mmdeploy
 mmdeploy copied to clipboard
mmdeploy copied to clipboard
[mmdeploy] [error] [trt_net.cpp:28] TRTNet: 3: [executionContext.cpp::nvinfer1::rt::ExecutionContext::setBindingDimensions::924] Error Code 3: API Usage Error (Parameter check failed at: executionContext.cpp::nvinfer1::rt::ExecutionContext::setBindingDimensions::924, condition: mOptimizationProfile >= 0 && mOptimizationProfile < mEngine.getNbOptimizationProfiles()
Could you tell us the way to reproduce this issue?
Also, please post your environment by executing python tools/check_env.py
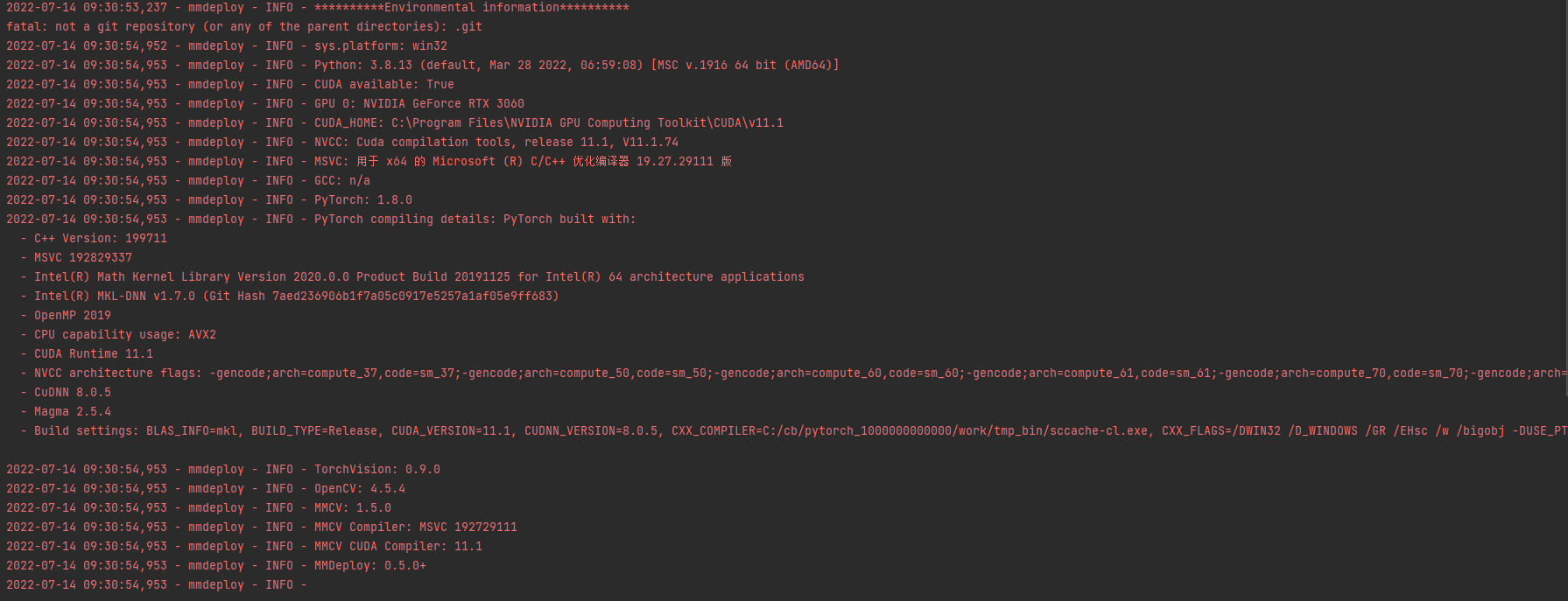

 This is a problem that happened in the process of inference
This is a problem that happened in the process of inference
i use platfrom is windows10
i used model is mmrotate
used config is oriented_rcnn\oriented_rcnn_r50_fpn_1x_dota_le90.py
base = [
'../base/datasets/dotav1.py', '../base/schedules/schedule_1x.py',
'../base/default_runtime.py'
]
angle_version = 'le90' model = dict( type='OrientedRCNN', backbone=dict( type='ResNet', depth=50, num_stages=4, out_indices=(0, 1, 2, 3), frozen_stages=1, norm_cfg=dict(type='BN', requires_grad=True), norm_eval=True, style='pytorch', init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), neck=dict( type='FPN', in_channels=[256, 512, 1024, 2048], out_channels=256, num_outs=5), rpn_head=dict( type='OrientedRPNHead', in_channels=256, feat_channels=256, version=angle_version, anchor_generator=dict( type='AnchorGenerator', scales=[8], ratios=[0.5, 1.0, 2.0], strides=[4, 8, 16, 32, 64]), bbox_coder=dict( type='MidpointOffsetCoder', angle_range=angle_version, target_means=[0.0, 0.0, 0.0, 0.0, 0.0, 0.0], target_stds=[1.0, 1.0, 1.0, 1.0, 0.5, 0.5]), loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0), loss_bbox=dict( type='SmoothL1Loss', beta=0.1111111111111111, loss_weight=1.0)), roi_head=dict( type='OrientedStandardRoIHead', bbox_roi_extractor=dict( type='RotatedSingleRoIExtractor', roi_layer=dict( type='RoIAlignRotated', out_size=7, sample_num=2, clockwise=True), out_channels=256, featmap_strides=[4, 