Add optional O_DIRECT flag for POSIX file transport
We're currently using ADIOS2 to dump data streams from 40-GBit network to a local SSD RAID system. In it's current form, ADIOS does not exceed ~1.6 GB/s write speed on our RAID system capable of >6 GB/s sustainable write speed.
Why is this feature important?
To unlock the maximum write performance on local storage.
What is the potential impact of this feature in the community?
It may gather potential new users which struggle writing large amounts of data locally.
Is your feature request related to a problem? Please describe.
As stated, writing files without the O_DIRECT flag will drastically lower maximum performance. In our case, we need at least 3.5 GB/s sustained write speed.
Describe the solution you'd like and potential required effort
Adding the O_DIRECT flag when setting up the file handles in the POSIX transport should be sufficient as a first step. Potentially necessary memory alignment and padding may be left to the user. This assumes that any kind of internal buffer between the user data and writing data is properly aligned using a aligning allocator (I'm not too familiar with the inner workings of ADIOS2 regarding this).
Describe alternatives you've considered and potential required effort
Our current alternative is to dump data with a very primitive data dumper calling the syscall write after generating the file descriptor with the appropriate O_DIRECT flag. So we're left with two options: enhance ADIOS to meet our requirements on data throughput OR move away from ADIOS2 and instead implement our own meta-data handling.
Additional context O_DIRECT man page
Thank you for the observation. We never had the O_DIRECT flag as it destroys performance on Lustre/GPFS parallel file systems. They like their buffering mechanisms to be used. So, we cannot just add this flag into the POSIX transport but maybe we can add it as an option or create a specific transport for SSD or SSD RAID where this would work best.
@DominicWindisch good point. It'd be interesting if you could measure the benefits of O_DIRECT on your system, just fork ADIOS2 and add the flag. As @pnorbert pointed out, O_DIRECT is not a silver bullet for all systems, but can be somehow added proven it makes a difference. Thanks!
Hey guys,
we've been trying to get the O_DIRECT flag to work with the BP4 engine for a bit now. Since the O_DIRECT mode poses constrains on buffer alignment and write block sizes, we've been trying to add the respective padding at some places (mainly after serializing data, before writing). We're able to write data now, however, we broke the BP4 format at some point with the padding. bpls can only read parts of the data correctly.
TL;DR: is there any kind of reference for the BP4 file format itself? Like header structure, PGI and VMD descriptions, what part of information goes into which file (data, idx, ...)? We couldn't find any and it's quite a bit to reverse engineer.
Thanks in advance!
@DominicWindisch If we need to change file format, we need to talk asap about BP5, which is one month from release. The data files there are aligned already (aligment size set by a parameter). We think there is no point in modifying metadata files, only the data files. Can you contact me and talk about this?
@pnorbert That might a good idea to keep in mind for BP5. Still, alignment is less of a problem (even in BP4). Aligning the containers in adios was actually quite easy by adding a posix_memalign in the BufferSTL constructor.
The problem we gave up on was writing the data in the correctly sized chunks. Every call to write needs to be made with a size that is a multiple of the block size of the device (512 bytes in our case). To achieve this with adios, we padded the data after serialization to the next multiple of 512 bytes. With this, we could at least write the data to disk (i.e. any restrictions imposed by the O_DIRECT mode where met). We did not change the metadata or index files.
Checking these padded files with bpls has shown all the variables names, types and sizes correctly; however, all payload data but the first block of the first variable where messed up.
I can only assume that this might be easy to fix by correcting an index table somewhere. Maybe I'm wrong and the reader calculates the position of the next variable based on the given variable size and we cannot add padding at all without breaking BP4. However, without any clear documentation of the format itself, I didn't want to bother disecting each of the hard-coded offsets in the BP4Reader/Writer, BP4Serializer etc.
For now, we've moved on to using HDF5 natively (i.e. using H5cpp) which allready includes a direct IO mode and meets our throughput requirements. However, we would gladly help to develop / test a direct IO version of BP5.
