Improve global merge performance
Global merges are already quite a bit better than they used to be, but they can still take quite a bit of time, and I feel like there is still a lot of room for improvement. I did some testing, and it is apparent that there are really two main things that are causing a lot of CPU cycles during merging:
- Actual merging of instant profiles ~34%
- Retrieving metadata from the metastore ~56%
- Marshaling proto ~9%
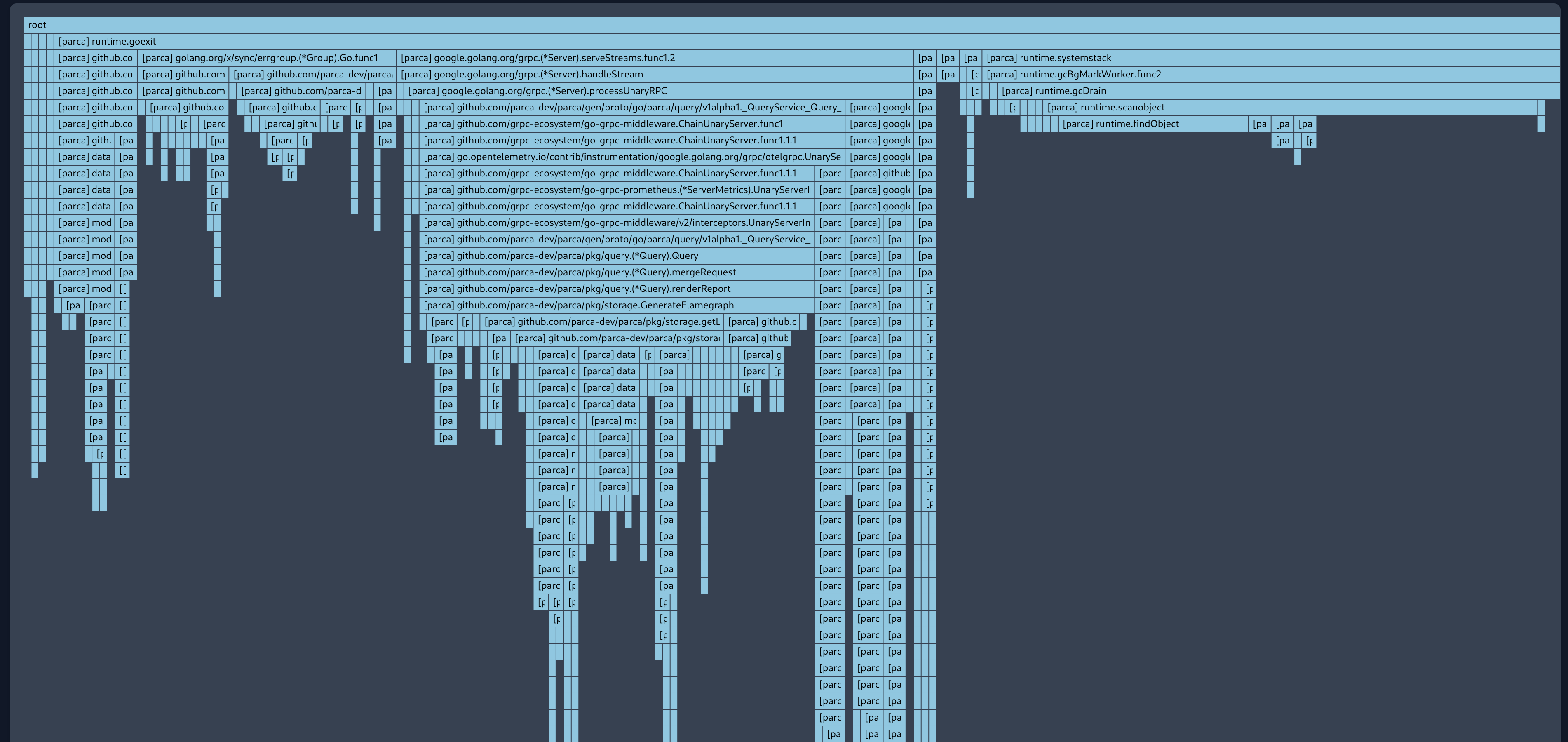
Based on the distribution above, I'm going to have a look at what we can do about retrieving metadata from storage faster. In particular, it appears that most of the time is spent in cache misses, meaning when a location has never been loaded from storage.
More perf work for metastore: #462
More profiling needs to be done now, but my expectation is that allocations will still dominate the metadata stacks in terms of CPU. This could be improved with memory pooling but would need some restructuring of the flamegraph messages to separate out metadata from the flamegraph tree, I'm going to look into this restructuring next.
Large merges now look like this: https://share.polarsignals.com/1c4fb39/
Looks like in terms of metastore interactions, getting locations and location-lines are the biggest offenders.