8, 16, 32]), bbox_head=dict( type='RotatedShared2FCBBoxHead', in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=15, bbox_coder=dict( type='DeltaXYWHAOBBoxCoder', angle_range=angle_version, norm_factor=None, edge_swap=True, proj_xy=True, target_means=(.0, .0, .0, .0, .0), target_stds=(0.1, 0.1, 0.2, 0.2, 0.1)), reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))), train_cfg=dict( rpn=dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.3, min_pos_iou=0.3, match_low_quality=True, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=256, pos_fraction=0.5, neg_pos_ub=-1, add_gt_as_proposals=False), allowed_border=0, pos_weight=-1, debug=False), rpn_proposal=dict( nms_pre=2000, max_per_img=2000, nms=dict(type='nms', iou_threshold=0.8), min_bbox_size=0), rcnn=dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.5, match_low_quality=False, iou_calculator=dict(type='RBboxOverlaps2D'), ignore_iof_thr=-1), sampler=dict( type='RRandomSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False)), test_cfg=dict( rpn=dict( nms_pre=2000, max_per_img=2000, nms=dict(type='nms', iou_threshold=0.8), min_bbox_size=0), rcnn=dict( nms_pre=2000, min_bbox_size=0, score_thr=0.05, nms=dict(iou_thr=0.1), max_per_img=2000)))
img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='RResize', img_scale=(1024, 1024)), dict( type='RRandomFlip', flip_ratio=[0.25, 0.25, 0.25], direction=['horizontal', 'vertical', 'diagonal'], version=angle_version), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']) ] data = dict( train=dict(pipeline=train_pipeline, version=angle_version), val=dict(version=angle_version), test=dict(version=angle_version)) log_config = dict( interval = 50, hooks = [ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
optimizer = dict(lr=0.005)

I think it's an environment issue. @irexyc Could you help investigate this issue further?
