mmdetection
 mmdetection copied to clipboard
mmdetection copied to clipboard
[WIP] Support Grad Free and Grad Based CAM
We support cam visualization in mmdet. Currently, I have tested RetinaNet, Faster RCNN, Mask RCNN and YOLOX.
Currently grad_free and grad_based methods are supported as shown below:
GRAD_FREE_METHOD_MAP = {
'ablationcam': AblationCAM,
'eigencam': EigenCAM,
# 'scorecam': ScoreCAM, # consumes too much memory
'featmapam': FeatmapAM
}
GRAD_BASE_METHOD_MAP = {
'gradcam': GradCAM,
'gradcam++': GradCAMPlusPlus,
'xgradcam': XGradCAM,
'eigengradcam': EigenGradCAM,
'layercam': LayerCAM
}
Usages
# FeatmapAM method
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth
# EigenCAM method
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --method eigencam
# AblationCAM method
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --method ablationcam
# AblationCAM method and save img
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --method ablationcam --out-dir save_dir
# GradCAM
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --method gradcam
Note:
- The AblationCAM method is slow, it infers many times. If you want to speed up inference, you can reduce the image size in the configuration file and set the
--batch-sizeand--max-reshape-shapeparameter - The
grad_basemethod does not support output multi-activation layers
Visualization
grad free
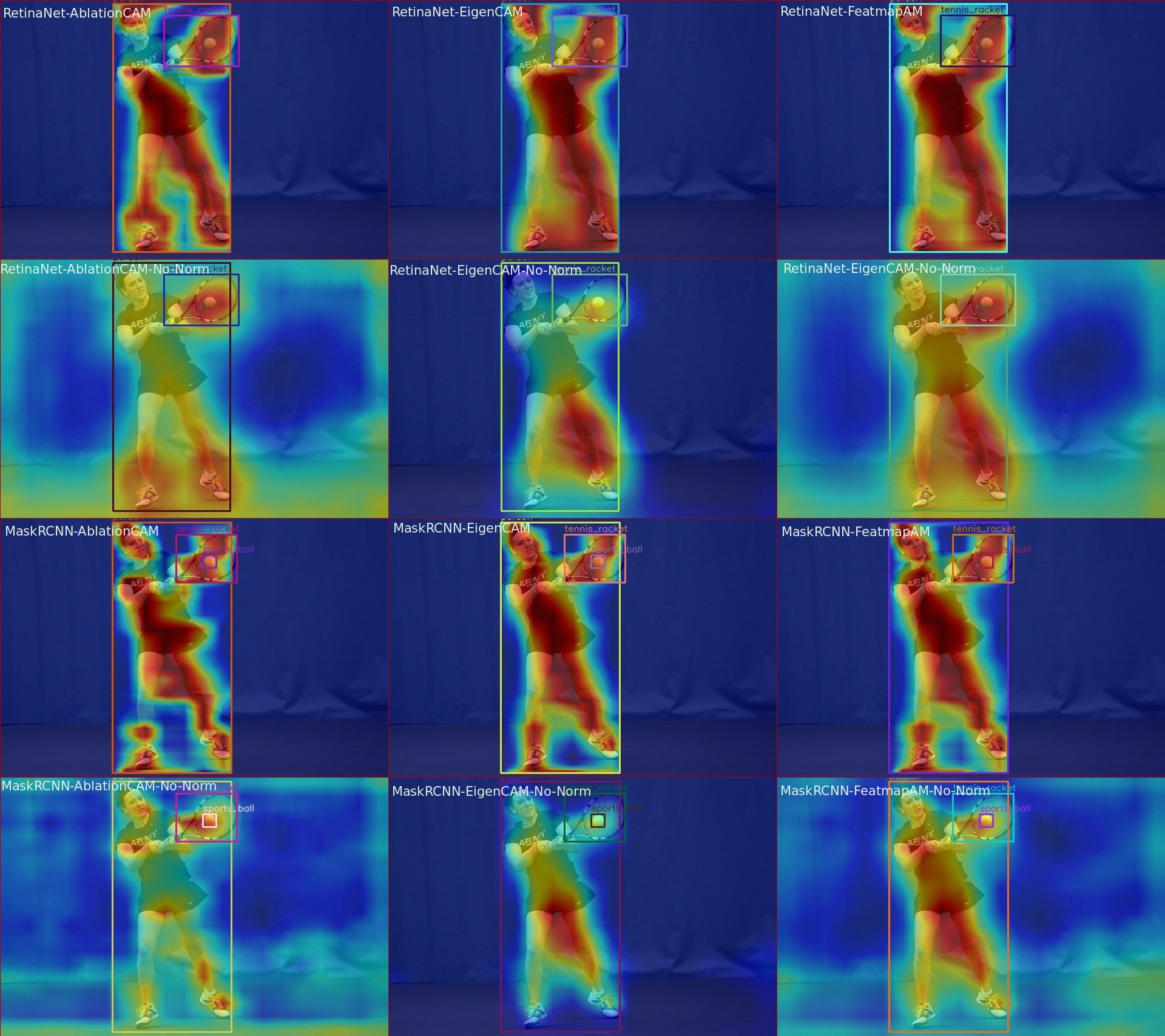


gradcam
python demo/vis_cam.py demo/demo.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --target-layers backbone.layer3 --method gradcam --out-dir save_dir

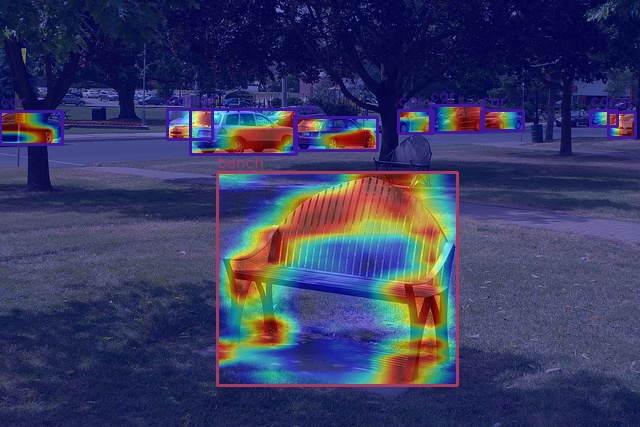
Other
This PR is still in the early stage of development and may have bugs. Everyone is welcome to improve it.
Thank you https://github.com/jacobgil/pytorch-grad-cam and Class Activation Maps for Object Detection With Faster RCNN.ipynb
Codecov Report
Attention: 249 lines in your changes are missing coverage. Please review.
Comparison is base (
48226ea) 64.89% compared to head (e08c9f7) 64.21%. Report is 139 commits behind head on dev.
| Files | Patch % | Lines |
|---|---|---|
| mmdet/utils/det_cam_visualizer.py | 0.00% | 249 Missing :warning: |
Additional details and impacted files
@@ Coverage Diff @@
## dev #7987 +/- ##
==========================================
- Coverage 64.89% 64.21% -0.68%
==========================================
Files 352 353 +1
Lines 28504 28748 +244
Branches 4822 4877 +55
==========================================
- Hits 18497 18461 -36
- Misses 9027 9293 +266
- Partials 980 994 +14
| Flag | Coverage Δ | |
|---|---|---|
| unittests | 64.21% <0.00%> (-0.65%) |
:arrow_down: |
Flags with carried forward coverage won't be shown. Click here to find out more.
:umbrella: View full report in Codecov by Sentry.
:loudspeaker: Have feedback on the report? Share it here.
Thank you so much, I am a beginner in code and will not apply this document to generate heat maps
Bug report using TOOD
Command line:
python3 tools/vis_cam.py "../../Dataset/SmallHuman/images/train/image (201).jpg" "../configs/tood/tood_r50_fpn_1x_coco.py" "../ckpts/tood_r50_fpn_1x_coco.pth" --target-layers="bbox_head.cls_decomp"
Stack trace:
Traceback (most recent call last):
File "E:/Work work/Python/Work/Practice/Object Detection/mmdetection/tools/vis_cam.py", line 238, in <module>
main()
File "E:/Work work/Python/Work/Practice/Object Detection/mmdetection/tools/vis_cam.py", line 215, in main
grayscale_cam = det_cam_visualizer(
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\utils\det_cam_visualizer.py", line 323, in __call__
return self.cam(img, targets, aug_smooth, eigen_smooth)[0, :]
File "E:\Anaconda\envs\openmmlab\lib\site-packages\pytorch_grad_cam\base_cam.py", line 184, in __call__
return self.forward(input_tensor,
File "E:\Anaconda\envs\openmmlab\lib\site-packages\pytorch_grad_cam\base_cam.py", line 74, in forward
outputs = self.activations_and_grads(input_tensor)
File "E:\Anaconda\envs\openmmlab\lib\site-packages\pytorch_grad_cam\activations_and_gradients.py", line 42, in __call__
return self.model(x)
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\utils\det_cam_visualizer.py", line 174, in __call__
loss = self.detector(return_loss=True, **self.input_data)
File "E:\Anaconda\envs\openmmlab\lib\site-packages\torch\nn\modules\module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "E:\Anaconda\envs\openmmlab\lib\site-packages\mmcv\runner\fp16_utils.py", line 109, in new_func
return old_func(*args, **kwargs)
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\detectors\base.py", line 172, in forward
return self.forward_train(img, img_metas, **kwargs)
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\detectors\single_stage.py", line 83, in forward_train
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\dense_heads\base_dense_head.py", line 335, in forward_train
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
File "E:\Anaconda\envs\openmmlab\lib\site-packages\mmcv\runner\fp16_utils.py", line 197, in new_func
return old_func(*args, **kwargs)
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\dense_heads\tood_head.py", line 420, in loss
cls_reg_targets = self.get_targets(
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\dense_heads\tood_head.py", line 610, in get_targets
all_bbox_weights, pos_inds_list, neg_inds_list) = multi_apply(
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\core\utils\misc.py", line 30, in multi_apply
return tuple(map(list, zip(*map_results)))
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\models\dense_heads\atss_head.py", line 442, in _get_target_single
assign_result = self.assigner.assign(anchors, num_level_anchors_inside,
File "E:\Work work\Python\Work\Practice\Object Detection\mmdetection\mmdet\core\bbox\assigners\atss_assigner.py", line 174, in assign
assigned_labels[pos_inds] = gt_labels[
RuntimeError: Index put requires the source and destination dtypes match, got Long for the destination and Int for the source.
Process finished with exit code 1
