arpack-ng
 arpack-ng copied to clipboard
arpack-ng copied to clipboard
Add Ritz options (largest/smallest in real/imaginary parts) for compl…
This pull request changes only the file "arpack.hpp"
Pull request purpose
For complex eigenvalue routines, the Ritz value options "LR", "SR", "LI", "SI" were not provided in the C++ binding. Now they are included. For details, please refer to the book "ARPACK Users' Guide" page 105, Table A.9
Hi, what is the standard folder/file to add tests here? Did you mean tests for CI purpose?
probably here: https://github.com/opencollab/arpack-ng/blob/master/TESTS/icb_arpack_cpp.cpp
Test of the complex routine now added. Some further explanations on the changes:
- "complex_symmetric_runner" is renamed to "complex_nonsymmetric_runner". In ARPACK there is no complex routines designed specifically for "symmetric" matrices, so the name "symmetric" is confusing here.
- The complex matrix is changed from (i,i) to (i,-i). Otherwise the test of "largest_imaginary" simplest reproduces "largest_magnitude" and we could not tell if "largest_imaginary" is working.
- I added an argument "arpack::which const& ritz_option" so not to rewrite the "complex_nonsymmetric_runner" for "largest_imaginary"
Yes, happy to. I see the file "CHANGES" starting like the follow, and should I put my changes above/below "arpack-ng - 3.9.0"?
arpack-ng - 3.9.0
[ Jose E. Roman ]
- Avoid using isnan() in tests, since is GNU-specific
[ Tom Payerle ]
- Change the continuation line format for stat.h, debug.h
I have added a few more changes to the test file "icb_arpack_cpp.cpp":
-
change "ldz" to the minimal allowed value "N", "z" to the minimal allowed size "ldz * nev", and "d" to the minimal allowed size "nev";
-
change "lworkl" in the real symmetric runner to the correct minimal value "ncv * (ncv + 8)" (for reference, see SRC/ssaupd.f, SRC/dsaupd.f);
-
change "lworkl" in the complex nonsymmetric runner to the correct minimal value "ncv * (3 * ncv + 5)" (for reference, see SRC/cnaupd.f, SRC/znaupd.f);
-
remove initialization of the array "select", since it is only a workspace in the current context (initial value not used);
-
change size of the "ipntr" array in the real symmetric runner from 14 to the minimal allowed value "11" (for reference, see SRC/ssaupd.f, SRC/dsaupd.f);
-
remove initialization of iparam[4] -- it is only an output;
-
change the reverse communication condition "while (ido != 99)" to the more specific "while (ido == 1 || ido == -1)" for the standard eigenvalue problems used in the test;
-
throw exception when info < 0;
-
added and removed a few comments for clarity.
Same changes in file icb_parack_c.c added.
You meant icb_arpack_c.c? icb_parpack_c.c is unchanged.
Same changes in file icb_parack_c.c added.
You meant
icb_arpack_c.c?icb_parpack_c.cis unchanged.
You are right -- I meant "icb_arpack_c.c" not the parpack file.
For the initialization discussion: I am neutral in choosing to initialize (or not) the output-only arguments, but inclined to have a consistent treatment of all these arguments in the same function. If we choose to initialize iparam[4] because "initialization is always a good thing", by the same token we should also initialize all other elements in "iparam[0:10]", and also all elements in "ipntr[:]", and also all elements in the eigenvalues -- the list simply goes on... So I feel like just not necessary to do so just particularly for iparam[4], since it is not special at all compared to other variables mentioned above.
What do you think? If you want, I can still switch on ipram[4] initialization...
Can you do the same kind of clean-up for parpack.hpp, icb_parpack_c.c, icb_parpack_cpp.cpp? Thanks!
What do you think? If you want, I can still switch on ipram[4] initialization...
OK, I give you that :)
Can you do the same kind of clean-up for
parpack.hpp,icb_parpack_c.c,icb_parpack_cpp.cpp? Thanks!What do you think? If you want, I can still switch on ipram[4] initialization...