It seems like the cuda version in your C drive is different from the cudatoolkit that pytorch built with. (I guess it is cuda11.0. If so, please install cuda11.1 instead and remove cuda11.0 relation variable from your system path)
Can you check the cuda, cudnn, tensorrt version in your system path? (tools/check_env.py only check the version of python package dependencies)
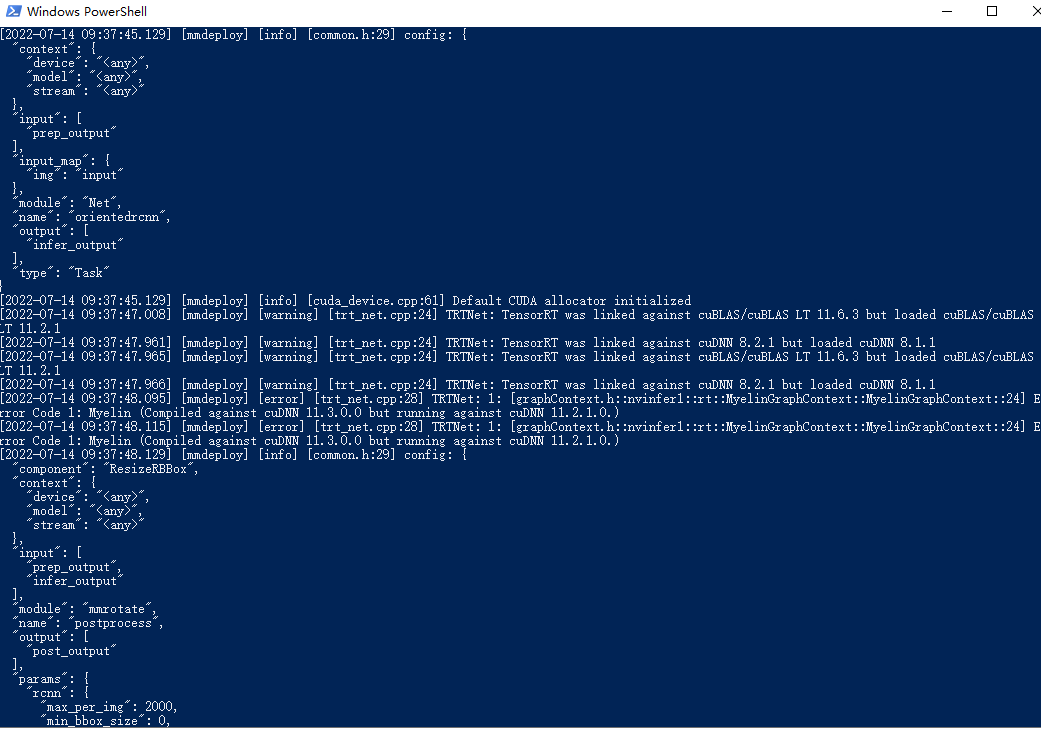
this is i run deploy.py result the end of result has a error about the visualize tensorrt model failed. but it can sussess generate the end2end.engine
D:\anaconda3\envs\mmdeploy\python.exe D:/bushu/mmdeploy-master/tools/deploy.py
2022-07-14 10:13:56,259 - mmdeploy - INFO - Start pipeline mmdeploy.apis.pytorch2onnx.torch2onnx in subprocess
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmdet\models\dense_heads\anchor_head.py:116: UserWarning: DeprecationWarning: num_anchors is deprecated, for consistency or also use num_base_priors instead
warnings.warn('DeprecationWarning: num_anchors is deprecated, '
load checkpoint from local path: D:\pcb\models\xuanzhuan\mmrotate-main\tools\run\6\latest.pth
2022-07-14 10:13:59,738 - mmdeploy - WARNING - DeprecationWarning: get_onnx_config will be deprecated in the future.
2022-07-14 10:13:59,738 - mmdeploy - INFO - Export PyTorch model to ONNX: work_dir/2\end2end.onnx.