我按照您的步骤做的,这是我的命令python tools/demo/vis_cam.py tools/image/000000000139.jpg configs/fast_rcnn/fast_rcnn_r50_fpn_1x_coco.py work_dirs/FPN/latest.pth --method gradcam --out-dir result
但是会出现如下问题,您可以帮忙解释一下吗?
Traceback (most recent call last):
File "tools/demo/vis_cam.py", line 237, in
python demo/vis_cam.py demo/478.jpg work_dirs/vfnet/vfnet.py work_dirs/vfnet/vfnet/epoch_20.pth --method gradcam
load checkpoint from local path: work_dirs1280/vfnet/vfnet/epoch_20.pth
/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:3609: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
warnings.warn(
Traceback (most recent call last):
File "demo/vis_cam.py", line 238, in
I want to know how to deal with it ,thank you.
Sorry, I didn't run into this problem, but I look at your network, maybe the blogger hasn't implemented it , he's only implemented a few mainstream networks so far。 ------------------ 原始邮件 ------------------ 发件人: "open-mmlab/mmdetection" @.>; 发送时间: 2022年5月26日(星期四) 上午10:04 @.>; @.@.>; 主题: Re: [open-mmlab/mmdetection] [WIP] Support Grad Free and Grad Based CAM (PR #7987)
python demo/vis_cam.py demo/478.jpg work_dirs/vfnet/vfnet.py work_dirs/vfnet/vfnet/epoch_20.pth --method gradcam load checkpoint from local path: work_dirs1280/vfnet/vfnet/epoch_20.pth /home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode) /home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:3609: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details. warnings.warn( Traceback (most recent call last): File "demo/vis_cam.py", line 238, in main() File "demo/vis_cam.py", line 215, in main grayscale_cam = det_cam_visualizer( File "/home/liang/文档/mmdetection/mmdet/utils/det_cam_visualizer.py", line 324, in call return self.cam(img, targets, aug_smooth, eigen_smooth)[0, :] File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/base_cam.py", line 184, in call return self.forward(input_tensor, File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/base_cam.py", line 74, in forward outputs = self.activations_and_grads(input_tensor) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/activations_and_gradients.py", line 42, in call return self.model(x) File "/home/liang/文档/mmdetection/mmdet/utils/det_cam_visualizer.py", line 175, in call loss = self.detector(return_loss=True, **self.input_data) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl return forward_call(*input, **kwargs) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func return old_func(*args, **kwargs) File "/home/liang/文档/mmdetection/mmdet/models/detectors/base.py", line 172, in forward return self.forward_train(img, img_metas, **kwargs) File "/home/liang/文档/mmdetection/mmdet/models/detectors/single_stage.py", line 83, in forward_train losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes, File "/home/liang/文档/mmdetection/mmdet/models/dense_heads/base_dense_head.py", line 335, in forward_train losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 186, in new_func return old_func(*args, **kwargs) TypeError: loss() missing 1 required positional argument: 'img_metas'
I want to know how to deal with it ,thank you.
