feat: implement RFC 8628
Implements the Device Authorization Grant to enable authentication for headless machines (see https://datatracker.ietf.org/doc/html/rfc8628)
Related issue(s)
Implements RFC 8628.
This PR is based on the work done on https://github.com/ory/hydra/pull/3252, by @supercairos and @BuzzBumbleBee. That PR was based on an older version of Hydra and was missing some features/tests.
We have prepared a spec, that describes our design and implementation. We have tried to mimic the existing logic in Hydra and not make changes that would disrupt the existing workflows
Checklist
- [x] I have read the contributing guidelines.
- [x] I have referenced an issue containing the design document if my change introduces a new feature.
- [x] I am following the contributing code guidelines.
- [x] I have read the security policy.
- [x] I confirm that this pull request does not address a security vulnerability. If this pull request addresses a security vulnerability, I confirm that I got the approval (please contact [email protected]) from the maintainers to push the changes.
- [x] I have added tests that prove my fix is effective or that my feature works.
- [x] I have added or changed the documentation.
Further Comments
Notes:
- The current implementation has been manually tested only for
memoryandpostgresdatabases. The tests pass all of them. - Fosite is installed from our fork to ease testing. Once the relevant PR in fosite is merged, we will update
go.mod.
Testing
To test this you need to built the hydra image:
make docker
This will create an image with the name: oryd/hydra:latest-sqlite
To run the flow you can use our UI, from https://github.com/canonical/identity-platform-login-ui/tree/hydra-device-test:
git clone [email protected]:canonical/identity-platform-login-ui.git -b hydra-device-test
cd identity-platform-login-ui/
# The image name is hard-coded in the docker-compose file
docker compose up --remove-orphans --force-recreate -d
Create a client for Hydra:
docker exec -it identity-platform-login-ui-hydra-1 hydra create client --endpoint http://localhost:4445 --grant-type authorization_code,refresh_token,urn:ietf:params:oauth:grant-type:device_code --scope openid,offline_access,email,profile --token-endpoint-auth-method client_secret_post
Use that client to perform the device flow:
docker exec -it identity-platform-login-ui-hydra-1 hydra perform device-code --client-id <client-id> --client-secret <client-secret> -e http://localhost:4444 --scope openid,offline_access,email,profile
The user for logging in is:
- username:
[email protected] - password:
test
You kept the user_code & device_code in separate tables ?
I thought It could be merge with the flow table but might be tricky to do (lots of SQL constrains to manage)
Otherwise, it's great work! Would love to see this land into Hydra as IMO it's a much needed feature :)
~One thing I am struggling to understand is the device_challenge parameter. On one side, I cannot find any mention of that in the RFC, on the other side I don't see how it would be available in all variants of the device flow. Sure, when using the verification_uri_complete from the device authorization response, it is easy to set additional query parameters. However, the device auth flow also has to work when only the user code is entered into a generic website, like on https://youtube.com/tv/activate~
I just noticed the design doc you linked, should have taken a look there first.
OK, I think I now cleared up the confusion I had about the device_challenge.
IMO it is not really necessary because it would also work to send the user straight to the UI implementation, and let the /admin/oauth2/auth/requests/device/accept create the flow. The relevant information at this point is always in the user-code, and only the UI provides that. However, I see how it fits better into the existing code and architecture, so I do like the proposal 👍
Apparently the tests are broken because of https://github.com/ory/fosite/pull/827/files#diff-b92270a81f4021a9cdf52dfcfaeac9b66254471b85fd5ef4101acdbad02e4296R161, not sure if it's a bug or if the hydra tests need to be updated. @zepatrik any tip on how to fix this?
@nsklikas I have fixed the upstream fosite issue.
I also thought about the overall flow a bit more, and I think this flow is a bit better wrt database strain (writes and storage). Also it is less complex from the bigger picture, but I agree that it might be more complex to implement. Did you consider something similar, and what are your thoughts? I would especially prefer the user and device codes to be in one table, so we can rely on the database to ensure the link between the two. The big difference is that we would create the flow already when the device initializes everything, and then reuse it for the user as soon as we have the user code.
Also happy to discus synchronously.