D:\bushu\mmdeploy-master\mmdeploy\core\optimizers\function_marker.py:158: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
ys_shape = tuple(int(s) for s in ys.shape)
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmdet\models\dense_heads\anchor_head.py:123: UserWarning: DeprecationWarning: anchor_generator is deprecated, please use "prior_generator" instead
warnings.warn('DeprecationWarning: anchor_generator is deprecated, '
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmdet\core\anchor\anchor_generator.py:333: UserWarning: grid_anchors would be deprecated soon. Please use grid_priors
warnings.warn('grid_anchors would be deprecated soon. '
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmdet\core\anchor\anchor_generator.py:369: UserWarning: single_level_grid_anchors would be deprecated soon. Please use single_level_grid_priors
warnings.warn(
D:\bushu\mmdeploy-master\mmdeploy\codebase\mmrotate\models\rotated_rpn_head.py:79: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
D:\bushu\mmdeploy-master\mmdeploy\pytorch\functions\topk.py:56: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if k > size:
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmrotate\core\bbox\coder\delta_midpointoffset_rbbox_coder.py:78: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert pred_bboxes.size(0) == bboxes.size(0)
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmrotate\core\bbox\coder\delta_midpointoffset_rbbox_coder.py:79: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert bboxes.size(-1) == 4
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmrotate\core\bbox\coder\delta_midpointoffset_rbbox_coder.py:80: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert pred_bboxes.size(-1) == 6
D:\bushu\mmdeploy-master\mmdeploy\codebase\mmrotate\core\post_processing\bbox_nms.py:276: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
int(scores.shape[-1]),
D:\bushu\mmdeploy-master\mmdeploy\mmcv\ops\nms.py:178: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
out_boxes = min(num_boxes, after_topk)
D:\anaconda3\envs\mmdeploy\lib\site-packages\mmrotate\core\bbox\coder\delta_xywha_rbbox_coder.py:101: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert pred_bboxes.size(0) == bboxes.size(0)
D:\bushu\mmdeploy-master\mmdeploy\codebase\mmrotate\core\post_processing\bbox_nms.py:163: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
int(scores.shape[-1]),
D:\bushu\mmdeploy-master\mmdeploy\mmcv\ops\nms_rotated.py:120: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
out_boxes = min(num_boxes, after_topk)
D:\anaconda3\envs\mmdeploy\lib\site-packages\torch\onnx\symbolic_opset9.py:2603: UserWarning: Exporting aten::index operator of advanced indexing in opset 11 is achieved by combination of multiple ONNX operators, including Reshape, Transpose, Concat, and Gather. If indices include negative values, the exported graph will produce incorrect results.
warnings.warn("Exporting aten::index operator of advanced indexing in opset " +
2022-07-14 10:14:07,842 - mmdeploy - INFO - Execute onnx optimize passes.
2022-07-14 10:14:07,843 - mmdeploy - WARNING - Can not optimize model, please build torchscipt extension.
More details: https://github.com/open-mmlab/mmdeploy/blob/master/docs/en/experimental/onnx_optimizer.md
2022-07-14 10:14:08,406 - mmdeploy - INFO - Finish pipeline mmdeploy.apis.pytorch2onnx.torch2onnx
2022-07-14 10:14:10,863 - mmdeploy - INFO - Start pipeline mmdeploy.backend.tensorrt.onnx2tensorrt.onnx2tensorrt in subprocess
2022-07-14 10:14:11,059 - mmdeploy - INFO - Successfully loaded tensorrt plugins from D:\bushu\mmdeploy-master\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
[07/14/2022-10:14:11] [TRT] [I] [MemUsageChange] Init CUDA: CPU +490, GPU +0, now: CPU 10303, GPU 1207 (MiB)
[07/14/2022-10:14:12] [TRT] [I] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 10355 MiB, GPU 1207 MiB
[07/14/2022-10:14:12] [TRT] [I] [MemUsageSnapshot] End constructing builder kernel library: CPU 10530 MiB, GPU 1251 MiB
[07/14/2022-10:14:12] [TRT] [W] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[07/14/2022-10:14:12] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:15] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:16] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:16] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:16] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:16] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:17] [TRT] [I] No importer registered for op: TRTBatchedNMS. Attempting to import as plugin.