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.***>
I checked and this is predictive, but why can't it generate a thermal map?
load checkpoint from local path: /content/gdrive/MyDrive/mmdetection/bighead-mask_rcnn/mask_rcnn_r101_fpn_mstrain-poly_3x_coco_20210524_200244-5675c317.pth
/content/gdrive/MyDrive/mmdetection1/mmdet/datasets/utils.py:70: UserWarning: "ImageToTensor" pipeline is replaced by "DefaultFormatBundle" for batch inference. It is recommended to manually replace it in the test data pipeline in your config file.
'data pipeline in your config file.', UserWarning)
Traceback (most recent call last):
File "demo/vis_cam.py", line 238, in
and when i change method to --method eigencam ,it shows:
load checkpoint from local path: /content/gdrive/MyDrive/mmdetection/bighead-mask_rcnn/mask_rcnn_r101_fpn_mstrain-poly_3x_coco_20210524_200244-5675c317.pth /content/gdrive/MyDrive/mmdetection1/mmdet/datasets/utils.py:70: UserWarning: "ImageToTensor" pipeline is replaced by "DefaultFormatBundle" for batch inference. It is recommended to manually replace it in the test data pipeline in your config file. 'data pipeline in your config file.', UserWarning) : cannot connect to X server
vis_cam.py Which file is it?
@hhaAndroid @eilenelxc can you find vis_demo.py i can't the file
This is?
常洁 @.***
------------------ 原始邮件 ------------------ 发件人: "open-mmlab/mmdetection" @.>; 发送时间: 2022年7月29日(星期五) 下午5:23 @.>; @.@.>; 主题: Re: [open-mmlab/mmdetection] [WIP] Support Grad Free and Grad Based CAM (PR #7987)
vis_cam.py Which file is it?
@eilenelxc can you find vis_demo.py i can't the file
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.***>
How can I display the heat map of the specified class? Is there a tutorial for reference? Thank you
when i use swintransformer as mask rcnn's backbone ,i met a problem
Traceback (most recent call last):
File "D:\Swin-Transformer-Object-Detection2\demo\vis_cam.py", line 237, in
can you help me
I can't know transformer. So sorry
---Original--- From: @.> Date: Wed, Nov 30, 2022 15:50 PM To: @.>; Cc: @.@.>; Subject: Re: [open-mmlab/mmdetection] [WIP] Support Grad Free and Grad Based CAM (PR #7987)
when i use swintransformer as mask rcnn's backbone ,i met a problem Traceback (most recent call last): File "D:\Swin-Transformer-Object-Detection2\demo\vis_cam.py", line 237, in main() File "D:\Swin-Transformer-Object-Detection2\demo\vis_cam.py", line 214, in main grayscale_cam = det_cam_visualizer( File "D:\Swin-Transformer-Object-Detection2\demo\det_cam_visualizer.py", line 323, in call return self.cam(img, targets, aug_smooth, eigen_smooth)[0, :] File "D:\swindet_envs\swindet2\lib\site-packages\pytorch_grad_cam\base_cam.py", line 188, in call return self.forward(input_tensor, File "D:\swindet_envs\swindet2\lib\site-packages\pytorch_grad_cam\base_cam.py", line 74, in forward outputs = self.activations_and_grads(input_tensor) File "D:\swindet_envs\swindet2\lib\site-packages\pytorch_grad_cam\activations_and_gradients.py", line 42, in call return self.model(x) File "D:\Swin-Transformer-Object-Detection2\demo\det_cam_visualizer.py", line 174, in call loss = self.detector(return_loss=True, **self.input_data) File "D:\swindet_envs\swindet2\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl result = self.forward(*input, **kwargs) File "e:\anaconda\envs\swin_det\mmcv-1.3.17\mmcv\runner\fp16_utils.py", line 98, in new_func return old_func(*args, **kwargs) File "D:\WORK\Swin-Transformer-Object-Detection-master\mmdet\models\detectors\base.py", line 181, in forward return self.forward_train(img, img_metas, **kwargs) File "D:\WORK\Swin-Transformer-Object-Detection-master\mmdet\models\detectors\two_stage.py", line 142, in forward_train x = self.extract_feat(img) File "D:\WORK\Swin-Transformer-Object-Detection-master\mmdet\models\detectors\two_stage.py", line 82, in extract_feat x = self.backbone(img) File "D:\swindet_envs\swindet2\lib\site-packages\torch\nn\modules\module.py", line 889, in _call_impl result = self.forward(*input, **kwargs) File "D:\WORK\Swin-Transformer-Object-Detection-master\mmdet\models\backbones\swin_transformer.py", line 620, in forward x_out = norm_layer(x_out) File "D:\swindet_envs\swindet2\lib\site-packages\torch\nn\modules\module.py", line 893, in _call_impl hook_result = hook(self, input, result) File "D:\swindet_envs\swindet2\lib\site-packages\pytorch_grad_cam\activations_and_gradients.py", line 23, in save_activation activation = self.reshape_transform(activation) File "D:\Swin-Transformer-Object-Detection2\demo\det_cam_visualizer.py", line 56, in reshape_transform torch.nn.functional.interpolate( File "D:\swindet_envs\swindet2\lib\site-packages\torch\nn\functional.py", line 3475, in interpolate raise ValueError( ValueError: size shape must match input shape. Input is 1D, size is 2