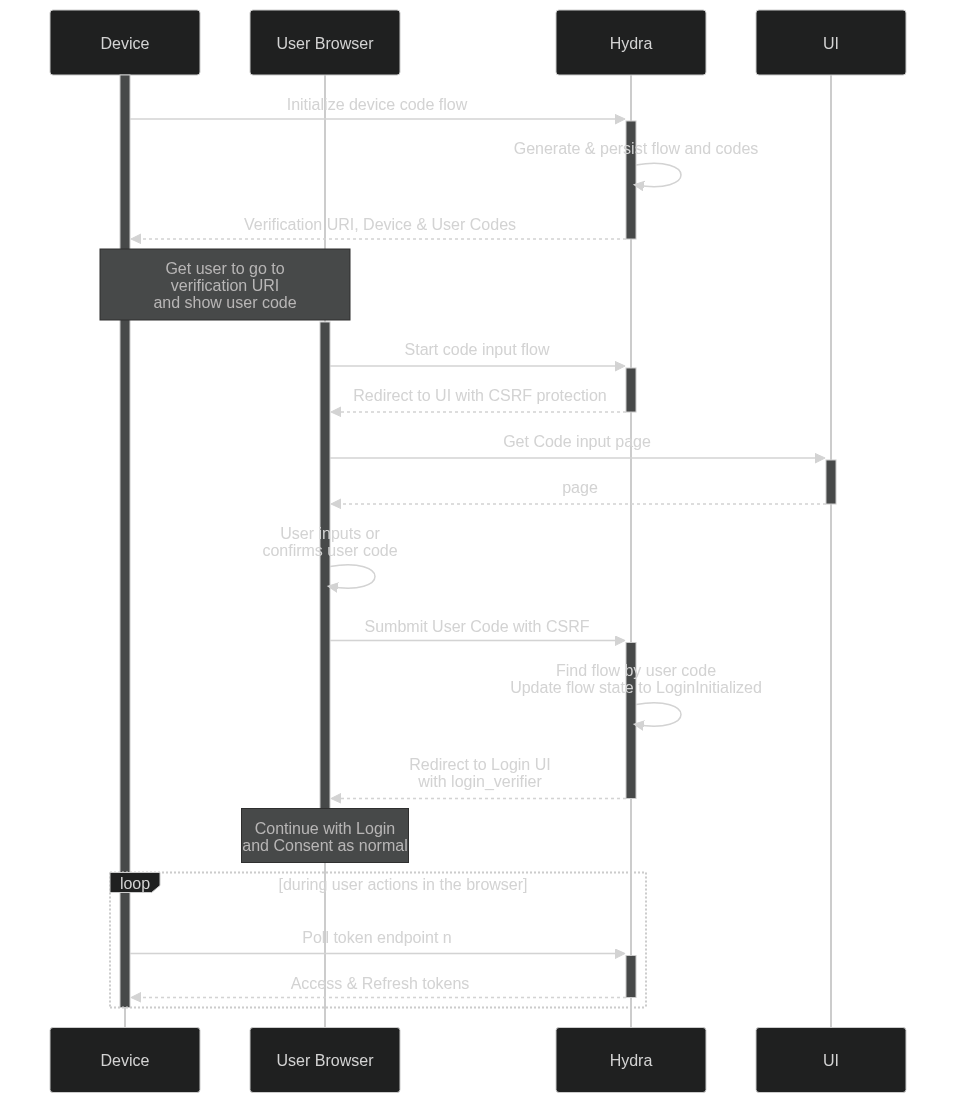
We considered merging the 2 tables (I think it was also discussed in the older PR). Merging the 2 tables would complicate the schema (you would need to have 2 expiration periods, 2 active fields, more indexes, etc) and we would have to create new logic to handle calls to this table (now we re-use the logic that is used for all the other tokens), of course that is not a blocker but would require a decently sized refactor of this PR. We would also have to merge the 2 fosite APIs (DeviceCodeStorage and UserCodeStorage), again not a big blocker. AFAICT by merging the 2 tables we would be making 1 less read to the database (we wouldn't need to fetch the device_code in performOAuth2DeviceVerificationFlow) and one less write (we could invalidate the user_code and mark the device_code as ready to be used in a single query). The main drawback with the current approach is that the 2 tables (user_code and device_code) are not directly merged, instead we use the requestID to connect them. The reason we decided not to go that route is that we thought that the performance benefit does not out-weight having a uniform experience with the existing fosite APIs and hydra database, but I can see the value of changing this.