OK, I give you that :)
Thanks! Will do the same for the files you mentioned
@fghoussen
Hi, previously I disabled MPI so the check works. Now, with MPI enabled to work on parpack, I am hitting a failure in the check, which is traced back to an old commit aa970ce with commit message "ILP64 support. (#165)", on file "PARPACK/TESTS/MPI/issue46.f". Here is what I see and what I understand:
--- what I see ---
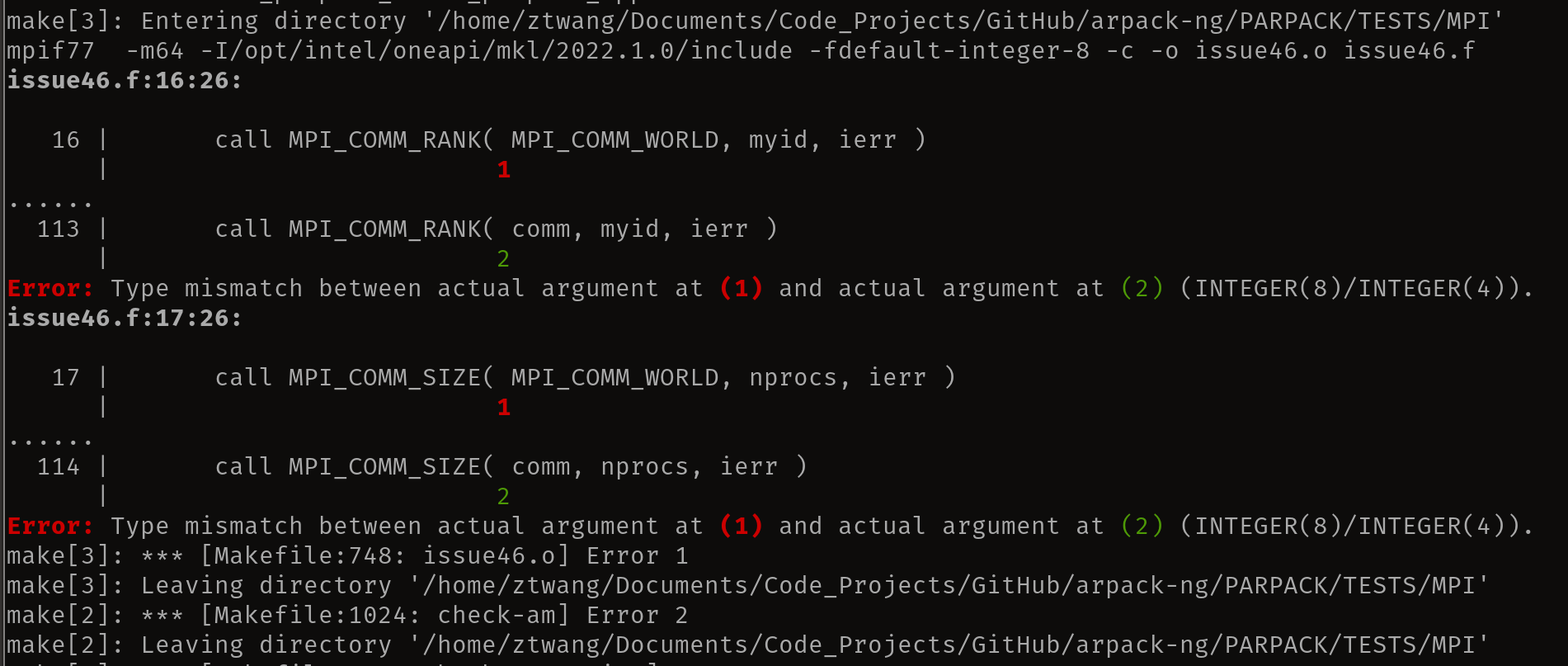
--- what I understand --- The file "issue46.f" started with "integer ierr, comm, color, key, myid, nprocs, cnprocs", until the commit aa970ce when it becomes "integer*4 ierr, comm, myid, nprocs, cnprocs, color" where the commit message points to fixing "ILP64 support".
Now if I look at the discrepancy, "MPI_COMM_WORLD", defined in file "/usr/lib/x86_64-linux-gnu/fortran/gfortran-mod-15/openmpi/mpif-handles.h" line 42 (I am using Ubuntu 22.04 openmpi 4.1.2, and ILP64 is enabled), it says "integer MPI_COMM_WORLD", which explained the error message.
