Display acc and val_acc on the Plot Curves
Describe the feature
How can I plot the val_acc on the graph by the tools/analysis_tools/analyze_logs.py
Motivation
Hi, I am studying in this mmclassification, when I want to plot the curves and compare between acc and val_acc, I can not find some thing like val_acc to display.
Related resources
The tutorial just show the result of acc top 1, and top 5, currently I have not find out how to show the val_acc https://mmclassification.readthedocs.io/en/latest/tools/analysis.html
Additional context
As usual, by using Tensorflow or some libraries, we can show the graph to compare the result as the picture below:

I'd recommend using the logs, read them, parse them and print the result. It shouldn't take you too long!
I'd recommend using the logs, read them, parse them and print the result. It shouldn't take you too long!
Hi, I have trained and checked the logs, how can I print them while there is no val_acc
This is the file log.json of mine:
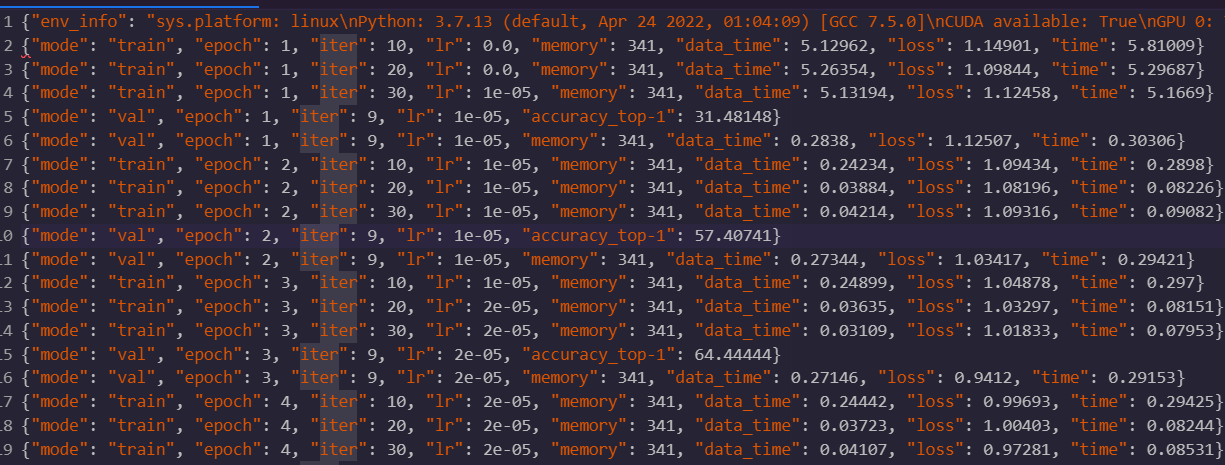 Then if I try to plot the acc, there will be like this img below:
Then if I try to plot the acc, there will be like this img below:
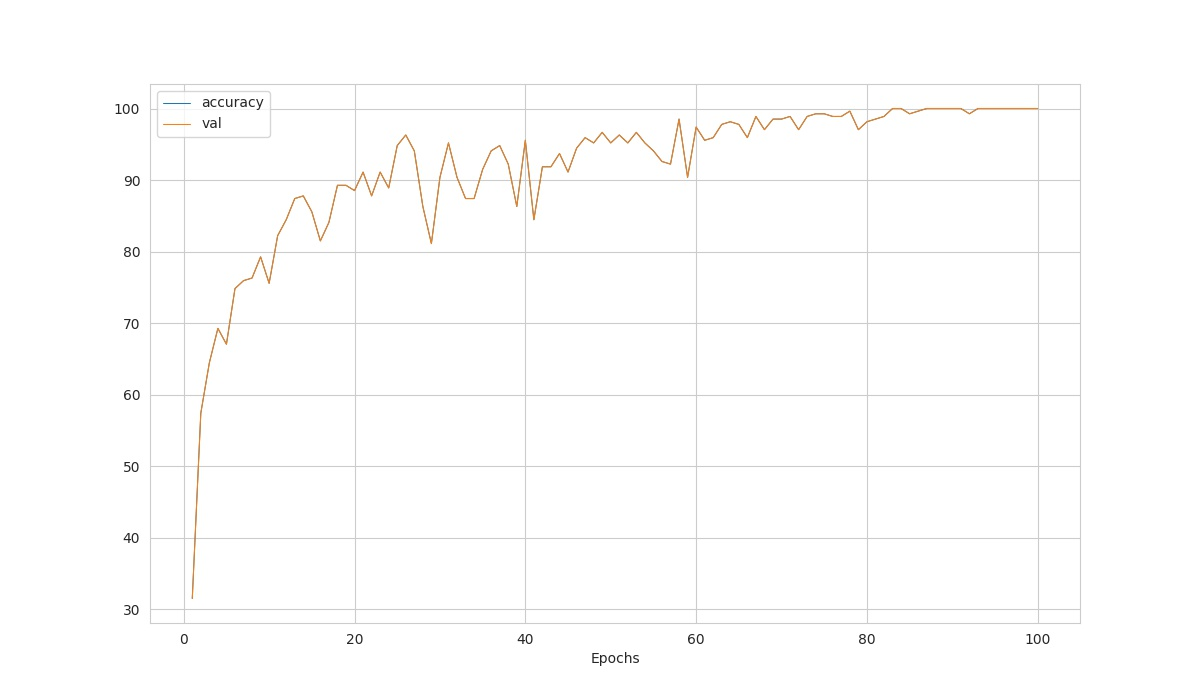

This is the val_acc.
Oh so the value that I plot on the graph is the val_acc. Then, I also the same question about the training accuracy, cause in the beginning I thought the plot I have is about the train_acc and train_loss.
Then, I also had the same question about the training accuracy, cause in the beginning I thought the plot I have is about the train_acc and train_loss.
try to modify the workflow
from workflow = [('train', 1)] to workflow = [('train', 1), ('val', 1)]. refer to the related documentation.
Then, I also had the same question about the training accuracy, cause in the beginning I thought the plot I have is about the train_acc and train_loss.
try to modify the workflow from
workflow = [('train', 1)]toworkflow = [('train', 1), ('val', 1)]. refer to the related documentation.
About that, my config file already has workflow = [('train', 1), ('val', 1)], and the result of the json file is in the img I attached in this issue before.
Maybe you can try to use a smaller batch_size and a smaller log_config.interval Or to use mmcls.1.x
Hi, I used a smaller batch_size, and even smaller log_config.interval but there is no change in anything.
can you show me your config and log?
This is the config and log
`%%writefile configs/resnet/resnet18_8xb16_cifar10_alzheimer_axial_2_views_heatmap_combined_sm_interval.py
_base_ = [
'../_base_/models/resnet18.py',
'../_base_/schedules/imagenet_bs1024_adamw_conformer.py',
'../_base_/default_runtime.py'
]
model = dict(
backbone=dict(
init_cfg = dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth',
prefix='backbone')
),
head=dict(
num_classes=2,
topk = (1,5 )
))
dataset_type = 'CustomDataset'
img_norm_cfg = dict(
mean=[124.508, 116.050, 106.438],
std=[58.577, 57.310, 57.437],
to_rgb=False)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=100, backend='pillow'),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(100, -1), backend='pillow'),
dict(type='CenterCrop', crop_size=100),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data = dict(
samples_per_gpu=16,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_prefix='/home/cvit-lab/YZU/mmclassification/data/heatmap/train/AXIAL',
classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',
pipeline=train_pipeline
),
val=dict(
type=dataset_type,
data_prefix='/home/cvit-lab/YZU/mmclassification/data/heatmap/validation/AXIAL',
classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',
pipeline=test_pipeline
),
test=dict(
type=dataset_type,
data_prefix='/home/cvit-lab/YZU/mmclassification/data/heatmap/test/AXIAL',
classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',
pipeline=test_pipeline
))
evaluation = dict(metric='accuracy', metric_options={'topk': (1,)})
paramwise_cfg = dict(
norm_decay_mult=0.0,
bias_decay_mult=0.0,
custom_keys={
'.cls_token': dict(decay_mult=0.0),
})
optimizer = dict(type='AdamW', lr=5e-4 * 128 * 8 / 512, weight_decay=0.05, eps=1e-8, betas=(0.9, 0.999),
paramwise_cfg=paramwise_cfg)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='CosineAnnealing',
by_epoch=False,
min_lr_ratio=1e-2,
warmup='linear',
warmup_ratio=1e-3,
warmup_iters=5 * 1252,
warmup_by_epoch=False)
runner = dict(type='EpochBasedRunner', max_epochs=100)
workflow = [('train', 1), ('val', 1)]
log_config = dict(interval=10)`
{"env_info": "sys.platform: linux\nPython: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0]\nCUDA available: True\nGPU 0: NVIDIA GeForce RTX 3080\nCUDA_HOME: /usr\nNVCC: Cuda compilation tools, release 10.1, V10.1.24\nGCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0\nPyTorch: 1.12.1\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) oneAPI Math Kernel Library Version 2021.4-Product Build 20210904 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.6.0 (Git Hash 52b5f107dd9cf10910aaa19cb47f3abf9b349815)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - LAPACK is enabled (usually provided by MKL)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37\n - CuDNN 8.3.2 (built against CUDA 11.5)\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.3.2, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.12.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF, \n\nTorchVision: 0.13.1\nOpenCV: 4.6.0\nMMCV: 1.6.1\nMMCV Compiler: n/a\nMMCV CUDA Compiler: n/a\nMMClassification: 0.23.2+75ae845", "seed": 0, "mmcls_version": "0.23.2", "config": "model = dict(\n type='ImageClassifier',\n backbone=dict(\n type='ResNet',\n depth=18,\n num_stages=4,\n out_indices=(3, ),\n style='pytorch',\n init_cfg=dict(\n type='Pretrained',\n checkpoint=\n 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth',\n prefix='backbone')),\n neck=dict(type='GlobalAveragePooling'),\n head=dict(\n type='LinearClsHead',\n num_classes=2,\n in_channels=512,\n loss=dict(type='CrossEntropyLoss', loss_weight=1.0),\n topk=(1, 5)))\nparamwise_cfg = dict(\n norm_decay_mult=0.0,\n bias_decay_mult=0.0,\n custom_keys=dict({'.cls_token': dict(decay_mult=0.0)}))\noptimizer = dict(\n type='AdamW',\n lr=0.001,\n weight_decay=0.05,\n eps=1e-08,\n betas=(0.9, 0.999),\n paramwise_cfg=dict(\n norm_decay_mult=0.0,\n bias_decay_mult=0.0,\n custom_keys=dict({'.cls_token': dict(decay_mult=0.0)})))\noptimizer_config = dict(grad_clip=None)\nlr_config = dict(\n policy='CosineAnnealing',\n by_epoch=False,\n min_lr_ratio=0.01,\n warmup='linear',\n warmup_ratio=0.001,\n warmup_iters=6260,\n warmup_by_epoch=False)\nrunner = dict(type='EpochBasedRunner', max_epochs=100)\ncheckpoint_config = dict(interval=1)\nlog_config = dict(interval=10, hooks=[dict(type='TextLoggerHook')])\ndist_params = dict(backend='nccl')\nlog_level = 'INFO'\nload_from = None\nresume_from = None\nworkflow = [('train', 1), ('val', 1)]\ndataset_type = 'CustomDataset'\nimg_norm_cfg = dict(\n mean=[124.508, 116.05, 106.438], std=[58.577, 57.31, 57.437], to_rgb=False)\ntrain_pipeline = [\n dict(type='LoadImageFromFile'),\n dict(type='RandomResizedCrop', size=100, backend='pillow'),\n dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),\n dict(\n type='Normalize',\n mean=[124.508, 116.05, 106.438],\n std=[58.577, 57.31, 57.437],\n to_rgb=False),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='ToTensor', keys=['gt_label']),\n dict(type='Collect', keys=['img', 