mmdeploy
 mmdeploy copied to clipboard
mmdeploy copied to clipboard
When I use mmdeploy-0.5.0 to run the mask RCNN model on the windows platform, the following error messages appear
When I use mmdeploy-0.5.0 to run the latest mask RCNN model on the windows platform, the following error messages appear.
 I use the following version.
I use the following version.
 The configuration file is as follows.(mmdeploy-master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py)
The configuration file is as follows.(mmdeploy-master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py)
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='AutoAugment',
policies=[[{
'type':
'Resize',
'img_scale': [(480, 1333), (512, 1333), (544, 1333), (576, 1333),
(608, 1333), (640, 1333), (672, 1333), (704, 1333),
(736, 1333), (768, 1333), (800, 1333)],
'multiscale_mode':
'value',
'keep_ratio':
True
}],
[{
'type': 'Resize',
'img_scale': [(400, 1333), (500, 1333), (600, 1333)],
'multiscale_mode': 'value',
'keep_ratio': True
}, {
'type': 'RandomCrop',
'crop_type': 'absolute_range',
'crop_size': (384, 600),
'allow_negative_crop': True
}, {
'type':
'Resize',
'img_scale': [(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
'multiscale_mode':
'value',
'override':
True,
'keep_ratio':
True
}]]),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='AutoAugment',
policies=[[{
'type':
'Resize',
'img_scale': [(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
'multiscale_mode':
'value',
'keep_ratio':
True
}],
[{
'type': 'Resize',
'img_scale': [(400, 1333), (500, 1333),
(600, 1333)],
'multiscale_mode': 'value',
'keep_ratio': True
}, {
'type': 'RandomCrop',
'crop_type': 'absolute_range',
'crop_size': (384, 600),
'allow_negative_crop': True
}, {
'type':
'Resize',
'img_scale': [(480, 1333), (512, 1333),
(544, 1333), (576, 1333),
(608, 1333), (640, 1333),
(672, 1333), (704, 1333),
(736, 1333), (768, 1333),
(800, 1333)],
'multiscale_mode':
'value',
'override':
True,
'keep_ratio':
True
}]]),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]),
val=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
persistent_workers=True)
evaluation = dict(metric=['bbox', 'segm'])
optimizer = dict(
constructor='LearningRateDecayOptimizerConstructor',
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(decay_rate=0.95, decay_type='layer_wise', num_layers=6))
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=1000,
warmup_ratio=0.001,
step=[27, 33])
runner = dict(
type='EncryptEpochBasedRunner',
max_epochs=36,
save_each_epoch=True,
encrypt_each_epoch=False,
save_latest=True,
encrypt_latest=False,
save_model_path='/data/xys/train/checkpoint/coco2017_convnext')
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
auto_scale_lr = dict(enable=False, base_batch_size=16)
model = dict(
type='MaskRCNN',
backbone=dict(
type='mmcls.ConvNeXt',
arch='tiny',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth',
prefix='backbone.')),
neck=dict(
type='FPN',
in_channels=[96, 192, 384, 768],
out_channels=64,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=64,
feat_channels=64,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=64,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=64,
fc_out_channels=256,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=64,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=64,
conv_out_channels=64,
num_classes=80,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))
custom_imports = dict(
imports=['mmcls.models', 'sonic_ai.encrypt_epoch_based_runner'],
allow_failed_imports=True)
save_model_path = '/data/xys/train/checkpoint/coco2017_convnext'
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth'
fp16 = dict(loss_scale=dict(init_scale=512))
work_dir = './work_dirs/coco2017_convnext'
auto_resume = False
gpu_ids = range(0, 2)
You may first check if the file is exists:
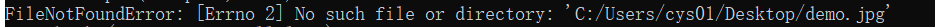
If it still can't convert a model, you can share your full convert command.
@irexyc
Thank you for your reply.
sorry,I uploaded the wrong first screenshot.
Please see the screenshot below.