About persisting the flow table to the database at the beginning of the flow, we would be doing one less redirect (we could send the user directly to the login UI, they wouldn't need to go through Hydra). But we would have to:
- persist the flow to the database every time a device starts a flow (1 write)
- fetch the flow every time a user_code is accepted (we wouldn't update it on the db, because we want to allow the user to to restart the flow)
- update the database constraints to handle the device flow status This was something we considered, but decided that we wouldn't be gaining much for these extra call/changes. What is the reason you think we should change this?
I would rather we keep the design as it is, because we think that these changes wouldn't improve the current flow much (I understand that, depending on the load, merging the 2 tables can offer considerable improved performance) and it would complicate the implementation. Ideally I would rather we do not change the design of the current PR (unless you think that there is something wrong with it), to get something going and to avoid getting lost on the many changes that it introduces. We can always iterate on it on subsequent PRs, BUT I understand that if we want to change the database schema (by merging the tables), it would be best to do it as early as possible to avoid having to create a migration plan.
About persisting the flow table to the database at the beginning of the flow, we would be doing one less redirect (we could send the user directly to the login UI, they wouldn't need to go through Hydra). But we would have to:
1. persist the flow to the database every time a device starts a flow (1 write) 2. fetch the flow every time a user_code is accepted (we wouldn't update it on the db, because we want to allow the user to to restart the flow) 3. update the database constraints to handle the device flow status This was something we considered, but decided that we wouldn't be gaining much for these extra call/changes. What is the reason you think we should change this?
I now realize that we wouldn't be avoiding the first redirect, as we want to setup csrf protection. I don't think I see the value of making this change (referring only to writing the flow in the database when creating the user code).
Thanks for revisiting, I was just adding some follow-up clarifications.
TL;DR we would like to do the refactor to have one-table for the codes, everything else looks good.
We had even more discussions also with @alnr and basically came to these conclusions:
- We need to write the device & user codes into a table when creating them, mainly to avoid collisions. Ideally this would be one table (further
device_auth_codes) that is only used for this purpose. The table should have the PK(nid, device_code_sig)and a secondary unique index(nid, user_code_sig). This table will be polled by the device using the device code. - The flow should not be persisted in the beginning by the device, but used only by the user browser and persisted after successful completion.
- Once the user code is used, we should mark it as such and release it by setting
user_code_sig=null. We can then include the device code signature in the flow. The main reason here is that we can make sure the code is only used once. However, this is not a strong opinion and just what we thought would be the better option. Making the code reusable for error cases would probably reduce some friction in the UX. Open to discuss. - ~There seems to be no value in adding the
device_verifier. We propose to remove that. The existing CSRF token should be sufficient to ensure that a flow was completed in the same browser it was started.~ The reason here is so that we can persist the flow state. Makes sense now. - The "accept user code API" should be an admin API (as it is now), for flexibility and consistency reasons.
Overall, the refactor to use only one table should be worth it right away. We can also help out with the refactor if necessary.
Thanks for the quick reply.
Just to be clear, afaict refactoring the database affects both fosite and hydra. In fosite we should merge the DeviceCodeStorage and UserCodeStorage APIs into one. In hydra we should first agree on a table schema and then do the changes needed.
Regarding the unique index, I am not sure if this is the right approach. We can have a PK with (nid, device_code_sig). But on the user_code index we can't have an index that involves the nid. The reason for this is that when the user accepts the user_code we have no other information about the flow, we don't know who initiated or what parameters were used (in my mind the user_code must have a one-to-one mapping to original request). If we want to support having an index like the one proposed, we would need to have different user_code verification URL per nid. E.g. for nid=42 the verification url would be https://hydra.example.com/oauth2/device/verify/42 and for nid=17 the verification url would be https://hydra.example.com/oauth2/device/verify/17. I have to say that I don't really like this, especially taking into account that the user may have to manually write the URL down on their browser.