'gt_label'])\n]\ntest_pipeline = [\n dict(type='LoadImageFromFile'),\n dict(type='Resize', size=(100, -1), backend='pillow'),\n dict(type='CenterCrop', crop_size=100),\n dict(\n type='Normalize',\n mean=[124.508, 116.05, 106.438],\n std=[58.577, 57.31, 57.437],\n to_rgb=False),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n]\ndata = dict(\n samples_per_gpu=16,\n workers_per_gpu=2,\n train=dict(\n type='CustomDataset',\n data_prefix=\n '/home/cvit-lab/YZU/mmclassification/data/heatmap/train/AXIAL',\n classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(type='RandomResizedCrop', size=100, backend='pillow'),\n dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),\n dict(\n type='Normalize',\n mean=[124.508, 116.05, 106.438],\n std=[58.577, 57.31, 57.437],\n to_rgb=False),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='ToTensor', keys=['gt_label']),\n dict(type='Collect', keys=['img', 'gt_label'])\n ]),\n val=dict(\n type='CustomDataset',\n data_prefix=\n '/home/cvit-lab/YZU/mmclassification/data/heatmap/validation/AXIAL',\n classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(type='Resize', size=(100, -1), backend='pillow'),\n dict(type='CenterCrop', crop_size=100),\n dict(\n type='Normalize',\n mean=[124.508, 116.05, 106.438],\n std=[58.577, 57.31, 57.437],\n to_rgb=False),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n ]),\n test=dict(\n type='CustomDataset',\n data_prefix=\n '/home/cvit-lab/YZU/mmclassification/data/heatmap/test/AXIAL',\n classes='/home/cvit-lab/YZU/mmclassification/data/heatmap/classes.txt',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(type='Resize', size=(100, -1), backend='pillow'),\n dict(type='CenterCrop', crop_size=100),\n dict(\n type='Normalize',\n mean=[124.508, 116.05, 106.438],\n std=[58.577, 57.31, 57.437],\n to_rgb=False),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n ]))\nevaluation = dict(metric='accuracy', metric_options=dict(topk=(1, )))\nwork_dir = '/home/cvit-lab/YZU/mmclassification/workdir/alzheimer/axial1'\ngpu_ids = [0]\ndevice = 'cuda'\nseed = 0\n", "CLASSES": ["MCI", "NOTMCI"]}
{"mode": "train", "epoch": 1, "iter": 10, "lr": 0.0, "memory": 269, "data_time": 0.20989, "loss": 0.66775, "time": 0.37362}
{"mode": "train", "epoch": 1, "iter": 20, "lr": 0.0, "memory": 269, "data_time": 0.00041, "loss": 0.64943, "time": 0.01048}
{"mode": "train", "epoch": 1, "iter": 30, "lr": 1e-05, "memory": 269, "data_time": 0.00029, "loss": 0.6538, "time": 0.01119}
{"mode": "train", "epoch": 1, "iter": 40, "lr": 1e-05, "memory": 269, "data_time": 0.00023, "loss": 0.68244, "time": 0.01042}
{"mode": "train", "epoch": 1, "iter": 50, "lr": 1e-05, "memory": 269, "data_time": 0.00029, "loss": 0.66845, "time": 0.01022}
{"mode": "train", "epoch": 1, "iter": 60, "lr": 1e-05, "memory": 269, "data_time": 0.00025, "loss": 0.64706, "time": 0.01041}
{"mode": "train", "epoch": 1, "iter": 70, "lr": 1e-05, "memory": 269, "data_time": 0.00024, "loss": 0.66816, "time": 0.01034}
{"mode": "train", "epoch": 1, "iter": 80, "lr": 1e-05, "memory": 269, "data_time": 0.00024, "loss": 0.62649, "time": 0.01047}
{"mode": "train", "epoch": 1, "iter": 90, "lr": 2e-05, "memory": 269, "data_time": 0.00025, "loss": 0.61487, "time": 0.01056}
{"mode": "train", "epoch": 1, "iter": 100, "lr": 2e-05, "memory": 269, "data_time": 0.00023, "loss": 0.61022, "time": 0.01031}
{"mode": "train", "epoch": 1, "iter": 110, "lr": 2e-05, "memory": 269, "data_time": 0.00022, "loss": 0.65076, "time": 0.0099}
{"mode": "train", "epoch": 1, "iter": 120, "lr": 2e-05, "memory": 269, "data_time": 0.00025, "loss": 0.5925, "time": 0.00998}
{"mode": "train", "epoch": 1, "iter": 130, "lr": 2e-05, "memory": 269, "data_time": 0.00022, "loss": 0.61937, "time": 0.00987}
{"mode": "train", "epoch": 1, "iter": 140, "lr": 2e-05, "memory": 269, "data_time": 0.00023, "loss": 0.61127, "time": 0.00994}
{"mode": "train", "epoch": 1, "iter": 150, "lr": 2e-05, "memory": 269, "data_time": 0.00029, "loss": 0.64625, "time": 0.01004}
{"mode": "val", "epoch": 1, "iter": 19, "lr": 2e-05, "accuracy_top-1": 71.66667}
{"mode": "val", "epoch": 1, "iter": 19, "lr": 2e-05, "memory": 269, "data_time": 0.11062, "loss": 0.57846, "time": 0.1139}
{"mode": "train", "epoch": 2, "iter": 10, "lr": 3e-05, "memory": 269, "data_time": 0.20248, "loss": 0.59998, "time": 0.21213}
{"mode": "train", "epoch": 2, "iter": 20, "lr": 3e-05, "memory": 269, "data_time": 0.00039, "loss": 0.60258, "time": 0.01017}
{"mode": "train", "epoch": 2, "iter": 30, "lr": 3e-05, "memory": 269, "data_time": 0.00028, "loss": 0.58857, "time": 0.0099}
{"mode": "train", "epoch": 2, "iter": 40, "lr": 3e-05, "memory": 269, "data_time": 0.00024, "loss": 0.57434, "time": 0.00984}
{"mode": "train", "epoch": 2, "iter": 50, "lr": 3e-05, "memory": 269, "data_time": 0.00023, "loss": 0.55334, "time": 0.00982}
{"mode": "train", "epoch": 2, "iter": 60, "lr": 3e-05, "memory": 269, "data_time": 0.00025, "loss": 0.57984, "time": 0.00984}
{"mode": "train", "epoch": 2, "iter": 70, "lr": 4e-05, "memory": 269, "data_time": 0.00024, "loss": 0.63231, "time": 0.00996}
{"mode": "train", "epoch": 2, "iter": 80, "lr": 4e-05, "memory": 269, "data_time": 0.00023, "loss": 0.60036, "time": 0.01007}
{"mode": "train", "epoch": 2, "iter": 90, "lr": 4e-05, "memory": 269, "data_time": 0.00024, "loss": 0.58123, "time": 0.0097}
{"mode": "train", "epoch": 2, "iter": 100, "lr": 4e-05, "memory": 269, "data_time": 0.00024, "loss": 0.5726, "time": 0.00977}
{"mode": "train", "epoch": 2, "iter": 110, "lr": 4e-05, "memory": 269, "data_time": 0.00024, "loss": 0.5521, "time": 0.00993}
{"mode": "train", "epoch": 2, "iter": 120, "lr": 4e-05, "memory": 269, "data_time": 0.00023, "loss": 0.57806, "time": 0.00997}
{"mode": "train", "epoch": 2, "iter": 130, "lr": 5e-05, "memory": 269, "data_time": 0.00023, "loss": 0.54007, "time": 0.01}
{"mode": "train", "epoch": 2, "iter": 140, "lr": 5e-05, "memory": 269, "data_time": 0.00023, "loss": 0.57041, "time": 0.00996}
{"mode": "train", "epoch": 2, "iter": 150, "lr": 5e-05, "memory": 269, "data_time": 0.00025, "loss": 0.46459, "time": 0.0095}
{"mode": "val", "epoch": 2, "iter": 19, "lr": 5e-05, "accuracy_top-1": 80.66667}
{"mode": "val", "epoch": 2, "iter": 19, "lr": 5e-05, "memory": 269, "data_time": 0.10848, "loss": 0.51437, "time": 0.11177}
{"mode": "train", "epoch": 3, "iter": 10, "lr": 5e-05, "memory": 269, "data_time": 0.2023, "loss": 0.52061, "time": 0.21186}
{"mode": "train", "epoch": 3, "iter": 20, "lr": 5e-05, "memory": 269, "data_time": 0.00031, "loss": 0.56731, "time": 0.00987}
{"mode": "train", "epoch": 3, "iter": 30, "lr": 5e-05, "memory": 269, "data_time": 0.00025, "loss": 0.53655, "time": 0.00994}
{"mode": "train", "epoch": 3, "iter": 40, "lr": 6e-05, "memory": 269, "data_time": 0.00025, "loss": 0.61025, "time": 0.00977}
{"mode": "train", "epoch": 3, "iter": 50, "lr": 6e-05, "memory": 269, "data_time": 0.00026, "loss": 0.63409, "time": 0.00982}
{"mode": "train", "epoch": 3, "iter": 60, "lr": 6e-05, "memory": 269, "data_time": 0.00025, "loss": 0.55994, "time": 0.00983}
{"mode": "train", "epoch": 3, "iter": 70, "lr": 6e-05, "memory": 269, "data_time": 0.00025, "loss": 0.53472, "time": 0.00978}
{"mode": "train", "epoch": 3, "iter": 80, "lr": 6e-05, "memory": 269, "data_time": 0.00025, "loss": 0.54208, "time": 0.0097}
{"mode": "train", "epoch": 3, "iter": 90, "lr": 6e-05, "memory": 269, "data_time": 0.00026, "loss": 0.48729, "time": 0.0098}