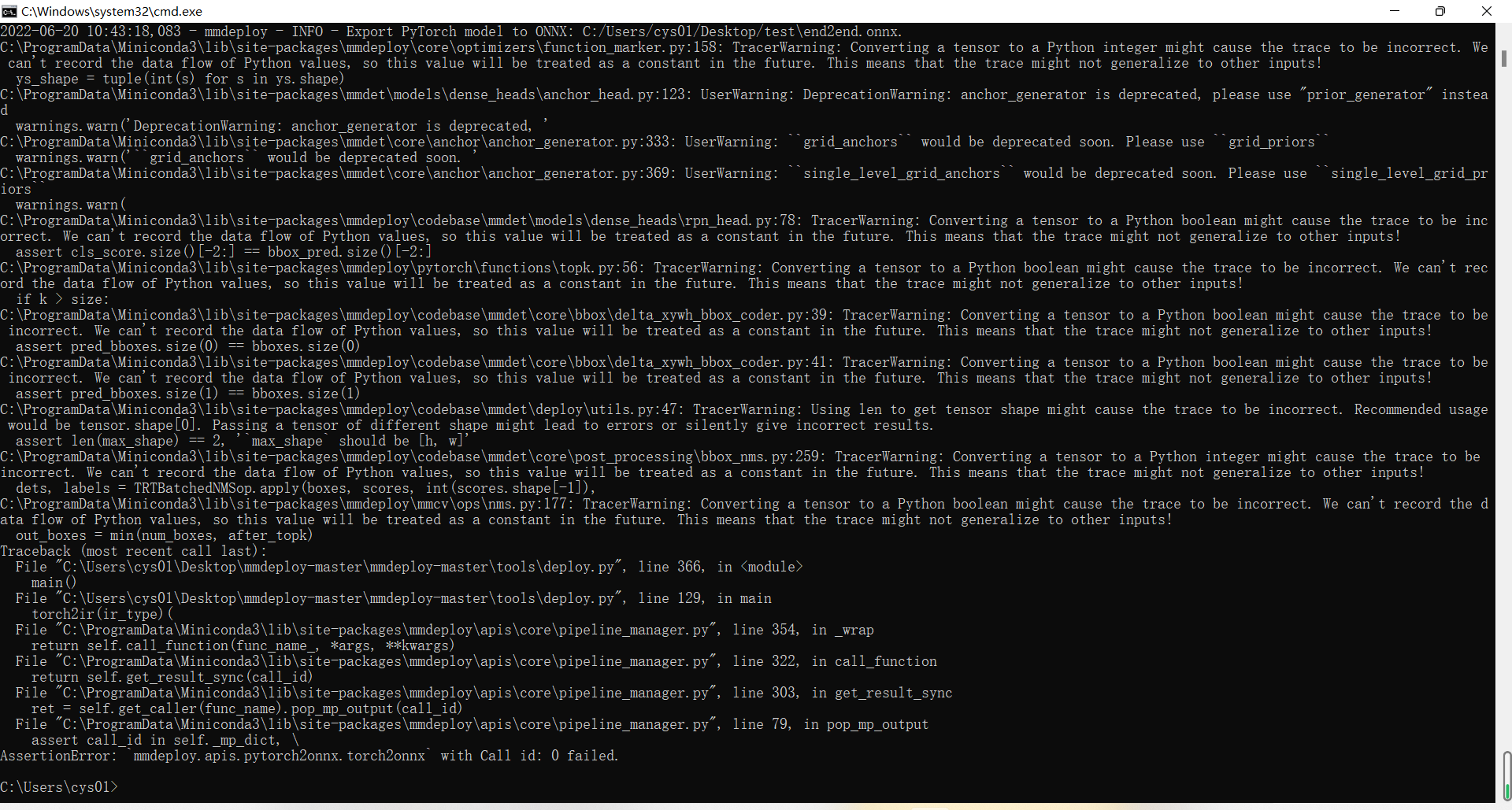
python C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/tools/deploy.py \
C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
C:/Users/cys01/Desktop/mmdetection-master/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
C:/Users/cys01/Desktop/20220614_101947.pth \
C:/Users/cys01/Desktop/demo.jpg \
--work-dir C:/Users/cys01/Desktop/test \
--device cuda:0 \
--dump-info
Seems similiar to songxian's problem. Could you please take a look at this issue? @grimoire
Hi, Could you please add verbose=True in onnx_config
onnx_config = dict(
type='onnx',
export_params=True,
keep_initializers_as_inputs=False,
opset_version=11,
save_file='end2end.onnx',
input_names=['input'],
output_names=['output'],
verbose=True,
input_shape=None)
Which would give you more detail about the error.
@grimoire
 Thank you for your reply.
OK,here are the detail error massages.
Thank you for your reply.
OK,here are the detail error massages.
