smartnoise-sdk
 smartnoise-sdk copied to clipboard
smartnoise-sdk copied to clipboard
OpenDPException Error - Selective on Datasets
Hi Team,
We are facing an issue with CTGAN synthesizers, esp., DPCTGAN synthesizer. We are getting an OpenDPException error- relating to measurement check. The error is getting raised on few datasets whereas it (DPCTGAN) was working fine for other datasets. We do expect this based on d_in and d_out variables inside the package. We are wondering if there is a way to bypass the error.
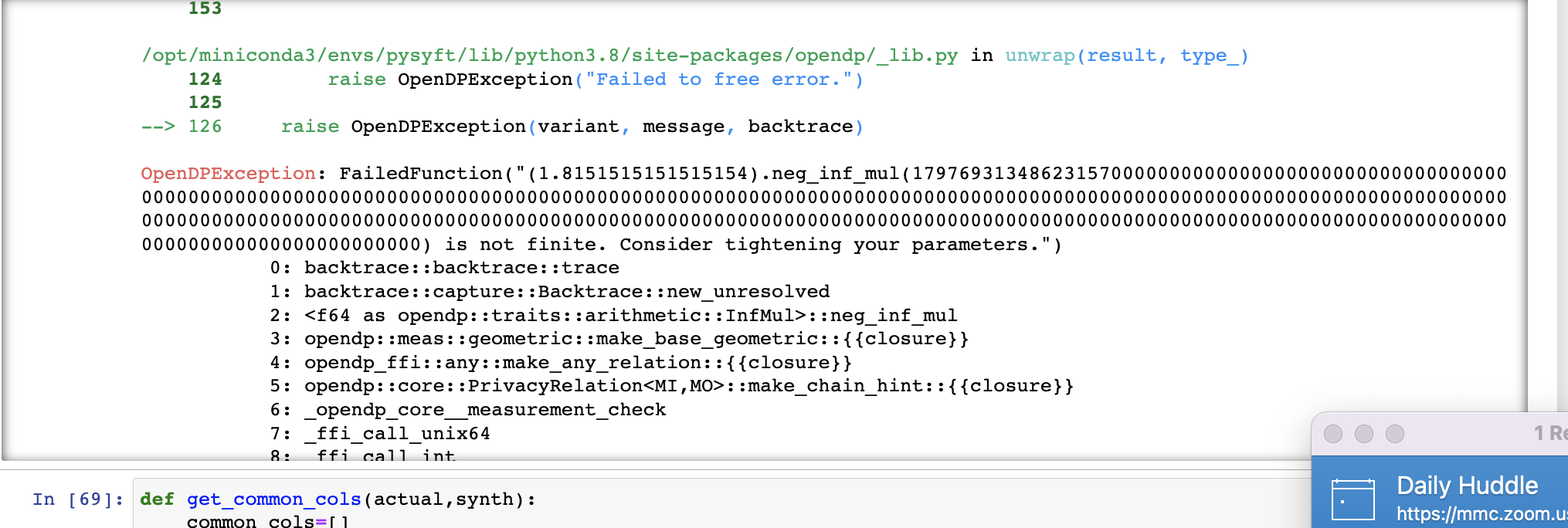
The OpenDP library throws this error when a privacy-sensitive calculation overflows. What I see here is an epsilon of ~1.8, and a massive noise scale. It's really curious to me that the library is adding such a large amount of noise.
Regardless, I'd only anticipate this issue in OpenDP 0.4. OpenDP 0.5 should perform the arithmetic in a way that doesn't overflow, but I don't think the SDK supports 0.5 yet. That would make the error go away, but there still isn't much utility in sampling with this much noise. cc @joshua-oss
I'll take a look at this later today. This is in the code that calculates noisy counts of frequencies from the categorical columns for sampling. We use category_epsilon_pct percent of the total epsilon, and divide it among all categorical columns, so it could end up with a very large noise scale if number of categorical columns is large. I'm not sure this step is even necessary, but nobody has done the work to show that sampling from the actual frequencies is safe.
@dsrishti, what's the rough magnitude of number of categorical columns and what is category_epsilon_pct set to?
I also have on my list to switch to v0.5, that should help with multiple issues.