IMO the migration should look something like the following:
CREATE TABLE IF NOT EXISTS hydra_oauth2_device_auth_codes (
device_code_signature VARCHAR(255) NOT NULL PRIMARY KEY,
user_code_signature VARCHAR(255) NOT NULL,
request_id VARCHAR(40) NOT NULL,
requested_at TIMESTAMP NOT NULL DEFAULT NOW(),
client_id VARCHAR(255) NOT NULL,
scope TEXT NOT NULL,
granted_scope TEXT NOT NULL,
form_data TEXT NOT NULL,
session_data TEXT NOT NULL,
subject VARCHAR(255) NOT NULL DEFAULT '',
device_code_active BOOL NOT NULL DEFAULT true,
user_code_state SMALLINT NOT NULL DEFAULT 0,
requested_audience TEXT NULL DEFAULT '',
granted_audience TEXT NULL DEFAULT '',
challenge_id VARCHAR(40) NULL,
# device_code and user_code share the same lifespan
expires_at TIMESTAMP NULL,
nid UUID NULL,
FOREIGN KEY (client_id, nid) REFERENCES hydra_client(id, nid) ON DELETE CASCADE,
FOREIGN KEY (nid) REFERENCES networks(id) ON UPDATE RESTRICT ON DELETE CASCADE
PRIMARY KEY (device_code_signature, nid)
);
CREATE INDEX hydra_oauth2_device_auth_codes_request_id_idx ON hydra_oauth2_device_auth_codes (request_id, nid);
CREATE INDEX hydra_oauth2_device_auth_codes_client_id_idx ON hydra_oauth2_device_auth_codes (client_id, nid);
CREATE INDEX hydra_oauth2_device_auth_codes_challenge_id_idx ON hydra_oauth2_device_auth_codes (challenge_id);
CREATE INDEX hydra_oauth2_device_auth_codes_user_code_signature_idx ON hydra_oauth2_device_auth_codes (user_code_signature);
(Disclaimer: I haven't tested this, so there may be some issues with it)
The reason there is a user_code_state field is that the user_code has 3 states, that is active(0), used(1) and revoked(2). Alternatively we could create 2 columns user_code_active and browser_flow_completed, but I think that having a single column is better.
To optimize the user_code_signature index, we could create a unique partial index (this should work on postgres and cockroach, we probably can find a workaround for mysql):
CREATE UNIQUE INDEX hydra_oauth2_device_auth_codes_user_code_signature_idx ON hydra_oauth2_device_auth_codes (user_code_signature) WHERE user_code_state = 0;
This should be a big performance improvement on the current db queries.
@zepatrik I suggest that as a way forward:
- If you agree with what I described for fosite, I start making the changes in fosite (shouldn't be much work). The hydra PR is blocked by the changes on fosite, so IMO this should be top priority.
- We try to come up with a consensus on what the table schema should be, if this proves hard to do over comments/chat we can set up a call
- I start making the changes on Hydra, unless something unexpected comes up I think it should be straight forward and I should be able to handle it on my own. If I face something blocking or it turns out that I need to refactor more parts of the code, I will ask for your help/contribution.
I agree with the dependency here. I think now would be a good time to set up a call and discuss the schema in detail. I'll reach out via email.
