[Feature] Support LitePose
Motivation
Integrate LitePose (CVPR2022) into mmpose.
Modification
Add LitePose backbone, head and configs. The code is adapted from https://github.com/mit-han-lab/litepose.
We re-trained our XS model on COCO dataset and our XS and S models on crowdpose dataset using mmpose. For other models like M/L models, we convert our trained weights from our original codebase into mmpose weights format.
Our weights for mmpose are provided in https://drive.google.com/drive/folders/15mBdpnMXvwDgfiHqcSzFrfl9_iz7Fskn?usp=sharing. Pretrained weights for each configs are in pretrained folders, and the trained model weights are in ready folders. Each config (XS/S/M/L for coco/crowdpose) has its own unique pretrained weight.
BC-breaking (Optional)
Use cases (Optional)
Checklist
Before PR:
- [x] I have read and followed the workflow indicated in the CONTRIBUTING.md to create this PR.
- [x] Pre-commit or linting tools indicated in CONTRIBUTING.md are used to fix the potential lint issues.
- [x] Bug fixes are covered by unit tests, the case that causes the bug should be added in the unit tests.
- [x] New functionalities are covered by complete unit tests. If not, please add more unit tests to ensure correctness.
- [x] The documentation has been modified accordingly, including docstring or example tutorials.
After PR:
- [ ] CLA has been signed and all committers have signed the CLA in this PR.
We re-trained our XS model on COCO dataset and our XS and S models on crowdpose dataset using mmpose. Hi @senfu , could you please also share the log.json of these models? This will be helpful for our model re-training check.
Codecov Report
Base: 84.32% // Head: 84.31% // Decreases project coverage by -0.01% :warning:
Coverage data is based on head (
36495e9) compared to base (7616b62). Patch coverage: 83.84% of modified lines in pull request are covered.
:exclamation: Current head 36495e9 differs from pull request most recent head 2bd795f. Consider uploading reports for the commit 2bd795f to get more accurate results
Additional details and impacted files
@@ Coverage Diff @@
## dev-0.29 #1486 +/- ##
============================================
- Coverage 84.32% 84.31% -0.02%
============================================
Files 232 238 +6
Lines 19284 20218 +934
Branches 3470 3642 +172
============================================
+ Hits 16262 17046 +784
- Misses 2157 2291 +134
- Partials 865 881 +16
| Flag | Coverage Δ | |
|---|---|---|
| unittests | 84.21% <83.21%> (-0.05%) |
:arrow_down: |
Flags with carried forward coverage won't be shown. Click here to find out more.
| Impacted Files | Coverage Δ | |
|---|---|---|
| mmpose/apis/inference_3d.py | 77.57% <ø> (ø) |
|
| mmpose/models/detectors/interhand_3d.py | 60.29% <ø> (ø) |
|
| mmpose/models/detectors/pose_lifter.py | 70.22% <ø> (ø) |
|
| mmpose/models/heads/litepose_head.py | 57.14% <57.14%> (ø) |
|
| mmpose/models/utils/tcformer_utils.py | 83.08% <83.08%> (ø) |
|
| mmpose/models/backbones/litepose.py | 83.60% <83.60%> (ø) |
|
| mmpose/models/necks/tcformer_mta_neck.py | 84.78% <84.78%> (ø) |
|
| ...datasets/datasets/top_down/topdown_coco_dataset.py | 89.74% <92.30%> (+0.16%) |
:arrow_up: |
| mmpose/models/backbones/tcformer.py | 95.76% <95.76%> (ø) |
|
| ...re/optimizers/layer_decay_optimizer_constructor.py | 96.11% <96.11%> (ø) |
|
| ... and 13 more |
Help us with your feedback. Take ten seconds to tell us how you rate us. Have a feature suggestion? Share it here.
:umbrella: View full report at Codecov.
:loudspeaker: Do you have feedback about the report comment? Let us know in this issue.
Hi @jin-s13, I uploaded the log.json files to https://drive.google.com/drive/folders/1wvTZVqAKQevob-pjhLy1ZmWEkKI_w9gB?usp=sharing
I have good news to share. I have retrained LitePose_XS on coco using the provided config file with MMPose. And it achieves better performance than the paper reported result (0.432 vs 0.406). And I will also train other models.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.432 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.682 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.452 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.300 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.637 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.497 Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.724 Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.517 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.339 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.714
Dear @senfu , In the table below, we compare the results of (1) reported in official LitePose Repo (2) Using MMPose to load the official released model (converted the official checkpoint to fit the name of the MMPose model) (3) Retraining models using MMPose.