[07/14/2022-10:14:17] [TRT] [I] Searching for plugin: TRTBatchedNMS, plugin_version: 1, plugin_namespace:
[07/14/2022-10:14:17] [TRT] [I] Successfully created plugin: TRTBatchedNMS
[07/14/2022-10:14:18] [TRT] [I] No importer registered for op: MMCVMultiLevelRotatedRoiAlign. Attempting to import as plugin.
[07/14/2022-10:14:18] [TRT] [I] Searching for plugin: MMCVMultiLevelRotatedRoiAlign, plugin_version: 1, plugin_namespace:
[07/14/2022-10:14:18] [TRT] [I] Successfully created plugin: MMCVMultiLevelRotatedRoiAlign
[07/14/2022-10:14:18] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:18] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:18] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:18] [TRT] [W] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[07/14/2022-10:14:19] [TRT] [I] No importer registered for op: TRTBatchedRotatedNMS. Attempting to import as plugin.
[07/14/2022-10:14:19] [TRT] [I] Searching for plugin: TRTBatchedRotatedNMS, plugin_version: 1, plugin_namespace:
[07/14/2022-10:14:19] [TRT] [I] Successfully created plugin: TRTBatchedRotatedNMS
[07/14/2022-10:14:20] [TRT] [W] Output type must be INT32 for shape outputs
[07/14/2022-10:14:20] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.3.0
[07/14/2022-10:14:20] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +739, GPU +266, now: CPU 11537, GPU 1517 (MiB)
[07/14/2022-10:14:21] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +418, GPU +258, now: CPU 11955, GPU 1775 (MiB)
[07/14/2022-10:14:21] [TRT] [W] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.0.5
[07/14/2022-10:14:21] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
[07/14/2022-10:15:01] [TRT] [I] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[07/14/2022-10:17:04] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:17:04] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:17:04] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:17:41] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:17:41] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:17:41] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:17:42] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:17:42] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:17:42] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [I] Detected 1 inputs and 2 output network tensors.
[07/14/2022-10:20:25] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:20:25] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:20:25] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [W] Myelin graph with multiple dynamic values may have poor performance if they differ. Dynamic values are:
[07/14/2022-10:20:25] [TRT] [W] (# 2 (SHAPE input))
[07/14/2022-10:20:25] [TRT] [W] (# 3 (SHAPE input))
[07/14/2022-10:20:26] [TRT] [I] Total Host Persistent Memory: 151152
[07/14/2022-10:20:26] [TRT] [I] Total Device Persistent Memory: 82483200
[07/14/2022-10:20:26] [TRT] [I] Total Scratch Memory: 19923456
[07/14/2022-10:20:26] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 9 MiB, GPU 745 MiB
[07/14/2022-10:20:27] [TRT] [I] [BlockAssignment] Algorithm ShiftNTopDown took 1140.04ms to assign 58 blocks to 383 nodes requiring 279896064 bytes.
[07/14/2022-10:20:27] [TRT] [I] Total Activation Memory: 279896064
[07/14/2022-10:20:27] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.3.0
[07/14/2022-10:20:27] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 12995, GPU 2179 (MiB)
[07/14/2022-10:20:27] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 12995, GPU 2187 (MiB)
[07/14/2022-10:20:27] [TRT] [W] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.0.5
[07/14/2022-10:20:27] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +165, now: CPU 0, GPU 165 (MiB)
2022-07-14 10:20:27,702 - mmdeploy - INFO - Finish pipeline mmdeploy.backend.tensorrt.onnx2tensorrt.onnx2tensorrt
2022-07-14 10:20:28,674 - mmdeploy - INFO - visualize tensorrt model start.