Edit: Since O_DIRECT imposes these restrictions, it might also be a good idea to only open the data file with this flag anyways. Metadata and index files receives way less data and could therefore be written without the O_DIRECT mode (so we don't have to pad this comparatively small data each time).
These things would be vastly easier with BP5 because the file data block offset handling (managed by the BP5Engine) is separated from the individual variable offsets inside each data block (managed by the BP5Serializer).
@eisenhauer Well that sounds good. Would it be easier in terms of adding it to the format or is it supported allready, i.e. is there a way to control the file data block offset increments? Should we test using BP5 or is that too early?
in BP5, a parameter FileSystemPageSize controls the alignment of buffers (each buffer in a vector of buffers). The default value right now is 4096 so this should already cover your use case.
It may be a problem with Put(... Deferred) calls, where a user pointer is used as one buffer in the vector, so that should be avoided in a test example.
testing is not too early. We want to release BP5 in a month, so any modification to the file format itself should get into it before that. Although it looks like there is no need to change the format, this is not known until it works properly.
I've switched to the BP5 engine. Alignment should be fine using the 4096 FileSystemPageSize. However, the problem of arbitrary chunk sizes during write calls remains. Is there any further option to adapt this? I can't write any data as long as the write chunk sizes are not divisible by the block size (write fails with errno 22 - invalid argument).
In general, would it make sense to add a new adios::Mode, e.g. direct, which triggers a forced block size for each write call? (One would probably have to fallback to adios::Mode::Write for the metadata and index files to prevent exzessive padding)
@DominicWindisch We added DirectIO support to BP5. When PR #3053 is merged into master, would you mind to try it out on your system? The BP5 parameters are
io.SetEngine("BP5");
io.SetParameter("DirectIO", "true");
io.SetParameter("DirectIOAlignOffset", "512");
io.SetParameter("DirectIOAlignBuffer", "512");
The default alignment DirectIOAlignOffset (for file offsets) is 512. The alignment for memory pointers (DirectIOAlignBuffer) equals the file alignment value unless set otherwise. Every write operation should be an integer multiple of the file alignment size.
There is no setting for min/max chunk size, that some systems (AIX) would want us to follow to avoid falling back to buffering. Let me know if you know this is an issue in your RAID system.
As we suspected, there was no need to change the file format, all is done with managing the chunks in memory properly.
Put(.. Deferred) works fine, because we force a copy into aligned buffers before writing.
@DominicWindisch Can you please give us some feedback on this in a couple of weeks? We are almost ready for code freeze and we plan to have a release soon. Thanks
@pnorbert Sorry, I didn't see you already merged into master. I'll check this until next week.
@pnorbert I got the example helloBPWriter to work with BP5 in direct mode on our RAID system.
I'll check performance on our data acquisition system next.
Hey @pnorbert ,
I've a run a few preliminary tests. I made sure that ADIOS compiled with the ADIOS2_HAVE_O_DIRECT flag and permissions were also set correctly. Unfortunately, the performance does only slightly exceed the buffered IO using BP4 and is nowhere near the theoretical limit.
