class)
index.ts // index file
test/
[ClassName]/
[TestName].ts // Test with mocha+chai
Diff from your demo
This demo is generally based on the structure of pea3nut/pxer-engine-demo with a few modifications.
- Mixin structure is removed. I think this adds excessive complicity to the project and encourages unnecessary coupplings in future development.
- Main Class(
PxerEngine) reports results and errors to the front end using an event-based system. - Instead of providing only a
callbackcallback to resolvers with a lot of overrides. I provided three callbacks(gotWorkreportErraddTask). This greatly reduced the difficulty in writing resolvers and resolver workflows would be more self-explanatory as callback function names are just what they are intended to do.
Testing
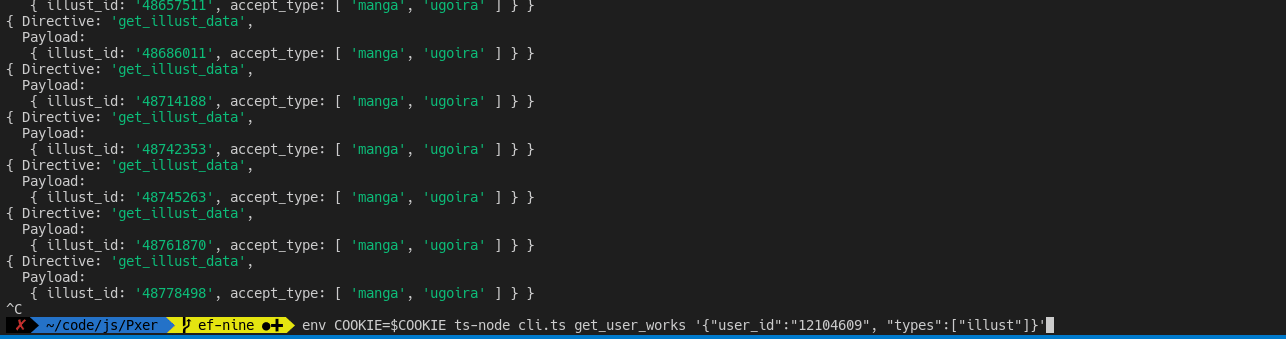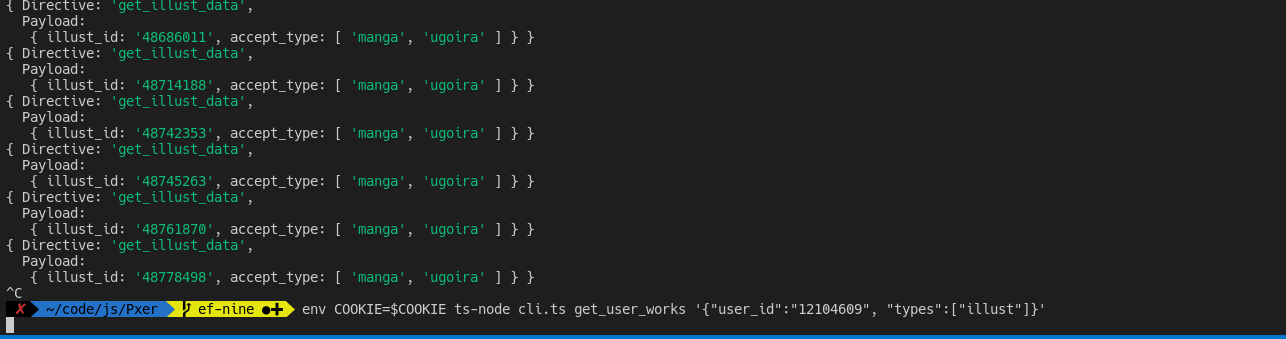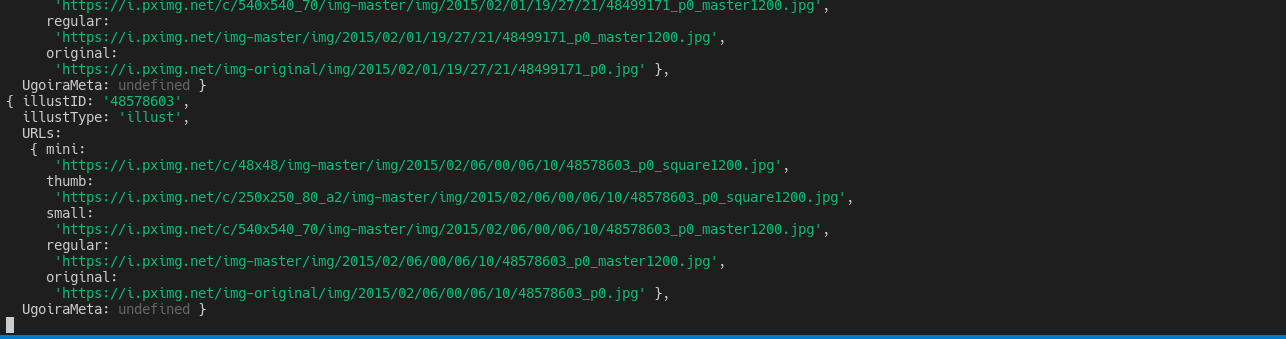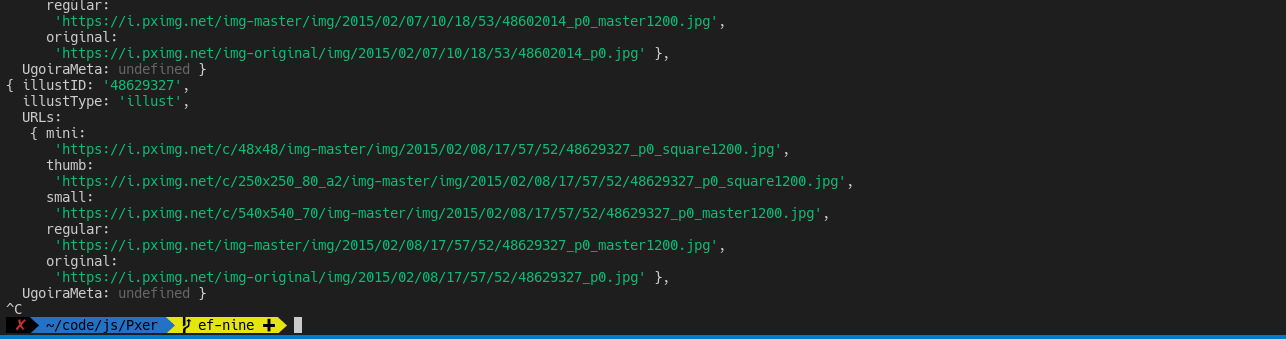
I included a cli.ts in the demo so that we could test the package easily. To use cli.ts, use the following command:
env COOKIE="PHPSESSID=xxx;" ts-node cli.ts (directive) [optional JSON-encoded payload]
TODO
- [ ] Improve error definitions and handling
- [ ] Implement more resolvers
- [ ] Unit tests
@pea3nut 我认为你提到的这些功能已经实现或不是引擎需要的功能:
- 程序已经能够输出图片的地址,至于选择分辨率个人觉得那是前端应用程序做的事情,在引擎里实现不太妥当?
- 简单的过滤指什么?按类型过滤?现在的版本已经实现了,通过payload传一个type,参见PR description里的demo
已经加上了保存和恢复的方法,测试流程:
- 运行cli.ts时Ctrl-C终止,等待Engine graceful shutdown并将结果保存在
./progress.json - 使用
ts-node cli.ts resume恢复(COOKIE环境变量没有保存,所以resume的时候这个环境变量也要存在)
另外抽出了很多可重用的逻辑,很大程度上提升了resolver的可读性
关于Engine和WorkResult解偶我仔细想了一下觉得还是不太需要。主要的原因还是这个engine的主要目的就是“获取各种方式整合(用户作品,排行榜,……)的作品列表的作品信息(URL等)”,一些边际需求(只要数量不要抓取)完全可以通过其他workaround解决,例如payload加一个count_only然后用engine.on("count", console.log)。我认为我们之所以一开始要选择resolver这样的模式,就是因为resolver有着及其类似的IO模式(输入一些参数,例如userID,输出子任务或作品信息)。如果要把获取数量等等都做成resolver,那么resolver之间的共同点在哪里?我可以想象到我们会有get_user_works get_user_works_count get_rank_works get_rank_list get_rank_count get_bookmark get_bookmark_count,内部逻辑几乎完全重合而输出type完全不同的resolver。目前我push的版本是通过on("count",cb)来实现的