2022-07-14 10:20:32,924 - mmdeploy - INFO - Successfully loaded tensorrt plugins from D:\bushu\mmdeploy-master\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
2022-07-14:10:20:32 - mmdeploy - INFO - Successfully loaded tensorrt plugins from D:\bushu\mmdeploy-master\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
2022-07-14 10:20:32,925 - mmdeploy - INFO - Successfully loaded tensorrt plugins from D:\bushu\mmdeploy-master\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
2022-07-14:10:20:32 - mmdeploy - INFO - Successfully loaded tensorrt plugins from D:\bushu\mmdeploy-master\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
[07/14/2022-10:20:33] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.3.0
[07/14/2022-10:20:34] [TRT] [W] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.0.5
[07/14/2022-10:20:34] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.3.0
[07/14/2022-10:20:34] [TRT] [W] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.0.5
#assertionD:\bushu\mmdeploy-master\csrc\mmdeploy\backend_ops\tensorrt\batched_rotated_nms\trt_batched_rotated_nms.cpp,96
2022-07-14 10:21:15,619 - mmdeploy - ERROR - visualize tensorrt model failed.
Process finished with exit code 1
The visualize error is a known issue. It seems that there is a conflict when use pytorch and tensorrt simultaneously. While if you use C api to do the inference, this will not be a problem since it won't use pytorch anymore.
From my experience, the error in your image may due to the mismatch version of cuda in your C drive and cudatoolkit that pytorch built with.
i check my cuda version 11.1 cudnn is 8.1.1 but accroad the problem ,the tensorrt"s cudnn version should 8.2.1. so whether the different of cudnn"s version result this peoblem ?
Can you paste your system path. If you use powershell, you can print the variable with
echo $Env:PATH
Could you please try to use tensorrt-8.2.3.0 and cudnn8.2.1? You may need reconvert the model.
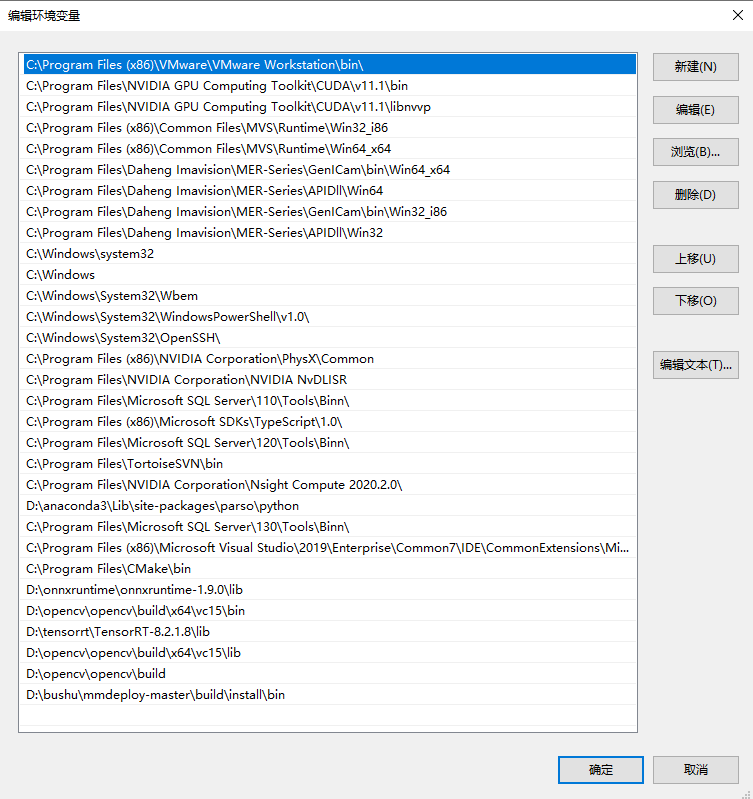
I used tensorrt is 8.2.1.8 and cudnn is 8.1.1.33,cuda is 11.1
i will try you recommend tensorrt-8.2.3.0 , cudnn8.2.1 , cuda 11.1 and check whether it can work
think you very much!