I appreciate your great amount of work in providing the ILP64 support, but also I am a bit scared away trying to fix the issue here: looking at the long commit history related to ILP64 support, I don't think I have enough knowledge/time here to fix the issue at face value without creating newer ones. Would it be possible for the original authors (I see only 3 related to the file "issue46.f") to first fix those issues? I am still happy to do my part on cleaning up the parpack test files once I can pass the check (will be playing with fire if I just edit those test files without being able to compile them).
FYI, here is my environment for reproducing the issues: system: PopOS 22.04 (practically identical to Ubuntu 22.04) MKL: newest, directly downloaded from INTEL website MPI: openmpi 4.1.2 gfortran: 11.2.0
The arpack-ng installation with autotools: export MKL_INC_DIR=${MKLROOT}/include export MKL_LIB_DIR=${MKLROOT}/lib/intel64
FFLAGS="-m64 -I${MKL_INC_DIR}" FCFLAGS="-m64 -I$MKL_INC_DIR" CFLAGS="-DMKL_ILP64 -m64 -I${MKL_INC_DIR}" CXXFLAGS="-DMKL_ILP64 -m64 -I${MKL_INC_DIR}" LIBS="-L${MKL_LIB_DIR} -Wl,--no-as-needed -lmkl_gf_ilp64 -lmkl_tbb_thread -lmkl_core -lpthread -ltbb -lstdc++ -lm -ldl" LIBSUFFIX="ILP64" INTERFACE64="1" ./configure --with-blas=mkl_gf_ilp64 --with-lapack=mkl_gf_ilp64 --enable-mpi --enable-icb --prefix=$HOME/installs
Hmm, looks like the current neighboring pull request is also talking about "issue46.f"? I feel your pain there...
@wztzjhn: do not use INTERFACE64=1 ! Running with MPI on any distro without INTERFACE64 and any LP64 blas/lapack (netlib, MKL, ...) should be OK. :)
Support for ILP64 arpack was a hell... But should be OK now...
Support for ILP64 for parpack (MPI version of arpack) will be even worse... If not impossible: look at 600+ commits here #368... Don't set INTERFACE64!
OK. Will give a try without ILP64. Did not realize that ILP64 does not work with MPI yet...
Just on a different thought: what will be the use case of parallel arpack? In my past experience, the serial arpack actually works well for matrices of dimension ~ 10^7 even up to 10^8. Beyond that point I could see a value of using MPI, also at the same time ILP64 becomes necessary. So in my view MPI and ILP64 really come hand in hand -- it is indeed a pity that the work of combining MPI and ILP64 is such a beast...
@fghoussen Mind if I change expression like "double const x" to "const double x" in these test files? The latter format seems way more commonly adopted.
Please check, while working on the cleaning, I found two bugs (only one fixed as stated in the commit message).
There is one remaining bug (not due to my changes) in the MPI complex (single precision) runner.
To reproduce from the current master branch: change line 113 of file "icb_parpack_cpp.cpp" from "nev=1" to any number bigger than 1. You will see that this single precision complex runner produces multiple (equal to the number of MPI threads) degenerate eigenvalues, while the input matrix has no degeneracy.
This bug did not show up in the normal tests, simply because this bug was known, and somebody changed nev=3 (or nev=9) as in other test files to nev=1, so people look away from the bug. But I am afraid as time goes by people may forget about it and assume it is correct...
To see it more clearly, you can check out my branch, where I have made a template to switch the precision. The latest commit switched the precision from single to double (line 212), which produces the correct results. Once you change that line to "float", it goes back to the old buggy behavior.
After checking the open issues, this remaining bug is actually identical to #332
Had a quick look at pc/znaupd.f, did not find any clear clue. Maybe someone can test the subroutine in pcnaupd.f, to see if the bug is already deep there?
If #372 runs OK (green CI), can you kill e2f0483 and rebase on top of it?
what will be the use case of parallel arpack? In my past experience, the serial arpack actually works well for matrices of dimension ~ 10^7 even up to 10^8.
Indeed, arpack can handle high dimensions (because matrices are sparse). AFAIK, parpak can be used to go higher dimension than arpack (but in practice, it's rare you need that because arpack can go high already), or, go faster than arpack for the same (high) dimension matrices.
it is indeed a pity that the work of combining MPI and ILP64 is such a beast...
Unfortunately, I guess #368 will be a dead end (I am about to close it). I have still hope on this but no time...
Mind if I change expression like "double const x" to "const double x" in these test files?
