mmdetection3d
 mmdetection3d copied to clipboard
mmdetection3d copied to clipboard
Using SECOND to train my own model,and test on Kitti which getting a poor result. APs are all 0
Thanks for your error report and we appreciate it a lot.
Checklist
- I have searched related issues but cannot get the expected help.
- The bug has not been fixed in the latest version.
Describe the bug A clear and concise description of what the bug is. Using SECOND to train my own model,and test on Kitti which getting a poor result. APs are all 0
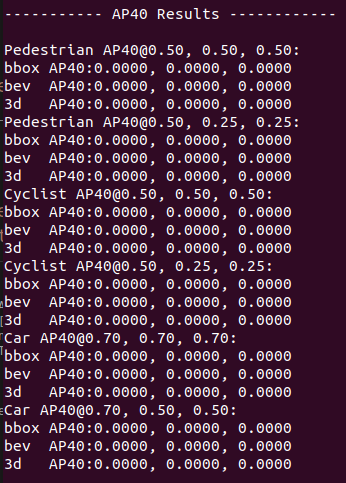
Reproduction
- What command or script did you run?
./tools/dist_test.sh ./work_dirs/hv_second_secfpn_6x8_80e_kitti-3d-3class/hv_second_secfpn_6x8_80e_kitti-3d-3class.py ./work_dirs/hv_second_secfpn_6x8_80e_kitti-3d-3class/latest.pth 2 --eval mAP
- Did you make any modifications on the code or config? Did you understand what you have modified? Didn't modifiy code
- What dataset did you use? KITTI
Environment
- Please run
python mmdet3d/utils/collect_env.pyto collect necessary environment information and paste it here.
sys.platform: linux
Python: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0]
CUDA available: True
GPU 0: GeForce RTX 2080 Ti
GPU 1: GeForce RTX 2080
CUDA_HOME: /usr/local/cuda
NVCC: Cuda compilation tools, release 10.2, V10.2.8
GCC: gcc (Ubuntu 7.5.0-3ubuntu1~16.04) 7.5.0
PyTorch: 1.12.0
PyTorch compiling details: PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.2 Product Build 20200624 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.6.0 (Git Hash 52b5f107dd9cf10910aaa19cb47f3abf9b349815)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.2
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_37,code=compute_37
- CuDNN 7.6.5
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=10.2, CUDNN_VERSION=7.6.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.12.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
TorchVision: 0.13.0
OpenCV: 4.6.0
MMCV: 1.6.0
MMCV Compiler: GCC 7.3
MMCV CUDA Compiler: 10.2
MMDetection: 2.25.0
MMSegmentation: 0.26.0
MMDetection3D: 1.0.0rc3+eef0f97
spconv2.0: True
- You may add addition that may be helpful for locating the problem, such as
- How you installed PyTorch [e.g., pip, conda, source] conda install
- Other environment variables that may be related (such as
$PATH,$LD_LIBRARY_PATH,$PYTHONPATH, etc.)
$PATH: /home/mtrsrv/anaconda3/envs/openmmlab/bin:/usr/local/cuda-10.2/bin:/home/mtrsrv/anaconda3/envs/pytorch_3dseg/bin:/home/mtrsrv/bin:/home/mtrsrv/.local/bin:/home/mtrsrv/anaconda3/envs/tf-agents/bin:/home/mtrsrv/anaconda3/bin/:/usr/local/cuda/bin/:/usr/local/cuda-9.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
$LD_LIBRARY_PATH: /usr/local/cuda/lib64/:/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:}:/usr/lib/nvidia-410:/usr/lib/nvidia-418:/usr/lib/nvidia-440:/home/mtrsrv/.mujoco/mujoco200/bin:/usr/local/lib/HKlib:/40T/wai4/wjt/yolov5-tensorrt/tensorrt-7.1/TensorRT-7.1.3.4/lib
- TRACEBACK linux terminal show that the model and loaded state dict do not match exactly
The model and loaded state dict do not match exactly
size mismatch for middle_encoder.conv_input.0.weight: copying a param with shape ('middle_encoder.conv_input.0.weight', torch.Size([4, 16, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([16, 3, 3, 3, 4]).
size mismatch for middle_encoder.encoder_layers.encoder_layer1.0.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer1.0.0.weight', torch.Size([16, 16, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([16, 3, 3, 3, 16]).
size mismatch for middle_encoder.encoder_layers.encoder_layer2.0.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer2.0.0.weight', torch.Size([16, 32, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([32, 3, 3, 3, 16]).
size mismatch for middle_encoder.encoder_layers.encoder_layer2.1.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer2.1.0.weight', torch.Size([32, 32, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([32, 3, 3, 3, 32]).
size mismatch for middle_encoder.encoder_layers.encoder_layer2.2.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer2.2.0.weight', torch.Size([32, 32, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([32, 3, 3, 3, 32]).
size mismatch for middle_encoder.encoder_layers.encoder_layer3.0.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer3.0.0.weight', torch.Size([32, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 32]).
size mismatch for middle_encoder.encoder_layers.encoder_layer3.1.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer3.1.0.weight', torch.Size([64, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 64]).
size mismatch for middle_encoder.encoder_layers.encoder_layer3.2.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer3.2.0.weight', torch.Size([64, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 64]).
size mismatch for middle_encoder.encoder_layers.encoder_layer4.0.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer4.0.0.weight', torch.Size([64, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 64]).
size mismatch for middle_encoder.encoder_layers.encoder_layer4.1.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer4.1.0.weight', torch.Size([64, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 64]).
size mismatch for middle_encoder.encoder_layers.encoder_layer4.2.0.weight: copying a param with shape ('middle_encoder.encoder_layers.encoder_layer4.2.0.weight', torch.Size([64, 64, 3, 3, 3])) from checkpoint,the shape in current model is torch.Size([64, 3, 3, 3, 64]).
size mismatch for middle_encoder.conv_out.0.weight: copying a param with shape ('middle_encoder.conv_out.0.weight', torch.Size([64, 128, 3, 1, 1])) from checkpoint,the shape in current model is torch.Size([128, 3, 1, 1, 64]).
We recommend using English or English & Chinese for issues so that we could have broader discussion.
Same to this, caused by spconv2.0. Perhaps this is an urgent problem. Although disabling spconv2.0 can avoid this problem, it will consume more GPU memory.
Did you train SECOND on your own dataset or on kitti?
I train SECOND on kitti dataset
Right, it seems like the spconv2.0 issue. You can fix mmdet3d/ops/spconv/init.py to disable spconv2.0.
IS_SPCONV2_AVAILABLE = False
__all__ = ['IS_SPCONV2_AVAILABLE']
And you can delete this line to test your model, it transposes the model's weight dims when loading the model state dict. https://github.com/open-mmlab/mmdetection3d/blob/c8347b7ed933d70fcfbfb73a3541046b8c8e8f5e/mmdet3d/ops/spconv/overwrite_spconv/write_spconv2.py#L37