We agreed on the proposed table schema. This is the refined and detailed version of the flowchart:
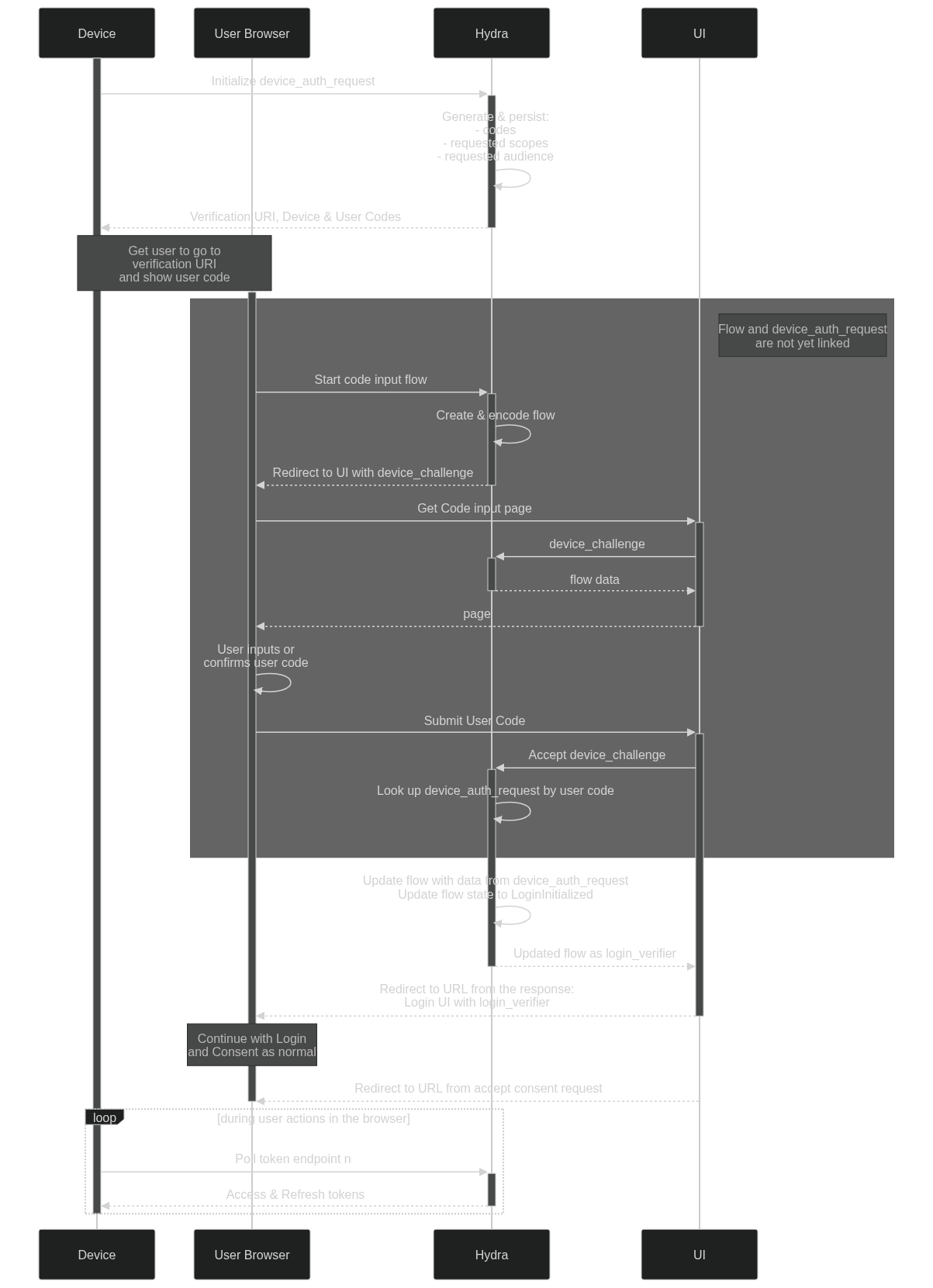
We agreed on the proposed table schema. This is the refined and detailed version of the flowchart:
At the end of the User-Browser login flow part, It's good to redirect the user to a "post device login webpage" so the user knows he can safely close his Browser webpage and that the device is authenticated succesfully.
I don't see this being mentioned, Is this handled ?
At the end of the User-Browser login flow part, It's good to redirect the user to a "post device login webpage" so the user knows he can safely close his Browser webpage and that the device is authenticated succesfully.
Yes, this is part of the "redirect to URL from accept consent response". There will be a config setting for that page.
I updated the database schema and refactored the logic a little. I tested it on postgres with ~1M rows and it looks like all queries are using the indexes:
@zepatrik please have another look when you can
After some out-of-band discussions, I have created a new PR (https://github.com/ory/hydra/pull/3912) using the same commits but from a different fork. Please let me know if you think that the comments should be moved to the new PR or not.