{"mode": "train", "epoch": 3, "iter": 100, "lr": 6e-05, "memory": 269, "data_time": 0.00025, "loss": 0.54716, "time": 0.00973}
{"mode": "train", "epoch": 3, "iter": 110, "lr": 7e-05, "memory": 269, "data_time": 0.00025, "loss": 0.5549, "time": 0.00999}
{"mode": "train", "epoch": 3, "iter": 120, "lr": 7e-05, "memory": 269, "data_time": 0.00023, "loss": 0.5936, "time": 0.00987}
{"mode": "train", "epoch": 3, "iter": 130, "lr": 7e-05, "memory": 269, "data_time": 0.00024, "loss": 0.52918, "time": 0.00998}
{"mode": "train", "epoch": 3, "iter": 140, "lr": 7e-05, "memory": 269, "data_time": 0.00023, "loss": 0.51521, "time": 0.01}
{"mode": "train", "epoch": 3, "iter": 150, "lr": 7e-05, "memory": 269, "data_time": 0.00023, "loss": 0.56085, "time": 0.00952}
{"mode": "val", "epoch": 3, "iter": 19, "lr": 7e-05, "accuracy_top-1": 83.33334}
{"mode": "val", "epoch": 3, "iter": 19, "lr": 7e-05, "memory": 269, "data_time": 0.10865, "loss": 0.46208, "time": 0.11185}
{"mode": "train", "epoch": 4, "iter": 10, "lr": 7e-05, "memory": 269, "data_time": 0.20233, "loss": 0.55456, "time": 0.21198}
{"mode": "train", "epoch": 4, "iter": 20, "lr": 8e-05, "memory": 269, "data_time": 0.0003, "loss": 0.48994, "time": 0.01}
{"mode": "train", "epoch": 4, "iter": 30, "lr": 8e-05, "memory": 269, "data_time": 0.00031, "loss": 0.50443, "time": 0.00998}
{"mode": "train", "epoch": 4, "iter": 40, "lr": 8e-05, "memory": 269, "data_time": 0.00024, "loss": 0.4357, "time": 0.00994}
{"mode": "train", "epoch": 4, "iter": 50, "lr": 8e-05, "memory": 269, "data_time": 0.00024, "loss": 0.66496, "time": 0.00997}
{"mode": "train", "epoch": 4, "iter": 60, "lr": 8e-05, "memory": 269, "data_time": 0.00025, "loss": 0.55728, "time": 0.00989}
{"mode": "train", "epoch": 4, "iter": 70, "lr": 8e-05, "memory": 269, "data_time": 0.00026, "loss": 0.48454, "time": 0.00998}
{"mode": "train", "epoch": 4, "iter": 80, "lr": 9e-05, "memory": 269, "data_time": 0.00024, "loss": 0.48189, "time": 0.0099}
{"mode": "train", "epoch": 4, "iter": 90, "lr": 9e-05, "memory": 269, "data_time": 0.00027, "loss": 0.55213, "time": 0.00995}
{"mode": "train", "epoch": 4, "iter": 100, "lr": 9e-05, "memory": 269, "data_time": 0.00025, "loss": 0.54382, "time": 0.01005}
{"mode": "train", "epoch": 4, "iter": 110, "lr": 9e-05, "memory": 269, "data_time": 0.00025, "loss": 0.58201, "time": 0.0101}
{"mode": "train", "epoch": 4, "iter": 120, "lr": 9e-05, "memory": 269, "data_time": 0.00027, "loss": 0.51014, "time": 0.01005}
{"mode": "train", "epoch": 4, "iter": 130, "lr": 9e-05, "memory": 269, "data_time": 0.00025, "loss": 0.46654, "time": 0.00985}
{"mode": "train", "epoch": 4, "iter": 140, "lr": 9e-05, "memory": 269, "data_time": 0.00025, "loss": 0.45645, "time": 0.00986}
{"mode": "train", "epoch": 4, "iter": 150, "lr": 0.0001, "memory": 269, "data_time": 0.00025, "loss": 0.48746, "time": 0.00943}
{"mode": "val", "epoch": 4, "iter": 19, "lr": 0.0001, "accuracy_top-1": 79.0}
{"mode": "val", "epoch": 4, "iter": 19, "lr": 0.0001, "memory": 269, "data_time": 0.10859, "loss": 0.47704, "time": 0.1124}
{"mode": "train", "epoch": 5, "iter": 10, "lr": 0.0001, "memory": 269, "data_time": 0.20229, "loss": 0.48058, "time": 0.21185}
{"mode": "train", "epoch": 5, "iter": 20, "lr": 0.0001, "memory": 269, "data_time": 0.0003, "loss": 0.51797, "time": 0.00994}
{"mode": "train", "epoch": 5, "iter": 30, "lr": 0.0001, "memory": 269, "data_time": 0.00029, "loss": 0.56639, "time": 0.00982}
{"mode": "train", "epoch": 5, "iter": 40, "lr": 0.0001, "memory": 269, "data_time": 0.00029, "loss": 0.53094, "time": 0.00995}
{"mode": "train", "epoch": 5, "iter": 50, "lr": 0.0001, "memory": 269, "data_time": 0.00023, "loss": 0.50813, "time": 0.00985}
{"mode": "train", "epoch": 5, "iter": 60, "lr": 0.00011, "memory": 269, "data_time": 0.00025, "loss": 0.47758, "time": 0.0098}
{"mode": "train", "epoch": 5, "iter": 70, "lr": 0.00011, "memory": 269, "data_time": 0.00024, "loss": 0.54008, "time": 0.0098}
{"mode": "train", "epoch": 5, "iter": 80, "lr": 0.00011, "memory": 269, "data_time": 0.00025, "loss": 0.50292, "time": 0.00995}
{"mode": "train", "epoch": 5, "iter": 90, "lr": 0.00011, "memory": 269, "data_time": 0.00025, "loss": 0.49147, "time": 0.00974}
{"mode": "train", "epoch": 5, "iter": 100, "lr": 0.00011, "memory": 269, "data_time": 0.00026, "loss": 0.45508, "time": 0.00966}
{"mode": "train", "epoch": 5, "iter": 110, "lr": 0.00011, "memory": 269, "data_time": 0.00024, "loss": 0.4267, "time": 0.00991}
{"mode": "train", "epoch": 5, "iter": 120, "lr": 0.00012, "memory": 269, "data_time": 0.00024, "loss": 0.48972, "time": 0.00985}
{"mode": "train", "epoch": 5, "iter": 130, "lr": 0.00012, "memory": 269, "data_time": 0.00397, "loss": 0.46988, "time": 0.01455}
{"mode": "train", "epoch": 5, "iter": 140, "lr": 0.00012, "memory": 269, "data_time": 0.00025, "loss": 0.45408, "time": 0.0099}
{"mode": "train", "epoch": 5, "iter": 150, "lr": 0.00012, "memory": 269, "data_time": 0.00023, "loss": 0.47215, "time": 0.00936}
{"mode": "val", "epoch": 5, "iter": 19, "lr": 0.00012, "accuracy_top-1": 80.33334}
{"mode": "val", "epoch": 5, "iter": 19, "lr": 0.00012, "memory": 269, "data_time": 0.10848, "loss": 0.48102, "time": 0.11175}
{"mode": "train", "epoch": 6, "iter": 10, "lr": 0.00012, "memory": 269, "data_time": 0.20238, "loss": 0.49702, "time": 0.21186}
{"mode": "train", "epoch": 6, "iter": 20, "lr": 0.00012, "memory": 269, "data_time": 0.00031, "loss": 0.54368, "time": 0.01007}
{"mode": "train", "epoch": 6, "iter": 30, "lr": 0.00012, "memory": 269, "data_time": 0.00024, "loss": 0.49324, "time": 0.0099}
{"mode": "train", "epoch": 6, "iter": 40, "lr": 0.00013, "memory": 269, "data_time": 0.00396, "loss": 0.52026, "time": 0.01441}
{"mode": "train", "epoch": 6, "iter": 50, "lr": 0.00013, "memory": 269, "data_time": 0.00025, "loss": 0.46394, "time": 0.01001}
{"mode": "train", "epoch": 6, "iter": 60, "lr": 0.00013, "memory": 269, "data_time": 0.00026, "loss": 0.4744, "time": 0.00982}
{"mode": "train", "epoch": 6, "iter": 70, "lr": 0.00013, "memory": 269, "data_time": 0.00023, "loss": 0.44346, "time": 0.00974}
{"mode": "train", "epoch": 6, "iter": 80, "lr": 0.00013, "memory": 269, "data_time": 0.00023, "loss": 0.54856, "time": 0.00982}
{"mode": "train", "epoch": 6, "iter": 90, "lr": 0.00013, "memory": 269, "data_time": 0.00023, "loss": 0.50411, "time": 0.00978}
{"mode": "train", "epoch": 6, "iter": 100, "lr": 0.00014, "memory": 269, "data_time": 0.00023, "loss": 0.45225, "time": 0.00981}
{"mode": "train", "epoch": 6, "iter": 110, "lr": 0.00014, "memory": 269, "data_time": 0.00023, "loss": 0.42694, "time": 0.0099}
{"mode": "train", "epoch": 6, "iter": 120, "lr": 0.00014, "memory": 269, "data_time": 0.00022, "loss": 0.48698, "time": 0.0098}
{"mode": "train", "epoch": 6, "iter": 130, "lr": 0.00014, "memory": 269, "data_time": 0.00021, "loss": 0.40364, "time": 0.00974}
{"mode": "train", "epoch": 6, "iter": 140, "lr": 0.00014, "memory": 269, "data_time": 0.00026, "loss": 0.4851, "time": 0.0102}
{"mode": "train", "epoch": 6, "iter": 150, "lr": 0.00014, "memory": 269, "data_time": 0.00024, "loss": 0.44006, "time": 0.00971}
{"mode": "val", "epoch": 6, "iter": 19, "lr": 0.00014, "accuracy_top-1": 80.0}
{"mode": "val", "epoch": 6, "iter": 19, "lr": 0.00014, "memory": 269, "data_time": 0.10846, "loss": 0.42258, "time": 0.11166}
{"mode": "train", "epoch": 7, "iter": 10, "lr": 0.00014, "memory": 269, "data_time": 0.2024, "loss": 0.40934, "time": 0.21209}
