zfs
 zfs copied to clipboard
zfs copied to clipboard
arc metadata exhaustion handling in linux and freebsd with large number of datasets
System information
| Type | Version/Name |
|---|---|
| Distribution Name | Ubuntu / FreeBSD |
| Distribution Version | 22.04.1 LTS / 13.1-RELEASE |
| Kernel Version | 5.15.0-52-generic / 13.1-n250148-fc952ac2212 |
| Architecture | amd64 / amd64 |
| OpenZFS Version | zfs-2.1.6-0york1~22.04 / zfs-2.1.4-FreeBSD_g52bad4f23 |
Describe the problem you're observing
When creating and mounting a large number of datasets, thousands to tens of thousands, there are some differences in arc handling between linux and freebsd.
Linux observed behaviours: As datasets are created and mounted some information about them is stored in the arc's metadata cache and dnode cache. After enough datasets are created eventually the high water mark for metadata is reached. This causes zfs to start pruning arc to remove unneeded records, but it appears that the metadata records for mounted datasets must always be in arc. This then causes contention and a arc_prune will consume all cpu resources trying to remove records that are constantly being readded.
Freebsd observed behaviours: As datasets are created and mounted some information about the datasets are stored in arc's metadata cache and dnode cache. When enough datasets are created to cross the metadata high water mark threshold and arc pruning starts. Instead of removing only one record are a small number of records at a time the metadata cache is instead flushed freeing up space but not actively refilling the metadata cache with the already mounted datasets. This allows zfs to continue on without arc_prune consuming 100% of the cpu.
The question here is can linux be made to act like freebsd?
Can caching of the datasest be left until it is accessed?
Or being able to free up larger portions of the arc metadata at a time?
This would seem appropriate when doing bulk creations, is also helpful on import to try not to cache everything as it might not be needed right away.
As a note the amount of data on the zpool doesn't matter. This will occur with a blank pool just creating datasets.
Describe how to reproduce the problem
Create a blank pool and start creating datasets. Depending on the size of the system the number of datasets needed to exhaust arc metadata differs. On a machine with 8gb of memory linux started to fail at around 5K using the default parameters Freebsd was able to create over 80K datasets without issues.
Requires bash
#!/bin/bash
for x in {1..10000}
do
echo "creating $x" | tee -a log.txt
zfs create tank/$x
done
Check arc_summary -s arc for usage stats.
The easiest I found was to have arc_summary and htop with zfs modules loaded while creating the datasets
I.E.
watch arc_simmary -s arc linux
gnu-watch arc_summary -s arc freebsd
Include any warning/errors/backtraces from the system logs
Too try to help clarify some of the issues. I've ran some tests to gather data about the differences. The tests were ran on two machines with 8GB of ram. The freebsd machine used the stock settings for zfs on freebsd 13.1 The linux machine is running openzfs 2.1.6. Not the version shipped by canonical but the one from jonathonf's [repository ]. (https://launchpad.net/~jonathonf/+archive/ubuntu/zfs) The only important differences from stock settings are setting the max metadata and dnode limit. I had forgotten to turn them off before running the tests, but they don't affect much as it just increases the number of datasets that can be created. Custom settings for linux:
#Increase amount of arc space dnode entries can use
options zfs zfs_arc_dnode_limit_percent=90
#Increase amount of arc space for metadata
options zfs zfs_arc_meta_limit_percent=90
#Decrease amount of space reserved for root opertations
#Since we have 20TB of disks we don't need 645GB of reserved space 156GB is fine.
options zfs spa_slop_shift=8
#Allow ZED to have a larger buffer for messages
options zfs zfs_zevent_len_max=50000
#Disable deffered resilver
options zfs zfs_resilver_disable_defer=1
Freebsd stats to know:
Stats to know:
Max size (high water): 27:1 7.0 GiB
Metadata cache size (hard limit): 75.0 % 5.2 GiB
On freebsd the default metadata hard limit is 75% of current arc's total size. In freebsd's case this is total ram - 1GB
The first graph is of freebsd's metadata cache size when creating datasets

As can be seen from the graph once the metadata cache reaches around 115% capacity it is flushed and slowly fills backup when new datasets are created. I stopped the test at around 27K datasets as I had gotten enough data to show the trend.