You can see our preliminary results in this graph (10 runs per config for HDF5 and ADIOS, 2 runs per config for BP5, hence smaller error bars):
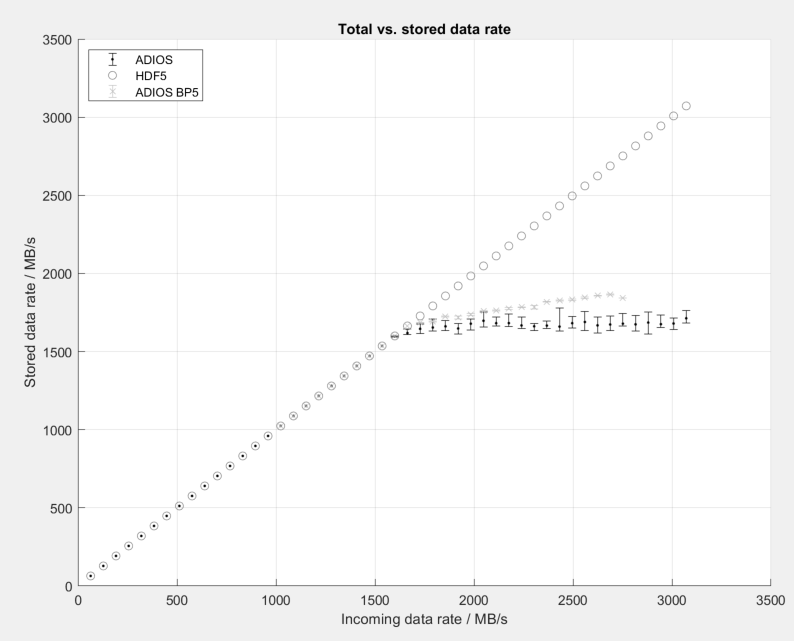
We have extensively tested BP4 to find settings for maximum performance on our system and we did not change any setting (like internal buffer sizes, alignment, etc) between these runs. We only switched the method to write our image buffers between BP4, BP5 and native HDF5.
Writing one frame of the image buffer using ADIOS essentially happend using
engine.BeginStep();
engine.Put<T>(var, data); // using adios::mode::Sync for BP5 based on your comment above didn't affect performance
engine.EndStep();
with frames coming in at a rate of 2000 Hz and each frame containing 1000 lines of data with increasing width (16 to 768 pixels), hence the increasing data rate.
I can only assume that there's some internal buffer somewhere which messes with the alignment (we had similar issues with our initial direct IO HDF5 wrapper causing internal copies into aligned buffers); however, I don't have the time at the moment to extensively investigate this.
Thank you for the measurements. Are your buffers (data) already aligned properly? In the current implementation we force copy of data into the aligned internal buffers when directio is turned on (i.e. Synv and Deferred work the same). We did not implement managing properly user pointers that are already aligned. A memcpy of a couple of GB certainly limits the performance.
In any case, can you send me (by email) the profiling.json from the bp4 and bp5 output? And also a bpls -la and bpls -lat listing of those files? I would like to understand better the behavior of the IO. Thank you.
Are your buffers (data) already aligned properly?
Yes, we're using posix_memalign and mlock on the respective data buffers.
In the current implementation we force copy of data into the aligned internal buffers when directio is turned on (i.e. Synv and Deferred work the same). We did not implement managing properly user pointers that are already aligned.
It would certainly be great to remove this copy whenever possible. Native HDF5 does the same whenever direct IO is enabled but buffers (or write chunk sizes) are not correctly aligned/sized. This additional copy lead to the same performance drop as is apparent in BP5. We could actually see this really nicely in HDF5 because some large frame sizes worked without errors whilst smaller ones lost a ton of frames - turned out some of the larger files we're divisible by the block size conincidentally whilst the non-divisable frame sizes (despite very much lower overall data rate) required this aditional copy into aligned buffers.
In any case, can you send me (by email) the profiling.json from the bp4 and bp5 output?
We had profiling disabled in our production environment (to arguably increase performance and since we don't need it). I'll try to get you a profiled run and the bpls outputs next week. Feel free to remind me when I forget about it. 😬
So now do you make sure that your data buffer is both aligned and its size is a multiple of block size?
We at least make sure our frame data is aligned correctly. Further, HDF5 has a "copy buffer size" when setting up the direct IO stuff with H5P_set_fapl_direct. By trial and error, we found this to work best with cbuf_size set to the next larger multiple of the block size (4096B in our case). But to be frank, I have no idea what exactly goes on under the hood there.
We write all our frame buffer data in chunks using H5Dwrite_chunk. The chunks are setup as large as one frame buffer (without making sure the size is a multiple of block size) to mimic the ADIOS writing-in-steps paradigm. Again, I can only guess what exactly HDF5 does do maintain alignment; the H5P_set_fapl_direct sounds like it's padding with zeros to create "holes" in the file.