{"mode": "train", "epoch": 7, "iter": 20, "lr": 0.00015, "memory": 269, "data_time": 0.0003, "loss": 0.47521, "time": 0.00995}
{"mode": "train", "epoch": 7, "iter": 30, "lr": 0.00015, "memory": 269, "data_time": 0.00031, "loss": 0.53333, "time": 0.00994}
{"mode": "train", "epoch": 7, "iter": 40, "lr": 0.00015, "memory": 269, "data_time": 0.00026, "loss": 0.40111, "time": 0.00988}
{"mode": "train", "epoch": 7, "iter": 50, "lr": 0.00015, "memory": 269, "data_time": 0.00024, "loss": 0.43397, "time": 0.00982}
{"mode": "train", "epoch": 7, "iter": 60, "lr": 0.00015, "memory": 269, "data_time": 0.00023, "loss": 0.40693, "time": 0.0097}
{"mode": "train", "epoch": 7, "iter": 70, "lr": 0.00015, "memory": 269, "data_time": 0.00024, "loss": 0.45831, "time": 0.00989}
{"mode": "train", "epoch": 7, "iter": 80, "lr": 0.00016, "memory": 269, "data_time": 0.00023, "loss": 0.50393, "time": 0.00985}
{"mode": "train", "epoch": 7, "iter": 90, "lr": 0.00016, "memory": 269, "data_time": 0.00024, "loss": 0.54923, "time": 0.00983}
{"mode": "train", "epoch": 7, "iter": 100, "lr": 0.00016, "memory": 269, "data_time": 0.00024, "loss": 0.51425, "time": 0.00991}
{"mode": "train", "epoch": 7, "iter": 110, "lr": 0.00016, "memory": 269, "data_time": 0.00023, "loss": 0.47269, "time": 0.00961}
{"mode": "train", "epoch": 7, "iter": 120, "lr": 0.00016, "memory": 269, "data_time": 0.00024, "loss": 0.46915, "time": 0.00963}
{"mode": "train", "epoch": 7, "iter": 130, "lr": 0.00016, "memory": 269, "data_time": 0.00025, "loss": 0.41517, "time": 0.00963}
{"mode": "train", "epoch": 7, "iter": 140, "lr": 0.00016, "memory": 269, "data_time": 0.00025, "loss": 0.50199, "time": 0.00972}
{"mode": "train", "epoch": 7, "iter": 150, "lr": 0.00017, "memory": 269, "data_time": 0.00024, "loss": 0.46166, "time": 0.00937}
{"mode": "val", "epoch": 7, "iter": 19, "lr": 0.00017, "accuracy_top-1": 78.33334}
{"mode": "val", "epoch": 7, "iter": 19, "lr": 0.00017, "memory": 269, "data_time": 0.10924, "loss": 0.68448, "time": 0.11256}
{"mode": "train", "epoch": 8, "iter": 10, "lr": 0.00017, "memory": 269, "data_time": 0.20231, "loss": 0.47004, "time": 0.21202}
{"mode": "train", "epoch": 8, "iter": 20, "lr": 0.00017, "memory": 269, "data_time": 0.00029, "loss": 0.45114, "time": 0.00981}
{"mode": "train", "epoch": 8, "iter": 30, "lr": 0.00017, "memory": 269, "data_time": 0.00024, "loss": 0.45329, "time": 0.01014}
{"mode": "train", "epoch": 8, "iter": 40, "lr": 0.00017, "memory": 269, "data_time": 0.00022, "loss": 0.393, "time": 0.01058}
{"mode": "train", "epoch": 8, "iter": 50, "lr": 0.00017, "memory": 269, "data_time": 0.00024, "loss": 0.45876, "time": 0.00987}
{"mode": "train", "epoch": 8, "iter": 60, "lr": 0.00018, "memory": 269, "data_time": 0.00023, "loss": 0.48697, "time": 0.01005}
{"mode": "train", "epoch": 8, "iter": 70, "lr": 0.00018, "memory": 269, "data_time": 0.00023, "loss": 0.45758, "time": 0.01003}
{"mode": "train", "epoch": 8, "iter": 80, "lr": 0.00018, "memory": 269, "data_time": 0.00024, "loss": 0.4914, "time": 0.01005}
{"mode": "train", "epoch": 8, "iter": 90, "lr": 0.00018, "memory": 269, "data_time": 0.00024, "loss": 0.44372, "time": 0.00997}
{"mode": "train", "epoch": 8, "iter": 100, "lr": 0.00018, "memory": 269, "data_time": 0.00025, "loss": 0.38794, "time": 0.00977}
{"mode": "train", "epoch": 8, "iter": 110, "lr": 0.00018, "memory": 269, "data_time": 0.00026, "loss": 0.48821, "time": 0.01032}
{"mode": "train", "epoch": 8, "iter": 120, "lr": 0.00018, "memory": 269, "data_time": 0.00024, "loss": 0.40301, "time": 0.01031}
{"mode": "train", "epoch": 8, "iter": 130, "lr": 0.00019, "memory": 269, "data_time": 0.00023, "loss": 0.49166, "time": 0.00984}
{"mode": "train", "epoch": 8, "iter": 140, "lr": 0.00019, "memory": 269, "data_time": 0.00025, "loss": 0.41572, "time": 0.00969}
{"mode": "train", "epoch": 8, "iter": 150, "lr": 0.00019, "memory": 269, "data_time": 0.00025, "loss": 0.41425, "time": 0.00967}
{"mode": "val", "epoch": 8, "iter": 19, "lr": 0.00019, "accuracy_top-1": 86.0}
{"mode": "val", "epoch": 8, "iter": 19, "lr": 0.00019, "memory": 269, "data_time": 0.10847, "loss": 0.37886, "time": 0.11175}
{"mode": "train", "epoch": 9, "iter": 10, "lr": 0.00019, "memory": 269, "data_time": 0.20354, "loss": 0.38407, "time": 0.21318}
{"mode": "train", "epoch": 9, "iter": 20, "lr": 0.00019, "memory": 269, "data_time": 0.0003, "loss": 0.38658, "time": 0.01001}
{"mode": "train", "epoch": 9, "iter": 30, "lr": 0.00019, "memory": 269, "data_time": 0.00205, "loss": 0.36903, "time": 0.01261}
{"mode": "train", "epoch": 9, "iter": 40, "lr": 0.0002, "memory": 269, "data_time": 0.00025, "loss": 0.4469, "time": 0.01001}
{"mode": "train", "epoch": 9, "iter": 50, "lr": 0.0002, "memory": 269, "data_time": 0.00025, "loss": 0.41719, "time": 0.00997}
{"mode": "train", "epoch": 9, "iter": 60, "lr": 0.0002, "memory": 269, "data_time": 0.00024, "loss": 0.39397, "time": 0.00991}
{"mode": "train", "epoch": 9, "iter": 70, "lr": 0.0002, "memory": 269, "data_time": 0.00029, "loss": 0.38064, "time": 0.01224}
{"mode": "train", "epoch": 9, "iter": 80, "lr": 0.0002, "memory": 269, "data_time": 0.00022, "loss": 0.4159, "time": 0.01112}
{"mode": "train", "epoch": 9, "iter": 90, "lr": 0.0002, "memory": 269, "data_time": 0.00022, "loss": 0.41951, "time": 0.01006}
{"mode": "train", "epoch": 9, "iter": 100, "lr": 0.0002, "memory": 269, "data_time": 0.00025, "loss": 0.41923, "time": 0.00999}
{"mode": "train", "epoch": 9, "iter": 110, "lr": 0.00021, "memory": 269, "data_time": 0.00025, "loss": 0.49649, "time": 0.01008}
{"mode": "train", "epoch": 9, "iter": 120, "lr": 0.00021, "memory": 269, "data_time": 0.00023, "loss": 0.41127, "time": 0.00996}
{"mode": "train", "epoch": 9, "iter": 130, "lr": 0.00021, "memory": 269, "data_time": 0.00024, "loss": 0.43103, "time": 0.00973}
{"mode": "train", "epoch": 9, "iter": 140, "lr": 0.00021, "memory": 269, "data_time": 0.00025, "loss": 0.45655, "time": 0.00988}
{"mode": "train", "epoch": 9, "iter": 150, "lr": 0.00021, "memory": 269, "data_time": 0.00022, "loss": 0.41208, "time": 0.00974}
{"mode": "val", "epoch": 9, "iter": 19, "lr": 0.00021, "accuracy_top-1": 79.66667}
{"mode": "val", "epoch": 9, "iter": 19, "lr": 0.00021, "memory": 269, "data_time": 0.10853, "loss": 0.47347, "time": 0.11177}
{"mode": "train", "epoch": 10, "iter": 10, "lr": 0.00021, "memory": 269, "data_time": 0.20371, "loss": 0.49591, "time": 0.21335}
{"mode": "train", "epoch": 10, "iter": 20, "lr": 0.00022, "memory": 269, "data_time": 0.00031, "loss": 0.42972, "time": 0.00982}
{"mode": "train", "epoch": 10, "iter": 30, "lr": 0.00022, "memory": 269, "data_time": 0.00031, "loss": 0.44658, "time": 0.00988}
{"mode": "train", "epoch": 10, "iter": 40, "lr": 0.00022, "memory": 269, "data_time": 0.00024, "loss": 0.41356, "time": 0.00975}
{"mode": "train", "epoch": 10, "iter": 50, "lr": 0.00022, "memory": 269, "data_time": 0.00023, "loss": 0.46053, "time": 0.00992}
{"mode": "train", "epoch": 10, "iter": 60, "lr": 0.00022, "memory": 269, "data_time": 0.00023, "loss": 0.46244, "time": 0.00997}
{"mode": "train", "epoch": 10, "iter": 70, "lr": 0.00022, "memory": 269, "data_time": 0.00024, "loss": 0.44887, "time": 0.00978}
{"mode": "train", "epoch": 10, "iter": 80, "lr": 0.00022, "memory": 269, "data_time": 0.00023, "loss": 0.49606, "time": 0.00977}
{"mode": "train", "epoch": 10, "iter": 90, "lr": 0.00023, "memory": 269, "data_time": 0.00023, "loss": 0.32468, "time": 0.00973}
