nbabel
 nbabel copied to clipboard
nbabel copied to clipboard
Benchmark N-Body system
Here are some elapsed times (in s) for 5 implementations (of course, these numbers do not characterized the languages but only particular implementations in some languages).
| # particles | Py | C++ nbabel.org | Fortran nbabel.org | Julia nbabel.org | Rust |
|---|---|---|---|---|---|
| 1024 | 30 | 55 | 41 | 45 | 34 |
| 2048 | 124 | 231 | 166 | 173 | 137 |
| 16384 | 7220 | 14640 | 10914 | 11100 | ? |
The implementations in C++, Fortran and Julia come from https://www.nbabel.org/ and have been used in an article published in Nature Astronomy (Zwart, 2020). The results of this updated benchmark was summarized in Augier et al., 2021 (see how to cite the article).
The implementation in Python-Numpy is very simple, but uses Transonic and Pythran (>=0.9.8).
To run these benchmarks, go into the different directories and run make bench1k or make bench2k.
To give an idea of what it gives compared to the figure published in Nature Astronomy:
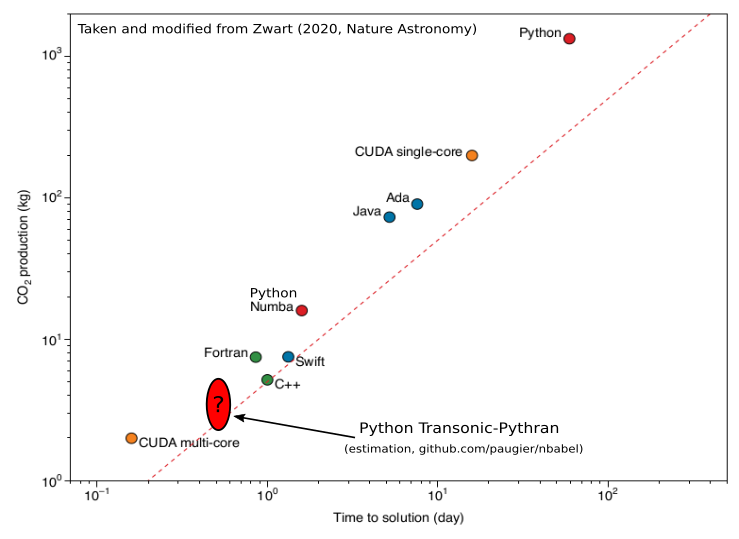
Note: these benchmarks are run sequentially with a Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz.
Note 2: With Numba, the elapsed times are 44 s, 153 s and 11490 s, respectively. This is approximately 20% faster than the C++ implementation.
Note 3: With PyPy, a pure Python implementation (bench_pypy_Point.py) runs for 1024 particles in 133 s, i.e. only 2.4 times slower than the C++ implementation (compared to ~50 times slower as shown in the figure taken from Zwart, 2020). Moreover, with a new version of PyPy (branch map-improvements, merged in default on Feb 02 2021, so one can use a nightly build), another implementation (bench_purepy_Particle.py) runs in 55 s, i.e. same speed than the C++ implementation!
Note 4: The directory "julia" contains some more advanced and faster implementations. The sequential optimized Julia implementation runs on my PC in 22 s, 82 s and 5340 s, respectively (i.e. 25-30% faster than our fast and simple Python implementation).
Note 5: From the high level Numpy implementation
(bench_numpy_highlevel.py), if one (i) adds an import from transonic import jit and (ii) decorates the function loop with @jit, the case for 1024
particles runs in 136 s (2.5 times slower than the C++ implementation).
Note 6: The directory "cpp" also contains 2 faster C++ implementations (proposed by @bolverk and @isuruf) which run on my PC in 25 s, 104 s and 7080 s for the AoS implementation by @bolverk and 26s, 104 s and 7330 s for the SoA implementation by @isuruf. Note that there is a problem with the conservation of energy.
Table of codes
See run_benchmarks.py.
| Legend figure | Source code |
|---|---|
| C++ nbabel.org | main.cpp |
| Fortran nbabel.org | nbabel.f03 |
| Pythran naive | bench_numpy_highlevel_jit.py |
| PyPy | bench_purepy_Particle.py |
| Numba | bench_numba.py |
| Pythran | bench.py |
| Julia | naive_lowlevel.jl |
| Julia optimized | nbabel5_serial.jl |
| Pythran paralllel | bench_omp.py |
| Julia parallel | nbabel5_threads.jl |
Citation
@article{nbabel2021,
title = {Reducing the Ecological Impact of Computing through Education and {{Python}} Compilers},
author = {Augier, Pierre and {Bolz-Tereick}, Carl Friedrich and Guelton, Serge and Mohanan, Ashwin Vishnu},
year = {2021},
month = apr,
volume = {5},
pages = {334--335},
publisher = {{Nature Publishing Group}},
issn = {2397-3366},
doi = {10.1038/s41550-021-01342-y},
journal = {Nature Astronomy},
language = {en},
number = {4}
}