can you help me
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.***>
Excuse me, when I use your code to visualize Faster rcnn, the bboxes and labels are empty. How can I solve this problem

python demo/vis_cam.py demo/478.jpg work_dirs/vfnet/vfnet.py work_dirs/vfnet/vfnet/epoch_20.pth --method gradcam load checkpoint from local path: work_dirs1280/vfnet/vfnet/epoch_20.pth /home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode) /home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/functional.py:3609: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details. warnings.warn( Traceback (most recent call last): File "demo/vis_cam.py", line 238, in main() File "demo/vis_cam.py", line 215, in main grayscale_cam = det_cam_visualizer( File "/home/liang/文档/mmdetection/mmdet/utils/det_cam_visualizer.py", line 324, in call return self.cam(img, targets, aug_smooth, eigen_smooth)[0, :] File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/base_cam.py", line 184, in call return self.forward(input_tensor, File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/base_cam.py", line 74, in forward outputs = self.activations_and_grads(input_tensor) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/pytorch_grad_cam/activations_and_gradients.py", line 42, in call return self.model(x) File "/home/liang/文档/mmdetection/mmdet/utils/det_cam_visualizer.py", line 175, in call loss = self.detector(return_loss=True, **self.input_data) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl return forward_call(*input, **kwargs) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func return old_func(*args, **kwargs) File "/home/liang/文档/mmdetection/mmdet/models/detectors/base.py", line 172, in forward return self.forward_train(img, img_metas, **kwargs) File "/home/liang/文档/mmdetection/mmdet/models/detectors/single_stage.py", line 83, in forward_train losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes, File "/home/liang/文档/mmdetection/mmdet/models/dense_heads/base_dense_head.py", line 335, in forward_train losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore) File "/home/liang/miniconda3/envs/mmdetection/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 186, in new_func return old_func(*args, **kwargs) TypeError: loss() missing 1 required positional argument: 'img_metas'
I want to know how to deal with it ,thank you.
Did you solve it? I had the same problem.
Excuse me, when I use your code to visualize YOLOX, the result shows that 'layer does not exist', AttributeError("'CSPDarknet' object has no attribute 'layer3'"). How to solve this problem?
Sorry ,I don't use Yolo and not find this question
---Original--- From: "xavier @.> Date: Mon, Jan 9, 2023 11:51 AM To: @.>; Cc: @.@.>; Subject: Re: [open-mmlab/mmdetection] [WIP] Support Grad Free and Grad BasedCAM (PR #7987)
Excuse me, when I use your code to visualize YOLOX, the result shows that 'layer does not exist', AttributeError("'CSPDarknet' object has no attribute 'layer3'"). How to solve this problem?
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.***>
对不起,当我使用您的代码可视化 Faster rcnn 时,bbox 和标签是空的。我该如何解决这个问题
I meet the same question,can you tell me how to solve it?
and when i change method to --method eigencam ,it shows:
load checkpoint from local path: /content/gdrive/MyDrive/mmdetection/bighead-mask_rcnn/mask_rcnn_r101_fpn_mstrain-poly_3x_coco_20210524_200244-5675c317.pth /content/gdrive/MyDrive/mmdetection1/mmdet/datasets/utils.py:70: UserWarning: "ImageToTensor" pipeline is replaced by "DefaultFormatBundle" for batch inference. It is recommended to manually replace it in the test data pipeline in your config file. 'data pipeline in your config file.', UserWarning) : cannot connect to X server
请问这个问题解决了吗,我也有同样的问题