Linux stats to know:
Max size (high water): 16:1 3.9 GiB
Metadata cache size (hard limit): 90.0 % 3.5 GiB
Linux defaults to 50% of ram for arc
The metadata hard limit is modified to be 90% instead of the normal 75%
The second graph is of linux's metadata cache when creating datasets.
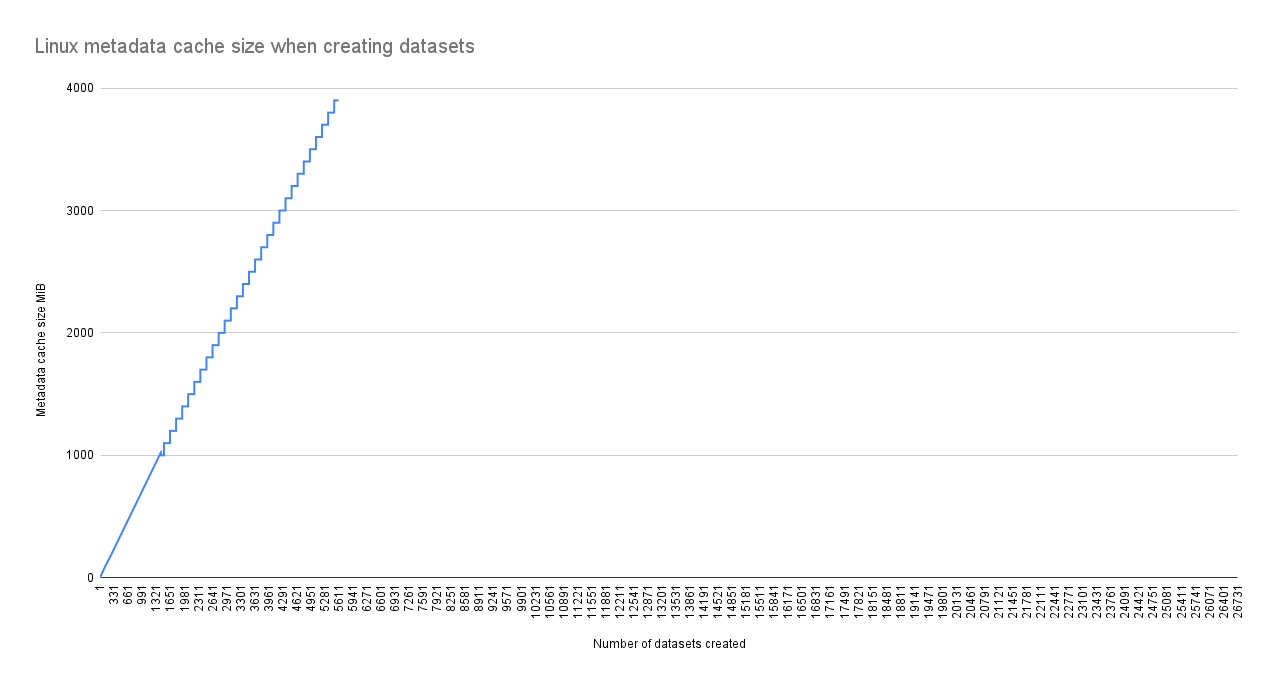
The graph abruptly ends at the 5600 mark as zfs was no longer able to create any new datasets since arc_prune and arc_evict were trying to clean up the metadata cache to get under the hard limit.