| Dataset | Model | official Repo | MMPose-load | MMPose-trained |
|---|---|---|---|---|
| CrowdPose | LitePose-Auto-L | 61.9 | - | 61.1 |
| CrowdPose | LitePose-Auto-M | 59.9 | 60.5 | 58.5 |
| CrowdPose | LitePose-Auto-S | 58.3 | 58.5 | 58.2 |
| CrowdPose | LitePose-Auto-XS | 49.5 | 49.3 | 49.3 |
| COCO | LitePose-Auto-L | 62.5 | 62.4 | 61.2 |
| COCO | LitePose-Auto-M | 59.8 | 59.6 | 56.1 |
| COCO | LitePose-Auto-S | 56.8 | 57.2 | 54.2 |
| COCO | LitePose-Auto-XS | 40.6 | - | 43.7 |
For CrowdPose, LitePose-Auto-S and LitePose-Auto-XS achieve very similar results but the mAP of LitePose-Auto-M seems to be slightly lower. For COCO, LitePose-Auto-XS achieves a much better result, but LitePose-Auto-S and LitePose-Auto-M have lower mAP. LitePose-Auto-L models are still in training (it will take one or two days).
Since MMPose can successfully load the officially trained models, the model architecture seems to be the same. Maybe the problem lies in the different training hyper-parameters? What do you think? @senfu
The conversion script (ckpt_convert.py), converted pre-trained models (MMPose_pretrain) and MMPose re-trained models and logs (MMPose_Trained) can be found in the onedrive link below.
https://connecthkuhk-my.sharepoint.com/:f:/g/personal/js20_connect_hku_hk/En_a7jce0RZNnsgv7sqo4qwBgv0YWYyTWkb9MmNmwEB11Q?e=YUc0BR
====================================================================================== Update on 7.27: We notice that the pre-trained model contains both the parameters of the backbone and the keypoint head. But during training, only the pre-trained parameters of the backbone is loaded. This might cause the performance drop. We will check this later.
Well, the pretrained weight for head is not needed and is not loaded during training in our original implementation. We are looking into this issue and trying to figure out the solution.
Hi there, I train the LitePose-S on coco with config configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/litepose_S_coco_448x448.py and pretrained model converted from LitePose/0927/pretrained/coco-pretrained-S-mmpose.pth using the script provided by @jin-s13, but got results slightly lower than reported (AP: 56.3).
The comparison of loss and AP between the training log (retrain) and the log provided at
LitePose/0927/logs/coco-S.log.json (provided) is shown below
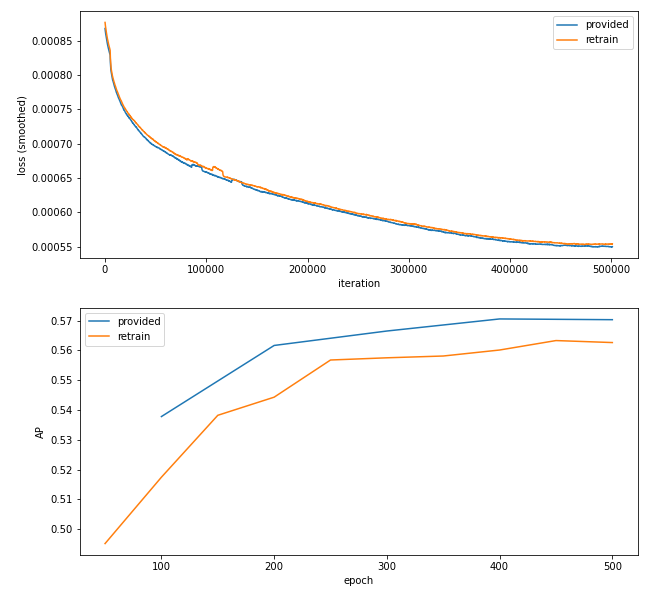
Do you have any idea about the cause of this accuracy degradation?
Hi, I am unsure why the accuracy degradation happens, and I am rerunning the experiment now. I doubled check that the pre-trained weights I provided are correct, so the main issue could be the config itself. Have you tried other configs like litepose_M_coco_448x448.py?
Hi, I am unsure why the accuracy degradation happens, and I am rerunning the experiment now. I doubled check that the pre-trained weights I provided are correct, so the main issue could be the config itself. Have you tried other configs like litepose_M_coco_448x448.py?
Thanks for your help. Do you use the pretrained models directly or convert them before training?
Hi @senfu !We are grateful for your efforts in helping improve mmpose open-source project during your personal time.
Welcome to join OpenMMLab Special Interest Group (SIG) private channel on Discord, where you can share your experiences, ideas, and build connections with like-minded peers. To join the SIG channel, simply message moderator— OpenMMLab on Discord or briefly share your open-source contributions in the #introductions channel and we will assist you. Look forward to seeing you there! Join us :https://discord.gg/UjgXkPWNqA If you have a WeChat account,welcome to join our community on WeChat. You can add our assistant :openmmlabwx. Please add "mmsig + Github ID" as a remark when adding friends:)
Thank you again for your contribution❤