I think this may be related to the preprocessor_eps parameter that was recently added to support preprocessing of continuous values. The budget for preprocessing defaults to 1.0, and is subtracted from the total epsilon available, whether the preprocessor actually uses any epsilon or not. Then, after subtracting the preprocessor epsilon, category_epsilon_pct is subtracted from the remaining budget. By default, the amount subtracted from the remainder is 10%. That fraction of the remaining epsilon budget is divided among all categorical columns to build the frequency tables for sampling. So, for example, using an epsilon of 1.5 on ten columns would result in 1.0 spent on preprocessing, with 0.45 left for actual training, and 0.005 for each column's frequency table. I think this behavior will be quite unexpected for most people.
If you are using only categorical columns and BaseTransformer, you can set preprocessor_eps to 0, like:
synth = PytorchDPSynthesizer(0.5, DPCTGAN(preprocessor_eps=0.0))
Let me know if this looks like the cause of what you are seeing. I can add some better diagnostic messages and defaults so it is more clear what the synthesizer is doing. We are also planning to move preprocessing out of the synthesizers entirely, which may help to avoid surprises like this.
I'll take a look at this later today. This is in the code that calculates noisy counts of frequencies from the categorical columns for sampling. We use category_epsilon_pct percent of the total epsilon, and divide it among all categorical columns, so it could end up with a very large noise scale if number of categorical columns is large. I'm not sure this step is even necessary, but nobody has done the work to show that sampling from the actual frequencies is safe.
@dsrishti, what's the rough magnitude of number of categorical columns and what is category_epsilon_pct set to?
I also have on my list to switch to v0.5, that should help with multiple issues.
@joshua-oss : We did input all of the columns as categorical columns. There are around 33 columns on that front. We also tried parameter tuning by testing for category_epsilon_pct being set to 0.1 to 0.5. But the error didn't go away.
I think this may be related to the
preprocessor_epsparameter that was recently added to support preprocessing of continuous values. The budget for preprocessing defaults to 1.0, and is subtracted from the total epsilon available, whether the preprocessor actually uses any epsilon or not. Then, after subtracting the preprocessor epsilon,category_epsilon_pctis subtracted from the remaining budget. By default, the amount subtracted from the remainder is 10%. That fraction of the remaining epsilon budget is divided among all categorical columns to build the frequency tables for sampling. So, for example, using an epsilon of 1.5 on ten columns would result in 1.0 spent on preprocessing, with 0.45 left for actual training, and 0.005 for each column's frequency table. I think this behavior will be quite unexpected for most people.If you are using only categorical columns and BaseTransformer, you can set
preprocessor_epsto 0, like:synth = PytorchDPSynthesizer(0.5, DPCTGAN(preprocessor_eps=0.0))Let me know if this looks like the cause of what you are seeing. I can add some better diagnostic messages and defaults so it is more clear what the synthesizer is doing. We are also planning to move preprocessing out of the synthesizers entirely, which may help to avoid surprises like this.
Thanks @joshua-oss , @Shoeboxam , we will test this parameter out and see if we are able to resolve the issue.
@joshua-oss , just wanted to let you know that we have tested preprocessor_eps = 0 and it's working for lower epsilon values but blowing up at higher epsilon values (with same opendpexception error). Is there an acceptable range of epsilon values we can input for the synthesizer when you don't care about privacy? We tried disabled_dp=True, but it's throwing an unbound error that epsilon is called locally before it was being defined!
I have released smartnoise-synth==0.2.8.1 with some minor diagnostic messages that clarify how much epsilon is available for each step. That might help diagnose what's happening. That version also updates to OpenDP v0.5.0, which might solve the noise scale search for category epsilon percentage.
The other thing you could try is setting category_epsilon_pct=None. I am now convinced that we don't need to use noisy counts in the sampler at all. Since we are not using log frequencies anyway, the effect of using non-privatized counts on sampling will always be to sample records uniformly. We added the noisy counts as a conservative choice mainly because everyone sees that there are counts being used, and asks why that's safe. It's a holdover from the original ctgan paper that's a spandrel in absence of log frequencies.
Rather than sticking with the current approach of counting and then sampling based on counts, I plan to change the code to just sample uniformly, so it's more obvious that's what's happening. In the meantime, you can skip the noisy count step by setting percentage to None. If concerned about that part, you could also fiddle with the percentage in a high epsilon regime to make sure it's using a reasonable small epsilon for the category counts. The diagnostics should help see what the effective epsilon for each column's counts will be, and you can adjust percentage to get the result you want.