Linux arc_prune arc_evict cpu usage

Combined graph
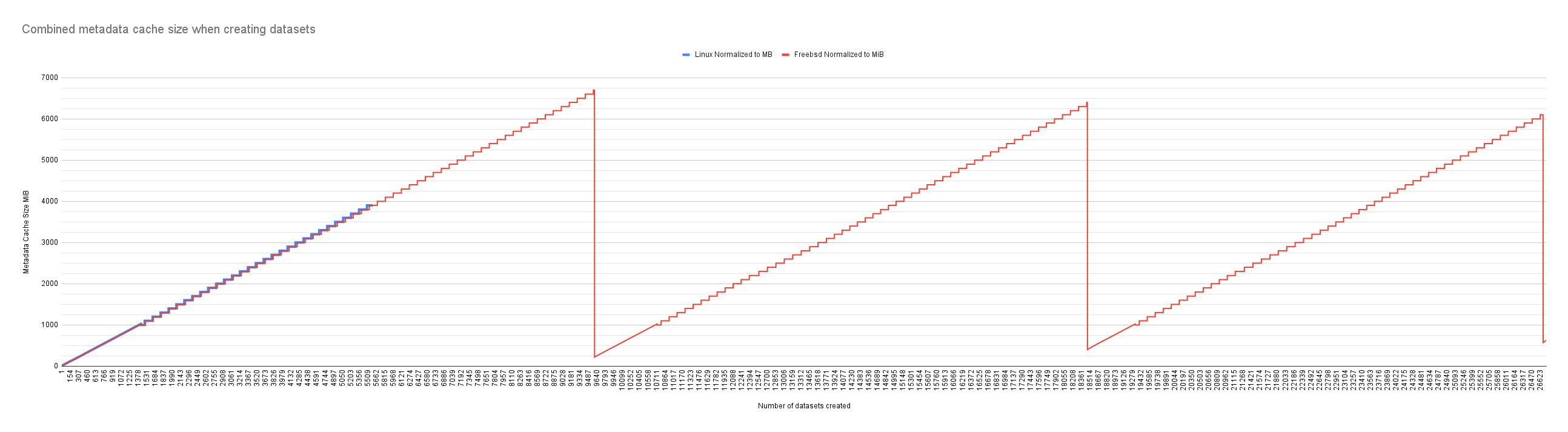
The raw arc_summary logs during each datasets creation and svg versions graphs can be found at https://github.com/manfromafar/linux-vs-freebsd-arc-stats
Datasets were created as fast as possible. Used a simple for loop that would print dataset # created, time stamp, create the dataset, print arc_summary stats.
Linux arc_summary -s arc log with datasets created, time, and arc report https://github.com/manfromafar/linux-vs-freebsd-arc-stats/blob/main/linux/linux_arc_stats-2022-11-30-10-39.txt
Freebsd arc_summary -s arc log with datasets created, time, and arc stats https://github.com/manfromafar/linux-vs-freebsd-arc-stats/blob/main/freebsd/freebsd_arc_stats-2022-11-30-11-52.txt
Have you been able to mitigate the issues under linux? The general issues around arc_prune and arc_evict getting stuck using 100% CPU is severely impacting the usability of openzfs.
arc_evict and arc_prune logic was significantly rewritten in OpenZFS 2.2. It would be interesting to hear any feedback about the new behavior.
I think I've come to the conclusion that throwing 256GB of ram at this problem is easier than other options and will most likely resolve my issues. The underlying problem seems to be that I have a absolute ton of files/directories and the pressure on the arc for metadata and dnode caching is simply too much for the available ram on the host.
2.2 by itself doesn't seem to be able to fix having insufficent memory but it does appear to handle it better. In particular, arc_prune and arc_evict don't get stuck at 100% of cpu.
not sure, but maybe there is room for improvement for storing dnode&metadata in ram more efficiently? i‘m still curious , why metadata seems to be stored so much more efficient (i.e. space saving) on disk , when ram is so much more precious ressource.rolanddir/file metadata consumes enourmous amount of ARC · Issue #13925 · openzfs/zfsgithub.comVon meinem iPhone gesendetAm 07.12.2023 um 21:23 schrieb kgcgs @.***>: I think I've come to the conclusion that throwing 256GB of ram at this problem is easier than other options and will most likely resolve my issues. The underlying problem seems to be that I have a absolute ton of files/directories and the pressure on the arc for metadata and dnode caching is simply too much for the available ram on the host.
