Training doesn't stop at maximum iteration
Hi, thank you for the amazing package!
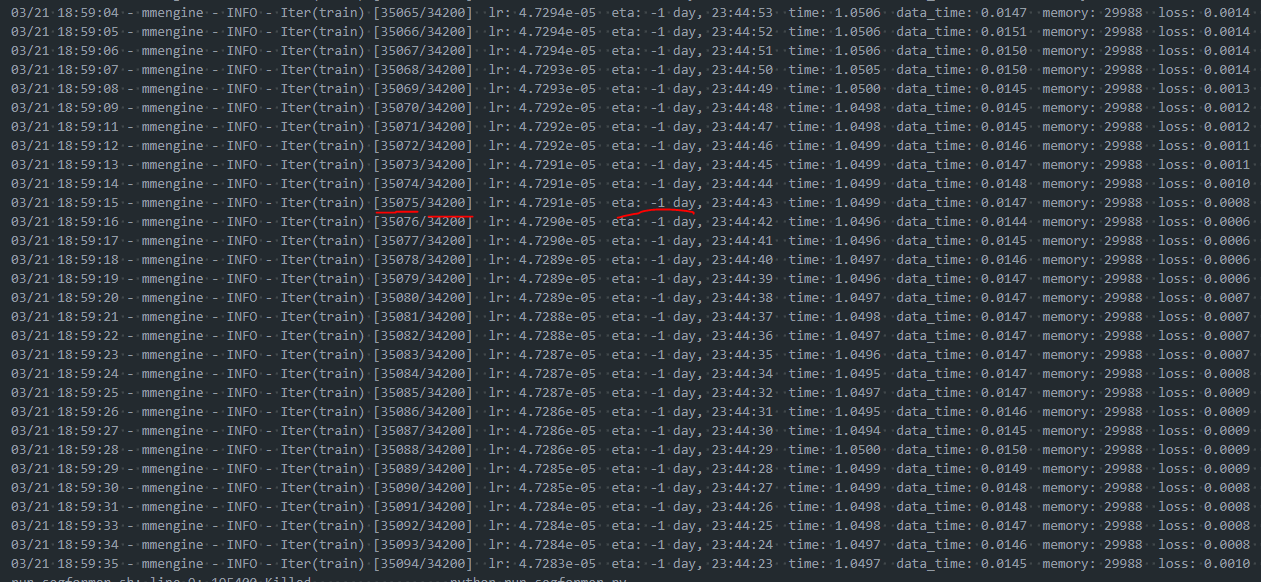
I'm new to mmsegmentation and was running Segformer using dev-1.x on my own dataset. When the training had reached its maximum iteration limit, it did not stop:
I wanted to train my model and save checkpoints with best metrics by epoch, so I followed this docs here and modified the default_hooks in my config to the following:
default_hooks = dict(
timer = dict(
type='IterTimerHook'
),
logger = dict(
type='LoggerHook',
interval=1,
log_metric_by_epoch=True,
out_dir = './logs'
),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(
type='CheckpointHook',
by_epoch=True,
interval=30,
save_best=['acc', 'mIoU'],
rule = 'greater',
out_dir = './checkpoints'
),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='SegVisualizationHook', draw = True)
)
Also the train_cfg, as described here
train_cfg = dict(
by_epoch = True,
max_epochs = 300,
val_interval = 1
)
The modification above for train_cfg produced runtime error:

 I noticed that the default
I noticed that the default type='IterBasedTrainLoop' and max_iter=160000 will still be automatically added regardless of whatever I defined for train_cfg above, so I manually cfg.train_cfg.pop these two keys type and max_iter to make epoch-based runner work before passing the config to the runner. I suspect this hacky workaround is the source of this non-stopping training issue.
Besides the problem with training not stopping, none of the checkpoints were being saved during training even though the checkpoint hook had been defined. I wonder if this had to do with the way I changed the default hook. I'm still pinpointing the source of this issue, and willing to provide further information if needed.
Environment
sys.platform: linux
Python: 3.8.16 | packaged by conda-forge | (default, Feb 1 2023, 16:01:55) [GCC 11.3.0]
CUDA available: True
numpy_random_seed: 2147483648
GPU 0: NVIDIA RTX A6000
CUDA_HOME: /usr/local/cuda
NVCC: Cuda compilation tools, release 11.6, V11.6.124
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
PyTorch: 2.0.0
PyTorch compiling details: PyTorch built with:
- GCC 9.3
- C++ Version: 201703
- Intel(R) oneAPI Math Kernel Library Version 2022.1-Product Build 20220311 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.7.3 (Git Hash 6dbeffbae1f23cbbeae17adb7b5b13f1f37c080e)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.7
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37
- CuDNN 8.5
- Magma 2.6.1
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.7, CUDNN_VERSION=8.5.0, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -D_GLIBCXX_USE_CXX11_ABI=0 -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=bool-operation -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_DISABLE_GPU_ASSERTS=ON, TORCH_VERSION=2.0.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
TorchVision: 0.15.0
OpenCV: 4.7.0
MMEngine: 0.7.0
MMSegmentation: 1.0.0rc6+ff95416
Thank you in advance!
Update:
I ran a few experiments to reproduce this issue. IterBasedTrainLoop works fine, but when by_epoch = True, and max_iter and type were removed from train_cfg to enable EpochBasedTrainLoop, the training loop just kept going after passing the maximum iteration; validation was never performed, nor could checkpoints be saved during training even though both val_interval in train_cfg and interval in CheckpointHook were set to 1:

look at your config.
i think you need change
train_dataloader = dict(
....
sampler=dict(type='InfiniteSampler', shuffle=True),
...
)
to
train_dataloader = dict(
....
sampler=dict(type='DefaultSampler', shuffle=True),
...
)
sampler=dict(type='DefaultSampler', shuffle=True),
Wow it works. Thank you @MiXaiLL76 ! We might want to have this in the docs?
Hello, have you solved this problem? I just learned this. I want to ask if there is a difference between using Epoch and Iter, or is it just to get used to my own training method?
look at your config.
i think you need change
train_dataloader = dict( .... sampler=dict(type='InfiniteSampler', shuffle=True), ... )to
train_dataloader = dict( .... sampler=dict(type='DefaultSampler', shuffle=True), ... )
Thank you! It works now.
look at your config.
i think you need change
train_dataloader = dict( .... sampler=dict(type='InfiniteSampler', shuffle=True), ... )to
train_dataloader = dict( .... sampler=dict(type='DefaultSampler', shuffle=True), ... )
thank you! It is very helpful!!
@ff98li I think it's time to close this issue
Agree. Thanks for reminding me!