OK
Please check, while working on the cleaning,
I'll have a look when possible (week-end probably)
There is one remaining bug (not due to my changes) in the MPI complex (single precision) runner. Had a quick look at pc/znaupd.f, did not find any clear clue.
Thanks! Good shot: likely connected to #332.
I cherry-picked e2f0483 in #372 so you can remove it from here.
Clue is likely in between parpack.h and pc/znaupd.f,: checkout ae98874 in #372
To see it more clearly, you can check out my branch, where I have made a template to switch the precision. The latest commit switched the precision from single to double (line 212), which produces the correct results. Once you change that line to "float", it goes back to the old buggy behavior.
If #372 runs OK (green CI), rebase and keep/add both tests in float and double.
If #372 runs OK (green CI), can you kill e2f0483 and rebase on top of it?
Sure. Just making sure of the operations:
- #372 becomes green and is merged into master.
- I add a new branch and cherry pick everything except that bug fix.
- Simply close this pull request, then create a new pull request from the new branch. Is that what you have in mind?
- https://github.com/opencollab/arpack-ng/pull/372 becomes green and is merged into master.
Yes.
- I add a new branch and cherry pick everything except that bug fix.
Simply git rebase -i master and get rid of commits already merged into master (your bug fix).
Simply close this pull request, then create a new pull request from the new branch. Is that what you have in mind?
Push-force and this PR will follow master.
- Fix issue 332 #372 becomes green and is merged into master.
Yes.
- I add a new branch and cherry pick everything except that bug fix.
Simply
git rebase -i masterand get rid of commits already merged into master (your bug fix).Simply close this pull request, then create a new pull request from the new branch. Is that what you have in mind?
Push-force and this PR will follow master.
Thanks! Will do.
Can you rebase? (1-change-1-commit if possible: easier to review)
Done. At this moment all CI's seem to be working, except that the macos is slowly installing the dependencies. Hopefully they will be green.
Just a minor digression: for macos it will be much faster to cache the dependencies in CI. For example, the following is what I used in my other repo for cache in macos:
build-macos-latest:
runs-on: macos-latest
env:
CONDA_PREFIX: /usr/local/miniconda/envs/spintools
DYLD_FALLBACK_LIBRARY_PATH: /usr/local/miniconda/envs/spintools/lib
OMP_NUM_THREADS: 3
MKL_NUM_THREADS: 1
steps:
- uses: actions/checkout@v3
- name: Cache dependencies
id: cache-dep
uses: actions/cache@v3
with:
path: /usr/local/miniconda/envs/spintools
key: ${{ runner.os }}-dep-v3
- name: Install dependencies
if: steps.cache-dep.outputs.cache-hit != 'true'
run: |
echo $SHELL
conda update -n base -c defaults conda
conda info | grep -i 'base environment'
source /usr/local/miniconda/etc/profile.d/conda.sh
conda create -n spintools
conda activate spintools
echo "CONDA_PREFIX: $CONDA_PREFIX"
conda install -c conda-forge mkl mkl-include openmpi boost nlopt spglib
cd /tmp
wget https://github.com/skystrife/cpptoml/archive/refs/tags/v0.1.1.tar.gz
tar xf v0.1.1.tar.gz
mv cpptoml-0.1.1/include/cpptoml.h $CONDA_PREFIX/include
wget https://github.com/stevengj/cubature/archive/refs/tags/v1.0.4.tar.gz
tar xf v1.0.4.tar.gz
cd cubature-1.0.4
make clean
clang -fPIC -c -O3 hcubature.c
clang -fPIC -c -O3 pcubature.c
clang -dynamiclib hcubature.o pcubature.o -o libcubature.dylib
make clean
cp cubature.h $CONDA_PREFIX/include
cp *.dylib $CONDA_PREFIX/lib
- name: make test
run: |
mkdir bin
ls $CONDA_PREFIX/lib
cd src; make clean; make -f makefile_list/mac/Makefile_clang test -j3
export DYLD_FALLBACK_LIBRARY_PATH="/usr/local/miniconda/envs/spintools/lib"
export MKL_NUM_THREADS=1
cd ../bin; ./test.x
for macos it will be much faster to cache the dependencies in CI.
Sure. Caching was used with (old) travis-ci but not with (new) github-actions.
No time to look at it. Not sure if system files \usr\* could be cached: try it here #373 .