{"mode": "train", "epoch": 10, "iter": 100, "lr": 0.00023, "memory": 269, "data_time": 0.00022, "loss": 0.4594, "time": 0.00976}
{"mode": "train", "epoch": 10, "iter": 110, "lr": 0.00023, "memory": 269, "data_time": 0.00023, "loss": 0.4291, "time": 0.0098}
{"mode": "train", "epoch": 10, "iter": 120, "lr": 0.00023, "memory": 269, "data_time": 0.00023, "loss": 0.35481, "time": 0.00988}
{"mode": "train", "epoch": 10, "iter": 130, "lr": 0.00023, "memory": 269, "data_time": 0.00024, "loss": 0.43898, "time": 0.00979}
{"mode": "train", "epoch": 10, "iter": 140, "lr": 0.00023, "memory": 269, "data_time": 0.00024, "loss": 0.50581, "time": 0.00976}
{"mode": "train", "epoch": 10, "iter": 150, "lr": 0.00023, "memory": 269, "data_time": 0.00024, "loss": 0.42503, "time": 0.00959}
{"mode": "val", "epoch": 10, "iter": 19, "lr": 0.00023, "accuracy_top-1": 79.0}
{"mode": "val", "epoch": 10, "iter": 19, "lr": 0.00023, "memory": 269, "data_time": 0.10918, "loss": 0.56375, "time": 0.1135}
{"mode": "train", "epoch": 11, "iter": 10, "lr": 0.00024, "memory": 269, "data_time": 0.2021, "loss": 0.42074, "time": 0.21208}
{"mode": "train", "epoch": 11, "iter": 20, "lr": 0.00024, "memory": 269, "data_time": 0.0003, "loss": 0.44389, "time": 0.00993}
{"mode": "train", "epoch": 11, "iter": 30, "lr": 0.00024, "memory": 269, "data_time": 0.00028, "loss": 0.41597, "time": 0.01003}
{"mode": "train", "epoch": 11, "iter": 40, "lr": 0.00024, "memory": 269, "data_time": 0.00027, "loss": 0.44863, "time": 0.00986}
{"mode": "train", "epoch": 11, "iter": 50, "lr": 0.00024, "memory": 269, "data_time": 0.00024, "loss": 0.35009, "time": 0.00969}
{"mode": "train", "epoch": 11, "iter": 60, "lr": 0.00024, "memory": 269, "data_time": 0.00024, "loss": 0.41758, "time": 0.00986}
{"mode": "train", "epoch": 11, "iter": 70, "lr": 0.00024, "memory": 269, "data_time": 0.00026, "loss": 0.44057, "time": 0.01009}
{"mode": "train", "epoch": 11, "iter": 80, "lr": 0.00025, "memory": 269, "data_time": 0.00022, "loss": 0.43843, "time": 0.00981}
{"mode": "train", "epoch": 11, "iter": 90, "lr": 0.00025, "memory": 269, "data_time": 0.00023, "loss": 0.40841, "time": 0.00986}
{"mode": "train", "epoch": 11, "iter": 100, "lr": 0.00025, "memory": 269, "data_time": 0.00023, "loss": 0.40503, "time": 0.00996}
{"mode": "train", "epoch": 11, "iter": 110, "lr": 0.00025, "memory": 269, "data_time": 0.00024, "loss": 0.40042, "time": 0.00982}
{"mode": "train", "epoch": 11, "iter": 120, "lr": 0.00025, "memory": 269, "data_time": 0.00026, "loss": 0.51252, "time": 0.01067}
{"mode": "train", "epoch": 11, "iter": 130, "lr": 0.00025, "memory": 269, "data_time": 0.00023, "loss": 0.46818, "time": 0.01081}
{"mode": "train", "epoch": 11, "iter": 140, "lr": 0.00025, "memory": 269, "data_time": 0.00022, "loss": 0.45374, "time": 0.01081}
{"mode": "train", "epoch": 11, "iter": 150, "lr": 0.00026, "memory": 269, "data_time": 0.00021, "loss": 0.3541, "time": 0.00997}
{"mode": "val", "epoch": 11, "iter": 19, "lr": 0.00026, "accuracy_top-1": 86.66667}
{"mode": "val", "epoch": 11, "iter": 19, "lr": 0.00026, "memory": 269, "data_time": 0.10843, "loss": 0.39532, "time": 0.11169}
{"mode": "train", "epoch": 12, "iter": 10, "lr": 0.00026, "memory": 269, "data_time": 0.20372, "loss": 0.37637, "time": 0.2143}
{"mode": "train", "epoch": 12, "iter": 20, "lr": 0.00026, "memory": 269, "data_time": 0.00032, "loss": 0.32739, "time": 0.01034}
{"mode": "train", "epoch": 12, "iter": 30, "lr": 0.00026, "memory": 269, "data_time": 0.00024, "loss": 0.37048, "time": 0.01005}
{"mode": "train", "epoch": 12, "iter": 40, "lr": 0.00026, "memory": 269, "data_time": 0.00024, "loss": 0.40357, "time": 0.00999}
{"mode": "train", "epoch": 12, "iter": 50, "lr": 0.00026, "memory": 269, "data_time": 0.00026, "loss": 0.4192, "time": 0.01017}
{"mode": "train", "epoch": 12, "iter": 60, "lr": 0.00027, "memory": 269, "data_time": 0.00027, "loss": 0.5503, "time": 0.01027}
{"mode": "train", "epoch": 12, "iter": 70, "lr": 0.00027, "memory": 269, "data_time": 0.00024, "loss": 0.37345, "time": 0.01071}
{"mode": "train", "epoch": 12, "iter": 80, "lr": 0.00027, "memory": 269, "data_time": 0.00024, "loss": 0.45594, "time": 0.01113}
{"mode": "train", "epoch": 12, "iter": 90, "lr": 0.00027, "memory": 269, "data_time": 0.00023, "loss": 0.39641, "time": 0.01105}
{"mode": "train", "epoch": 12, "iter": 100, "lr": 0.00027, "memory": 269, "data_time": 0.00024, "loss": 0.42243, "time": 0.0111}
{"mode": "train", "epoch": 12, "iter": 110, "lr": 0.00027, "memory": 269, "data_time": 0.00025, "loss": 0.3613, "time": 0.01119}
{"mode": "train", "epoch": 12, "iter": 120, "lr": 0.00027, "memory": 269, "data_time": 0.00023, "loss": 0.33859, "time": 0.01114}
{"mode": "train", "epoch": 12, "iter": 130, "lr": 0.00028, "memory": 269, "data_time": 0.00022, "loss": 0.31759, "time": 0.01125}
{"mode": "train", "epoch": 12, "iter": 140, "lr": 0.00028, "memory": 269, "data_time": 0.00021, "loss": 0.37501, "time": 0.01059}
{"mode": "train", "epoch": 12, "iter": 150, "lr": 0.00028, "memory": 269, "data_time": 0.00023, "loss": 0.41743, "time": 0.0096}
{"mode": "val", "epoch": 12, "iter": 19, "lr": 0.00028, "accuracy_top-1": 82.0}
{"mode": "val", "epoch": 12, "iter": 19, "lr": 0.00028, "memory": 269, "data_time": 0.1084, "loss": 0.50928, "time": 0.11177}
{"mode": "train", "epoch": 13, "iter": 10, "lr": 0.00028, "memory": 269, "data_time": 0.20245, "loss": 0.43228, "time": 0.21193}
{"mode": "train", "epoch": 13, "iter": 20, "lr": 0.00028, "memory": 269, "data_time": 0.00032, "loss": 0.41774, "time": 0.00995}
{"mode": "train", "epoch": 13, "iter": 30, "lr": 0.00028, "memory": 269, "data_time": 0.00023, "loss": 0.37206, "time": 0.00982}
{"mode": "train", "epoch": 13, "iter": 40, "lr": 0.00028, "memory": 269, "data_time": 0.00023, "loss": 0.42238, "time": 0.0098}
{"mode": "train", "epoch": 13, "iter": 50, "lr": 0.00029, "memory": 269, "data_time": 0.00026, "loss": 0.37388, "time": 0.01}
{"mode": "train", "epoch": 13, "iter": 60, "lr": 0.00029, "memory": 269, "data_time": 0.00024, "loss": 0.35596, "time": 0.00981}
{"mode": "train", "epoch": 13, "iter": 70, "lr": 0.00029, "memory": 269, "data_time": 0.00024, "loss": 0.41203, "time": 0.00984}
{"mode": "train", "epoch": 13, "iter": 80, "lr": 0.00029, "memory": 269, "data_time": 0.00023, "loss": 0.36709, "time": 0.00974}
{"mode": "train", "epoch": 13, "iter": 90, "lr": 0.00029, "memory": 269, "data_time": 0.00025, "loss": 0.34978, "time": 0.00976}
{"mode": "train", "epoch": 13, "iter": 100, "lr": 0.00029, "memory": 269, "data_time": 0.00027, "loss": 0.39159, "time": 0.0096}
{"mode": "train", "epoch": 13, "iter": 110, "lr": 0.00029, "memory": 269, "data_time": 0.00025, "loss": 0.46816, "time": 0.00985}
{"mode": "train", "epoch": 13, "iter": 120, "lr": 0.0003, "memory": 269, "data_time": 0.00025, "loss": 0.46192, "time": 0.00999}
{"mode": "train", "epoch": 13, "iter": 130, "lr": 0.0003, "memory": 269, "data_time": 0.00023, "loss": 0.40991, "time": 0.00991}
{"mode": "train", "epoch": 13, "iter": 140, "lr": 0.0003, "memory": 269, "data_time": 0.00023, "loss": 0.38321, "time": 0.00984}
{"mode": "train", "epoch": 13, "iter": 150, "lr": 0.0003, "memory": 269, "data_time": 0.00022, "loss": 0.38851, "time": 0.00942}
{"mode": "val", "epoch": 13, "iter": 19, "lr": 0.0003, "accuracy_top-1": 88.0}
{"mode": "val", "epoch": 13, "iter": 19, "lr": 0.0003, "memory": 269, "data_time": 0.10848, "loss": 0.46065, "time": 0.11178}
