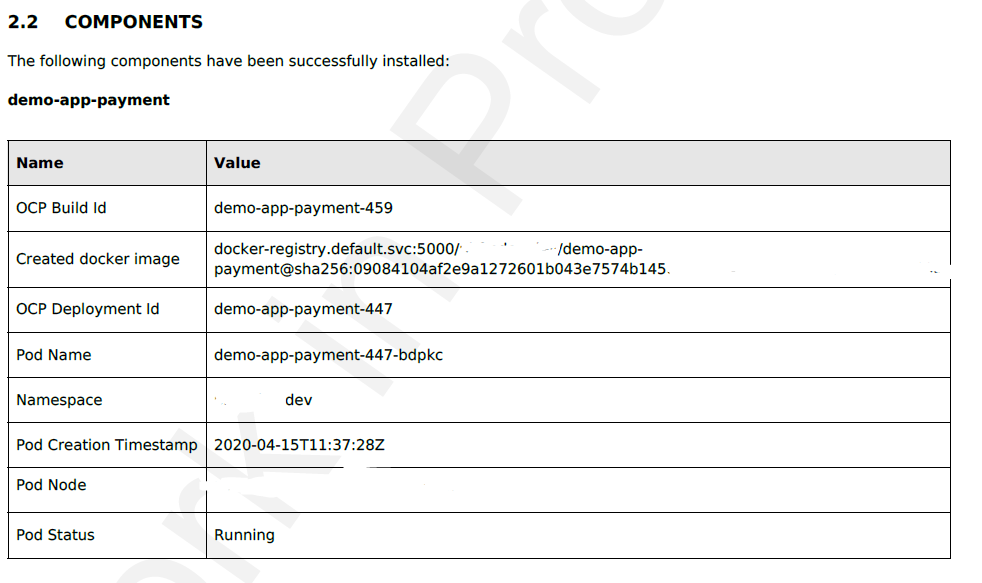
Orchestration Pipeline: Support multiple replicas
The orchestration pipeline only deals with one replica of a pod. This somehow defeats the purpose of OpenShift, allowing to scale horizontally easily. Even when users do not need to scale massively right now, I would see it as a common best practice in the industry to have "two of everything" to avoid locking yourself into a situation where it only works with one instance.
Affected areas of the shared lib:
- documents
- checking for running pods after deployment and collecting information from them
- ?
FYI @clemensutschig @metmajer I'm certain we will get requests for that soonish :)
Thanks @michaelsauter, you are a mind reader. 2 instances is also the minimum to allow for 0-downtime upgrades of application components. +5 from me :-)
Michael you could try. I guess it will work.. docs will just show one pod i guess..
@metmajer I think the upgrade downtime is not directly related. In OpenShift, you can have rolling updates, which start a 2nd pod before terminating the old one. If you are careful with readiness/liveness probes, you can have zero downtime without running 2 pods continuously.
I'm not going to start working on it now. I have to finish the other stuff (merging back into main branch, checking before release that all previously released commits are part of the new release, and a few loose ends) first. I think I won't have the capacity to work on this for v3 ... let's see how the other stuff progresses.
The TIR docs should be adapted, since with the introduction of Cloud and other non openshift components, IMO the best way would be to provide a section where the different usecases inject whatever html data they want/need to show. That way, adding more information about all the pods created would only mean a change in the shared library instead on the template. A good candidate would be section 2.2 of TIR. Right now, the table is hardcoded in the template, but for re-usability reasons, it should not be.