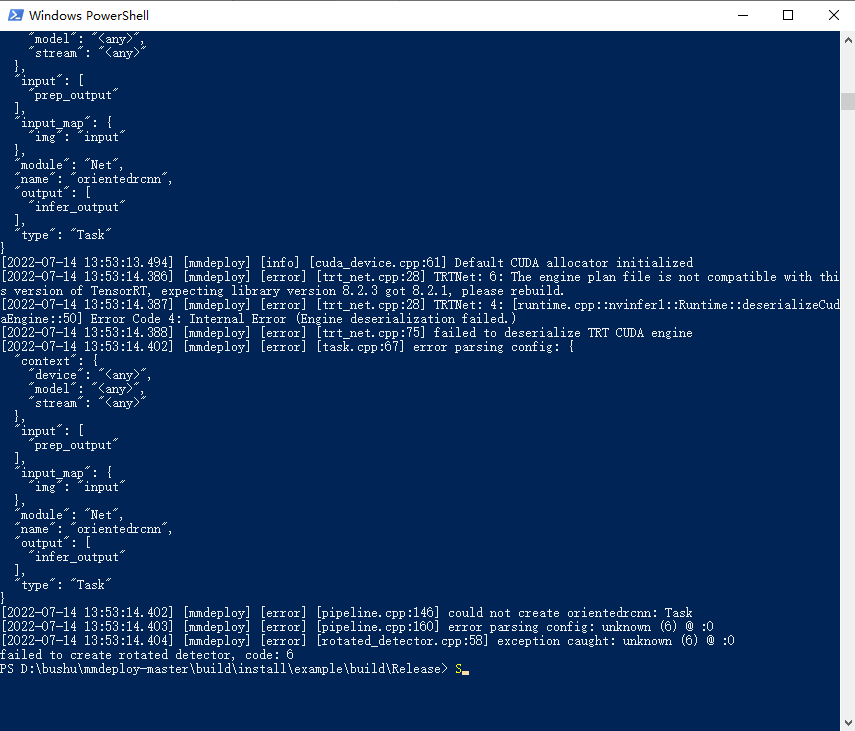

You should reconvert the model since the old model is converted under tensorrt8.2.1
The 'same problem' refer to what?
The 'engine plan file is not compatible with this version of TensorRT' or your original 'Myelin( compiled against cudnn11.3.0.0 but running against cudnn 11.2.1.0)'?
the problem of " The engine plan file is not compatible with this version of TensorRT, expecting library version 8.2.3 got 8.2.1, please rebuild."
Sorry, it is my fault. I didn't see clearly.
What the error means is that the engine file is converted under 8.2.1 but the runtime library that found is 8.2.3.
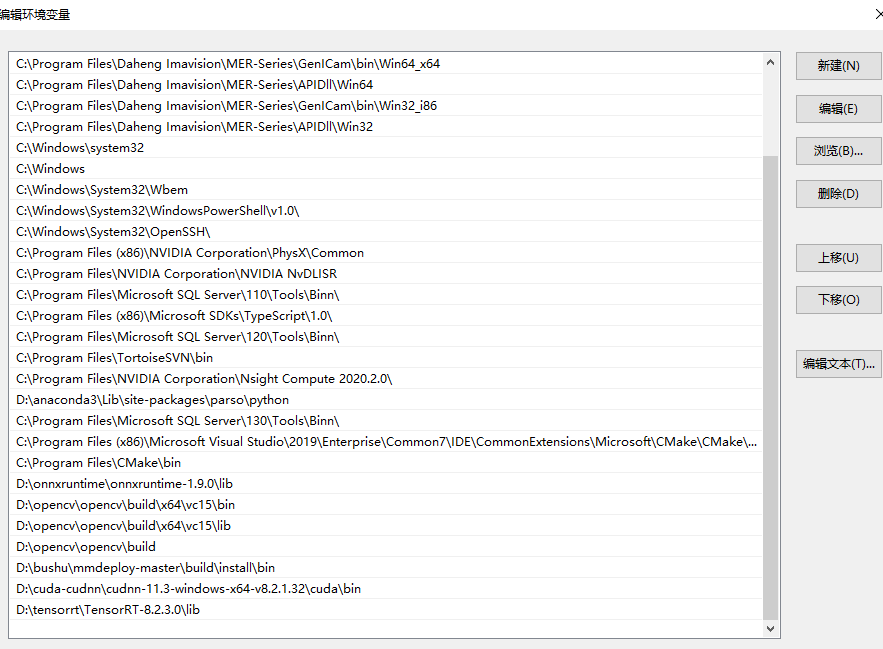 it only have 8.2.3.0,but i dont understand why it load 8.2.1
and the cudnn version is 8.2.1 why it load cudnn-8.0.5, my computer dont have cudnn-8.0.5
it only have 8.2.3.0,but i dont understand why it load 8.2.1
and the cudnn version is 8.2.1 why it load cudnn-8.0.5, my computer dont have cudnn-8.0.5

What confuses you are two things.