{"mode": "train", "epoch": 14, "iter": 10, "lr": 0.0003, "memory": 269, "data_time": 0.2038, "loss": 0.38567, "time": 0.2135}
{"mode": "train", "epoch": 14, "iter": 20, "lr": 0.0003, "memory": 269, "data_time": 0.00027, "loss": 0.40235, "time": 0.01018}
{"mode": "train", "epoch": 14, "iter": 30, "lr": 0.0003, "memory": 269, "data_time": 0.00022, "loss": 0.42453, "time": 0.01074}
{"mode": "train", "epoch": 14, "iter": 40, "lr": 0.0003, "memory": 269, "data_time": 0.00023, "loss": 0.37833, "time": 0.0099}
{"mode": "train", "epoch": 14, "iter": 50, "lr": 0.00031, "memory": 269, "data_time": 0.00023, "loss": 0.41576, "time": 0.01005}
{"mode": "train", "epoch": 14, "iter": 60, "lr": 0.00031, "memory": 269, "data_time": 0.00023, "loss": 0.50238, "time": 0.01002}
{"mode": "train", "epoch": 14, "iter": 70, "lr": 0.00031, "memory": 269, "data_time": 0.00022, "loss": 0.33872, "time": 0.01003}
{"mode": "train", "epoch": 14, "iter": 80, "lr": 0.00031, "memory": 269, "data_time": 0.00022, "loss": 0.34626, "time": 0.01009}
{"mode": "train", "epoch": 14, "iter": 90, "lr": 0.00031, "memory": 269, "data_time": 0.00022, "loss": 0.35269, "time": 0.00996}
{"mode": "train", "epoch": 14, "iter": 100, "lr": 0.00031, "memory": 269, "data_time": 0.00023, "loss": 0.44093, "time": 0.01004}
{"mode": "train", "epoch": 14, "iter": 110, "lr": 0.00031, "memory": 269, "data_time": 0.00023, "loss": 0.4504, "time": 0.01003}
{"mode": "train", "epoch": 14, "iter": 120, "lr": 0.00032, "memory": 269, "data_time": 0.00024, "loss": 0.30479, "time": 0.01003}
{"mode": "train", "epoch": 14, "iter": 130, "lr": 0.00032, "memory": 269, "data_time": 0.00023, "loss": 0.34101, "time": 0.00998}
{"mode": "train", "epoch": 14, "iter": 140, "lr": 0.00032, "memory": 269, "data_time": 0.00023, "loss": 0.41158, "time": 0.00995}
{"mode": "train", "epoch": 14, "iter": 150, "lr": 0.00032, "memory": 269, "data_time": 0.00023, "loss": 0.40647, "time": 0.00959}
{"mode": "val", "epoch": 14, "iter": 19, "lr": 0.00032, "accuracy_top-1": 75.0}
{"mode": "val", "epoch": 14, "iter": 19, "lr": 0.00032, "memory": 269, "data_time": 0.1093, "loss": 0.52516, "time": 0.11252}
{"mode": "train", "epoch": 15, "iter": 10, "lr": 0.00032, "memory": 269, "data_time": 0.20248, "loss": 0.44733, "time": 0.21216}
{"mode": "train", "epoch": 15, "iter": 20, "lr": 0.00032, "memory": 269, "data_time": 0.00034, "loss": 0.32809, "time": 0.00995}
{"mode": "train", "epoch": 15, "iter": 30, "lr": 0.00032, "memory": 269, "data_time": 0.00029, "loss": 0.43869, "time": 0.01004}
{"mode": "train", "epoch": 15, "iter": 40, "lr": 0.00033, "memory": 269, "data_time": 0.00027, "loss": 0.29675, "time": 0.01006}
{"mode": "train", "epoch": 15, "iter": 50, "lr": 0.00033, "memory": 269, "data_time": 0.00022, "loss": 0.33629, "time": 0.00996}
{"mode": "train", "epoch": 15, "iter": 60, "lr": 0.00033, "memory": 269, "data_time": 0.00023, "loss": 0.30128, "time": 0.00998}
{"mode": "train", "epoch": 15, "iter": 70, "lr": 0.00033, "memory": 269, "data_time": 0.00023, "loss": 0.39487, "time": 0.00986}
{"mode": "train", "epoch": 15, "iter": 80, "lr": 0.00033, "memory": 269, "data_time": 0.00023, "loss": 0.42551, "time": 0.00975}
{"mode": "train", "epoch": 15, "iter": 90, "lr": 0.00033, "memory": 269, "data_time": 0.00024, "loss": 0.45535, "time": 0.00988}
{"mode": "train", "epoch": 15, "iter": 100, "lr": 0.00033, "memory": 269, "data_time": 0.00024, "loss": 0.39687, "time": 0.00995}
{"mode": "train", "epoch": 15, "iter": 110, "lr": 0.00034, "memory": 269, "data_time": 0.00024, "loss": 0.42726, "time": 0.00985}
{"mode": "train", "epoch": 15, "iter": 120, "lr": 0.00034, "memory": 269, "data_time": 0.00025, "loss": 0.38595, "time": 0.00967}
{"mode": "train", "epoch": 15, "iter": 130, "lr": 0.00034, "memory": 269, "data_time": 0.00026, "loss": 0.39483, "time": 0.00995}
{"mode": "train", "epoch": 15, "iter": 140, "lr": 0.00034, "memory": 269, "data_time": 0.00025, "loss": 0.38556, "time": 0.01001}
{"mode": "train", "epoch": 15, "iter": 150, "lr": 0.00034, "memory": 269, "data_time": 0.00024, "loss": 0.35551, "time": 0.00998}
{"mode": "val", "epoch": 15, "iter": 19, "lr": 0.00034, "accuracy_top-1": 87.33334}
{"mode": "val", "epoch": 15, "iter": 19, "lr": 0.00034, "memory": 269, "data_time": 0.10851, "loss": 0.43766, "time": 0.11181}
{"mode": "train", "epoch": 16, "iter": 10, "lr": 0.00034, "memory": 269, "data_time": 0.20304, "loss": 0.39222, "time": 0.21502}
{"mode": "train", "epoch": 16, "iter": 20, "lr": 0.00034, "memory": 269, "data_time": 0.00023, "loss": 0.418, "time": 0.01063}
{"mode": "train", "epoch": 16, "iter": 30, "lr": 0.00034, "memory": 269, "data_time": 0.00023, "loss": 0.31448, "time": 0.01055}
{"mode": "train", "epoch": 16, "iter": 40, "lr": 0.00035, "memory": 269, "data_time": 0.00022, "loss": 0.37055, "time": 0.01087}
{"mode": "train", "epoch": 16, "iter": 50, "lr": 0.00035, "memory": 269, "data_time": 0.00022, "loss": 0.39373, "time": 0.01081}
{"mode": "train", "epoch": 16, "iter": 60, "lr": 0.00035, "memory": 269, "data_time": 0.00021, "loss": 0.45488, "time": 0.0107}
{"mode": "train", "epoch": 16, "iter": 70, "lr": 0.00035, "memory": 269, "data_time": 0.00021, "loss": 0.48116, "time": 0.01076}
{"mode": "train", "epoch": 16, "iter": 80, "lr": 0.00035, "memory": 269, "data_time": 0.00021, "loss": 0.47679, "time": 0.0106}
{"mode": "train", "epoch": 16, "iter": 90, "lr": 0.00035, "memory": 269, "data_time": 0.00021, "loss": 0.34368, "time": 0.01085}
{"mode": "train", "epoch": 16, "iter": 100, "lr": 0.00035, "memory": 269, "data_time": 0.00021, "loss": 0.32329, "time": 0.01064}
{"mode": "train", "epoch": 16, "iter": 110, "lr": 0.00036, "memory": 269, "data_time": 0.00021, "loss": 0.40797, "time": 0.01071}
{"mode": "train", "epoch": 16, "iter": 120, "lr": 0.00036, "memory": 269, "data_time": 0.00021, "loss": 0.37784, "time": 0.01083}
{"mode": "train", "epoch": 16, "iter": 130, "lr": 0.00036, "memory": 269, "data_time": 0.00021, "loss": 0.35939, "time": 0.01073}
{"mode": "train", "epoch": 16, "iter": 140, "lr": 0.00036, "memory": 269, "data_time": 0.00021, "loss": 0.38833, "time": 0.01075}
{"mode": "train", "epoch": 16, "iter": 150, "lr": 0.00036, "memory": 269, "data_time": 0.00021, "loss": 0.39495, "time": 0.01024}
{"mode": "val", "epoch": 16, "iter": 19, "lr": 0.00036, "accuracy_top-1": 92.0}
{"mode": "val", "epoch": 16, "iter": 19, "lr": 0.00036, "memory": 269, "data_time": 0.10818, "loss": 0.41051, "time": 0.11165}
{"mode": "train", "epoch": 17, "iter": 10, "lr": 0.00036, "memory": 269, "data_time": 0.20382, "loss": 0.47876, "time": 0.21465}
{"mode": "train", "epoch": 17, "iter": 20, "lr": 0.00036, "memory": 269, "data_time": 0.00022, "loss": 0.37198, "time": 0.01092}
{"mode": "train", "epoch": 17, "iter": 30, "lr": 0.00036, "memory": 269, "data_time": 0.00022, "loss": 0.39585, "time": 0.01074}
{"mode": "train", "epoch": 17, "iter": 40, "lr": 0.00037, "memory": 269, "data_time": 0.00022, "loss": 0.3725, "time": 0.01}
{"mode": "train", "epoch": 17, "iter": 50, "lr": 0.00037, "memory": 269, "data_time": 0.00024, "loss": 0.36658, "time": 0.0101}
{"mode": "train", "epoch": 17, "iter": 60, "lr": 0.00037, "memory": 269, "data_time": 0.00023, "loss": 0.30508, "time": 0.01012}
{"mode": "train", "epoch": 17, "iter": 70, "lr": 0.00037, "memory": 269, "data_time": 0.00026, "loss": 0.28481, "time": 0.01014}
{"mode": "train", "epoch": 17, "iter": 80, "lr": 0.00037, "memory": 269, "data_time": 0.00028, "loss": 0.4042, "time": 0.01006}