—Reply to this email directly, view it on GitHub, or unsubscribe.You are receiving this because you are subscribed to this thread.Message ID: @.***>
arc_evict and arc_prune logic was significantly rewritten in OpenZFS 2.2. It would be interesting to hear any feedback about the new behavior.
@amotin I just built the 2.2.2 binaries using ubuntu 22.04 and tried again. The test at first appeared better I got to 9.5K datasets before exhausting memory causing kswapd0 to consume cpu.
Unforuntantly although the limit is higher now on linux a limit is still reached It looks like the limit of 9.5k datasets is directly tied to arc being able to consume more memory on 2.2.X. Unless 2.2.X changes the default from 50% of ram on linux, which should limit arc to ~4GB but when zfs gives up arc reaches about ~6GB of usage.
arc summary before memory exhaustion
creating 9510 2023-12-07
------------------------------------------------------------------------
ZFS Subsystem Report Thu Dec 07 2023
Linux 5.15.0-89-generic 2.2.2-1
Machine: ubuntushiftfstest (x86_64) 2.2.2-1
ARC status: HEALTHY
Memory throttle count: 0
ARC size (current): 163.7 % 6.3 GiB
Target size (adaptive): 6.2 % 248.0 MiB
Min size (hard limit): 6.2 % 248.0 MiB
Max size (high water): 16:1 3.9 GiB
Anonymous data size: 0.0 % 0 Bytes
Anonymous metadata size: 0.0 % 0 Bytes
MFU data target: 37.1 % 2.3 GiB
MFU data size: 0.0 % 0 Bytes
MFU ghost data size: 0 Bytes
MFU metadata target: 12.4 % 776.8 MiB
MFU metadata size: 41.2 % 2.5 GiB
MFU ghost metadata size: 187.9 MiB
MRU data target: 37.1 % 2.3 GiB
MRU data size: 0.0 % 0 Bytes
MRU ghost data size: 0 Bytes
MRU metadata target: 13.3 % 830.4 MiB
MRU metadata size: 58.8 % 3.6 GiB
MRU ghost metadata size: 157.2 MiB
Uncached data size: 0.0 % 0 Bytes
Uncached metadata size: 0.0 % 0 Bytes
Bonus size: 0.4 % 23.8 MiB
Dnode cache target: 90.0 % 3.5 GiB
Dnode cache size: 4.3 % 151.9 MiB
Dbuf size: 0.6 % 40.4 MiB
Header size: 0.4 % 25.9 MiB
L2 header size: 0.0 % 0 Bytes
ABD chunk waste size: 0.1 % 5.0 MiB
ARC hash breakdown:
Elements max: 103.7k
Elements current: 100.0 % 103.7k
Collisions: 31.8k
Chain max: 3
Chains: 4.8k
ARC misc:
Deleted: 13.6k
Mutex misses: 3
Eviction skips: 0
Eviction skips due to L2 writes: 0
L2 cached evictions: 0 Bytes
L2 eligible evictions: 3.7 GiB
L2 eligible MFU evictions: 6.3 % 234.0 MiB
L2 eligible MRU evictions: 93.7 % 3.4 GiB
L2 ineligible evictions: 0 Bytes
After rebooting and importing the pool memory usage spikes back up almost full but the server is more responsive. If I try to run zfs list arc_prune and arc_evict show back up consuming cpu but at least the list does return and once finished arc_prune and arc_evict stop consuming cpu
The pool here is looking like this. I think the biggest thing here was just to allow the dnode cache to get this large and to set primarycache to metadata only. (Read performance on the pool is not a problem and it's all backed by SSDs anyway.)
Dnode cache target: 50.0 % 4.0 GiB
Dnode cache size: 77.6 % 3.1 GiB