-
When convert the model, why the log say that it load cudnn8.0.5 other than 8.2.1 in your path? A: When you install pytorch, it also install cudatoolkit which contains cudnn and cuda to the python lib path(for your pytorch version, it is 8.0.5). And when convert the model, the pytorch load cudnn/cuda dll from python lib path, the tensorrt load cudnn/cuda dll from C drive. The pytorch and tensorrt lib both load cudnn/cuda but with different version. On windows, it seems there is a problem.
-
When do reference, why it says 'The engine plan file is not compatible with this version of TensorRT, expecting library version 8.2.3 got 8.2.1' as you only have 8.2.3 in the path? A: The modol is converted under 8.2.1. Please check if you have multi python virtual env and you actually use the right one
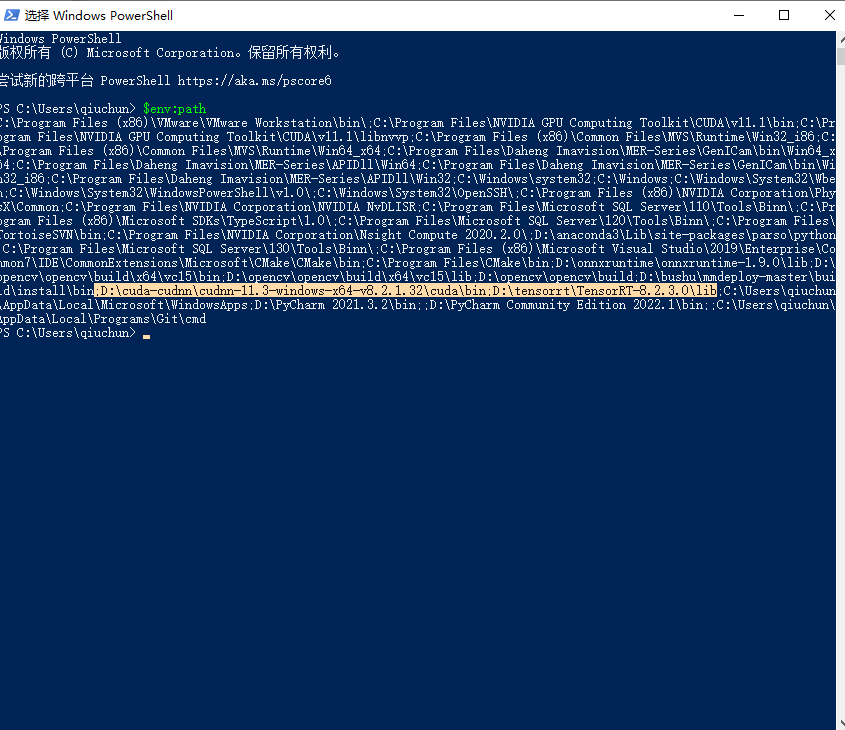 the tensorrt path is correct
the tensorrt path is correct
@qiuchun Did you solve this problem now? I also had the same problem with this one.
@qiuchun Did you solve this problem now? I also had the same problem with this one.
i had solve it you should make model transformation and reasoning in the same terminal environment