{"mode": "train", "epoch": 17, "iter": 90, "lr": 0.00037, "memory": 269, "data_time": 0.00027, "loss": 0.36643, "time": 0.01007}
{"mode": "train", "epoch": 17, "iter": 100, "lr": 0.00037, "memory": 269, "data_time": 0.00025, "loss": 0.37426, "time": 0.01018}
{"mode": "train", "epoch": 17, "iter": 110, "lr": 0.00037, "memory": 269, "data_time": 0.00021, "loss": 0.36737, "time": 0.01006}
{"mode": "train", "epoch": 17, "iter": 120, "lr": 0.00038, "memory": 269, "data_time": 0.00025, "loss": 0.45446, "time": 0.01004}
{"mode": "train", "epoch": 17, "iter": 130, "lr": 0.00038, "memory": 269, "data_time": 0.00024, "loss": 0.44258, "time": 0.01014}
{"mode": "train", "epoch": 17, "iter": 140, "lr": 0.00038, "memory": 269, "data_time": 0.00026, "loss": 0.37326, "time": 0.01024}
{"mode": "train", "epoch": 17, "iter": 150, "lr": 0.00038, "memory": 269, "data_time": 0.00023, "loss": 0.37934, "time": 0.00966}
{"mode": "val", "epoch": 17, "iter": 19, "lr": 0.00038, "accuracy_top-1": 88.66667}
{"mode": "val", "epoch": 17, "iter": 19, "lr": 0.00038, "memory": 269, "data_time": 0.10936, "loss": 0.41203, "time": 0.11277}
{"mode": "train", "epoch": 18, "iter": 10, "lr": 0.00038, "memory": 269, "data_time": 0.20329, "loss": 0.30723, "time": 0.21374}
{"mode": "train", "epoch": 18, "iter": 20, "lr": 0.00038, "memory": 269, "data_time": 0.00033, "loss": 0.28867, "time": 0.01178}
{"mode": "train", "epoch": 18, "iter": 30, "lr": 0.00038, "memory": 269, "data_time": 0.00023, "loss": 0.30934, "time": 0.01158}
{"mode": "train", "epoch": 18, "iter": 40, "lr": 0.00038, "memory": 269, "data_time": 0.00022, "loss": 0.30648, "time": 0.01051}
{"mode": "train", "epoch": 18, "iter": 50, "lr": 0.00039, "memory": 269, "data_time": 0.00022, "loss": 0.34597, "time": 0.01011}
{"mode": "train", "epoch": 18, "iter": 60, "lr": 0.00039, "memory": 269, "data_time": 0.00021, "loss": 0.47903, "time": 0.01}
{"mode": "train", "epoch": 18, "iter": 70, "lr": 0.00039, "memory": 269, "data_time": 0.00025, "loss": 0.45031, "time": 0.00994}
{"mode": "train", "epoch": 18, "iter": 80, "lr": 0.00039, "memory": 269, "data_time": 0.00024, "loss": 0.38219, "time": 0.01058}
{"mode": "train", "epoch": 18, "iter": 90, "lr": 0.00039, "memory": 269, "data_time": 0.0002, "loss": 0.46886, "time": 0.01087}
{"mode": "train", "epoch": 18, "iter": 100, "lr": 0.00039, "memory": 269, "data_time": 0.00021, "loss": 0.34056, "time": 0.01062}
{"mode": "train", "epoch": 18, "iter": 110, "lr": 0.00039, "memory": 269, "data_time": 0.00026, "loss": 0.39509, "time": 0.01113}
{"mode": "train", "epoch": 18, "iter": 120, "lr": 0.00039, "memory": 269, "data_time": 0.00022, "loss": 0.31847, "time": 0.01104}
{"mode": "train", "epoch": 18, "iter": 130, "lr": 0.0004, "memory": 269, "data_time": 0.00025, "loss": 0.34055, "time": 0.01073}
{"mode": "train", "epoch": 18, "iter": 140, "lr": 0.0004, "memory": 269, "data_time": 0.00023, "loss": 0.32302, "time": 0.01055}
{"mode": "train", "epoch": 18, "iter": 150, "lr": 0.0004, "memory": 269, "data_time": 0.00025, "loss": 0.31109, "time": 0.00997}
{"mode": "val", "epoch": 18, "iter": 19, "lr": 0.0004, "accuracy_top-1": 85.33334}
{"mode": "val", "epoch": 18, "iter": 19, "lr": 0.0004, "memory": 269, "data_time": 0.10907, "loss": 0.40347, "time": 0.11289}
{"mode": "train", "epoch": 19, "iter": 10, "lr": 0.0004, "memory": 269, "data_time": 0.20301, "loss": 0.44024, "time": 0.21413}
{"mode": "train", "epoch": 19, "iter": 20, "lr": 0.0004, "memory": 269, "data_time": 0.00031, "loss": 0.27516, "time": 0.01052}
{"mode": "train", "epoch": 19, "iter": 30, "lr": 0.0004, "memory": 269, "data_time": 0.00033, "loss": 0.40845, "time": 0.0103}
{"mode": "train", "epoch": 19, "iter": 40, "lr": 0.0004, "memory": 269, "data_time": 0.00027, "loss": 0.38017, "time": 0.01058}
{"mode": "train", "epoch": 19, "iter": 50, "lr": 0.0004, "memory": 269, "data_time": 0.00024, "loss": 0.34387, "time": 0.01047}
{"mode": "train", "epoch": 19, "iter": 60, "lr": 0.00041, "memory": 269, "data_time": 0.00025, "loss": 0.35835, "time": 0.01046}
{"mode": "train", "epoch": 19, "iter": 70, "lr": 0.00041, "memory": 269, "data_time": 0.00024, "loss": 0.36313, "time": 0.01048}
{"mode": "train", "epoch": 19, "iter": 80, "lr": 0.00041, "memory": 269, "data_time": 0.00026, "loss": 0.34476, "time": 0.01026}
{"mode": "train", "epoch": 19, "iter": 90, "lr": 0.00041, "memory": 269, "data_time": 0.00029, "loss": 0.35152, "time": 0.01038}
{"mode": "train", "epoch": 19, "iter": 100, "lr": 0.00041, "memory": 269, "data_time": 0.00022, "loss": 0.32114, "time": 0.01013}
{"mode": "train", "epoch": 19, "iter": 110, "lr": 0.00041, "memory": 269, "data_time": 0.00025, "loss": 0.37278, "time": 0.01027}
{"mode": "train", "epoch": 19, "iter": 120, "lr": 0.00041, "memory": 269, "data_time": 0.00025, "loss": 0.40813, "time": 0.01116}
{"mode": "train", "epoch": 19, "iter": 130, "lr": 0.00041, "memory": 269, "data_time": 0.0002, "loss": 0.45687, "time": 0.01063}
{"mode": "train", "epoch": 19, "iter": 140, "lr": 0.00042, "memory": 269, "data_time": 0.00028, "loss": 0.3565, "time": 0.01021}
{"mode": "train", "epoch": 19, "iter": 150, "lr": 0.00042, "memory": 269, "data_time": 0.0003, "loss": 0.42207, "time": 0.01113}
{"mode": "val", "epoch": 19, "iter": 19, "lr": 0.00042, "accuracy_top-1": 86.33334}
{"mode": "val", "epoch": 19, "iter": 19, "lr": 0.00042, "memory": 269, "data_time": 0.10973, "loss": 0.43014, "time": 0.11305}
{"mode": "train", "epoch": 20, "iter": 10, "lr": 0.00042, "memory": 269, "data_time": 0.20232, "loss": 0.32305, "time": 0.21264}
{"mode": "train", "epoch": 20, "iter": 20, "lr": 0.00042, "memory": 269, "data_time": 0.00033, "loss": 0.32401, "time": 0.01048}
{"mode": "train", "epoch": 20, "iter": 30, "lr": 0.00042, "memory": 269, "data_time": 0.0003, "loss": 0.3734, "time": 0.01044}
{"mode": "train", "epoch": 20, "iter": 40, "lr": 0.00042, "memory": 269, "data_time": 0.00024, "loss": 0.33193, "time": 0.01009}
{"mode": "train", "epoch": 20, "iter": 50, "lr": 0.00042, "memory": 269, "data_time": 0.00028, "loss": 0.26771, "time": 0.01035}
{"mode": "train", "epoch": 20, "iter": 60, "lr": 0.00042, "memory": 269, "data_time": 0.00024, "loss": 0.39993, "time": 0.01031}
{"mode": "train", "epoch": 20, "iter": 70, "lr": 0.00042, "memory": 269, "data_time": 0.00025, "loss": 0.3285, "time": 0.01093}
{"mode": "train", "epoch": 20, "iter": 80, "lr": 0.00043, "memory": 269, "data_time": 0.00022, "loss": 0.37151, "time": 0.01119}
{"mode": "train", "epoch": 20, "iter": 90, "lr": 0.00043, "memory": 269, "data_time": 0.00025, "loss": 0.50516, "time": 0.01163}
{"mode": "train", "epoch": 20, "iter": 100, "lr": 0.00043, "memory": 269, "data_time": 0.00022, "loss": 0.42458, "time": 0.01068}
{"mode": "train", "epoch": 20, "iter": 110, "lr": 0.00043, "memory": 269, "data_time": 0.00023, "loss": 0.39369, "time": 0.01012}
{"mode": "train", "epoch": 20, "iter": 120, "lr": 0.00043, "memory": 269, "data_time": 0.00026, "loss": 0.3943, "time": 0.01086}
{"mode": "train", "epoch": 20, "iter": 130, "lr": 0.00043, "memory": 269, "data_time": 0.00023, "loss": 0.41789, "time": 0.0108}
{"mode": "train", "epoch": 20, "iter": 140, "lr": 0.00043, "memory": 269, "data_time": 0.00026, "loss": 0.34054, "time": 0.01046}
{"mode": "train", "epoch": 20, "iter": 150, "lr": 0.00043, "memory": 269, "data_time": 0.00025, "loss": 0.34543, "time": 0.00995}
{"mode": "val", "epoch": 20, "iter": 19, "lr": 0.00043, "accuracy_top-1": 92.66667}
....
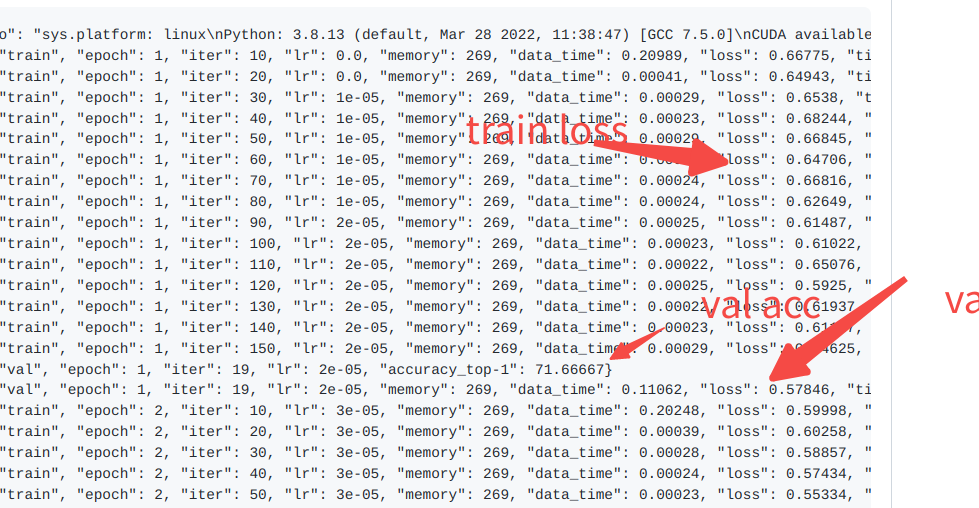
you can get this element and plot.
Modify the model to the flowing, then you can get the 'train_acc' in the log,
model = dict(
backbone=dict(
init_cfg = dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth',
prefix='backbone')
),
head=dict(
num_classes=2,
topk = (1,5 ),
cal_acc =True,
))
you can get this element and plot.
Modify the model to the flowing, then you can get the 'train_acc' in the log,
model = dict( backbone=dict( init_cfg = dict( type='Pretrained', checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth', prefix='backbone') ), head=dict( num_classes=2, topk = (1,5 ), cal_acc =True, ))
Hi, I have add cal_acc=True in my model, but when I tried to train it, it raise an error as the img below.
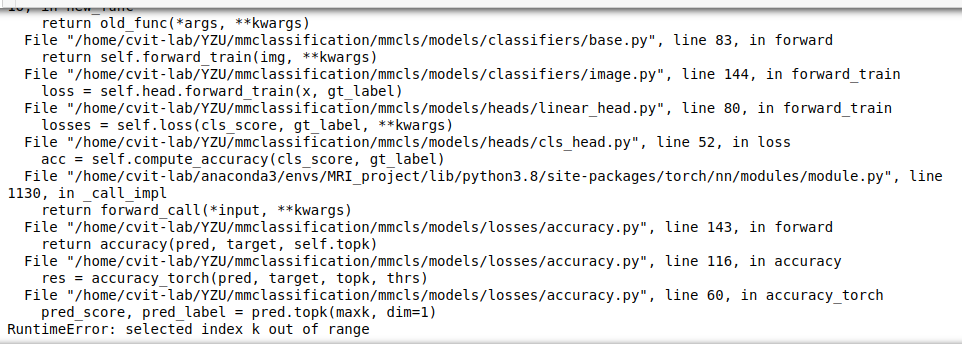
topk = (1,5 ) to topk = (1,), Since you only have two classes.
model = dict(
backbone=dict(
init_cfg = dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth',
prefix='backbone')
),
head=dict(
num_classes=2,
topk = (1,),
cal_acc =True,
))
topk = (1,5 )totopk = (1,), Since you only have two classes.model = dict( backbone=dict( init_cfg = dict( type='Pretrained', checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth', prefix='backbone') ), head=dict( num_classes=2, topk = (1,), cal_acc =True, ))
Thank you for you help. Also, the top-1 in 1071 is the val_acc for the model at the end of training, right? Cause I do not know why there are 2 line of val epoch:100 with the same iter, but different in length.

Sorry, could you please tell me how did you get these graphs, exactly?
I'm using the function !python tools/analysis_tools/analyze_logs.py plot_curve but it gives me an error, due to the fact that val loss and train loss have the same name : "loss". So i think that it doesn't distinguish them. I think that the right command to fix this is to pass the right --keys. Have you got any advice? please. Thank you!
Sorry, could you please tell me how did you get these graphs, exactly?
I'm using the function
!python tools/analysis_tools/analyze_logs.py plot_curvebut it gives me an error, due to the fact that val loss and train loss have the same name : "loss". So i think that it doesn't distinguish them. I think that the right command to fix this is to pass the right--keys. Have you got any advice? please. Thank you!
Hi, the graph above is just an example on the internet bro.
Btw if you wanna plot the curve by this tool, the code for accuracy is below, for example
!python tools/analysis_tools/analyze_logs.py plot_curve your-json-log-file --keys accuracy_top-1 --legend accuracy --out imgname.jpg
topk = (1,5 )totopk = (1,), Since you only have two classes.model = dict( backbone=dict( init_cfg = dict( type='Pretrained', checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth', prefix='backbone') ), head=dict( num_classes=2, topk = (1,), cal_acc =True, ))
Hi, I check my log.json file and got 2 row of validation value as below, I don't know which one is the val_acc at the end of training step?

Thank you for your reply! At the end, I did my own funtion for that graphs. Thank you anyway!
On Thu, 24 Nov 2022, 03:57 TranTriDat, @.***> wrote:
Sorry, could you please tell me how did you get these graphs, exactly?
[image: image] https://user-images.githubusercontent.com/102518682/197334419-dc92d9b1-b3ac-4080-91a6-fc75a8a689cd.png
I'm using the function !python tools/analysis_tools/analyze_logs.py plot_curve but it gives me an error, due to the fact that val loss and train loss have the same name : "loss". So i think that it doesn't distinguish them. I think that the right command to fix this is to pass the right --keys. Have you got any advice? please. Thank you!
Hi, the graph above is just an example on the internet bro.
Btw if you wanna plot the curve by this tool, the code for accuracy is below, for example !python tools/analysis_tools/analyze_logs.py plot_curve your-json-log-file --keys accuracy_top-1 --legend accuracy --out imgname.jpg
— Reply to this email directly, view it on GitHub https://github.com/open-mmlab/mmclassification/issues/993#issuecomment-1325883788, or unsubscribe https://github.com/notifications/unsubscribe-auth/AYOE7GU53KVEDMQPCK3JD6LWJ3KR7ANCNFSM57ROVPFQ . You are receiving this because you commented.Message ID: @.***>
This issue will be closed as it is inactive, feel free to re-open it if necessary.
This issue will be closed as it is inactive, feel free to re-open it if necessary.
Wait what about my question sir
topk = (1,5 )totopk = (1,), Since you only have two classes.model = dict( backbone=dict( init_cfg = dict( type='Pretrained', checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth', prefix='backbone') ), head=dict( num_classes=2, topk = (1,), cal_acc =True, ))Hi, I check my log.json file and got 2 row of validation value as below, I don't know which one is the val_acc at the end of training step?
Yes this one