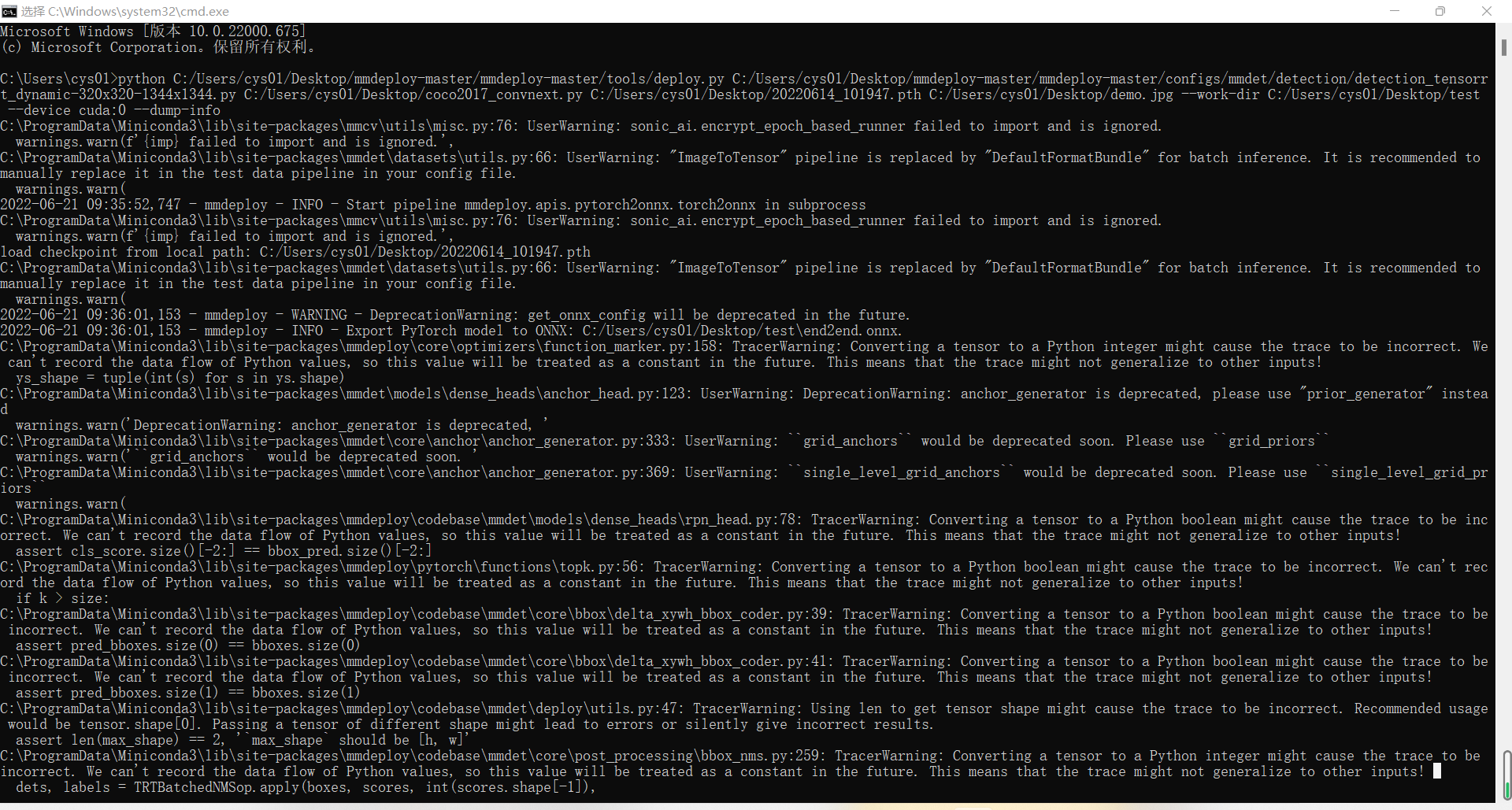

python C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/tools/deploy.py \
C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
C:/Users/cys01/Desktop/coco2017_convnext.py \
C:/Users/cys01/Desktop/20220614_101947.pth \
C:/Users/cys01/Desktop/demo.jpg \
--work-dir C:/Users/cys01/Desktop/test \
--device cuda:0 \
--dump-info
Errr, theoretically the export would give you the graph information when verbose=True. But It is not in your log. Could you please try to convert a simple model such as resnet50 in MMClassification which does not involve any custom ops?
@grimoire Hi,I try to use mask-rcnn and the dataset of coco_2017 as the configuration files, but I still don't see any graph information.
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LoadAnnotations',
with_bbox=True,
with_mask=True,
poly2mask=False),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 800)],
multiscale_mode='range',
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=4,
train=dict(
type='RepeatDataset',
times=1,
dataset=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='LoadAnnotations',
with_bbox=True,
with_mask=True,
poly2mask=False),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 800)],
multiscale_mode='range',
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
])),
val=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric=['bbox', 'segm'])
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[9, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
model = dict(
type='MaskRCNN',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18')),
neck=dict(
type='FPN',
in_channels=[64, 128, 256, 512],
out_channels=64,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=64,
feat_channels=64,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=64,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=64,
fc_out_channels=256,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=64,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=64,
conv_out_channels=64,
num_classes=80,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))
work_dir = './work_dirs/coco2017'
auto_resume = False
gpu_ids = range(0, 4)
python C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/tools/deploy.py \
C:/Users/cys01/Desktop/mmdeploy-master/mmdeploy-master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
C:/Users/cys01/Desktop/coco2017.py \
C:/Users/cys01/Desktop/latest.pth \
C:/Users/cys01/Desktop/demo.jpg \
--work-dir C:/Users/cys01/Desktop/test \
--device cuda:0 \
--dump-info
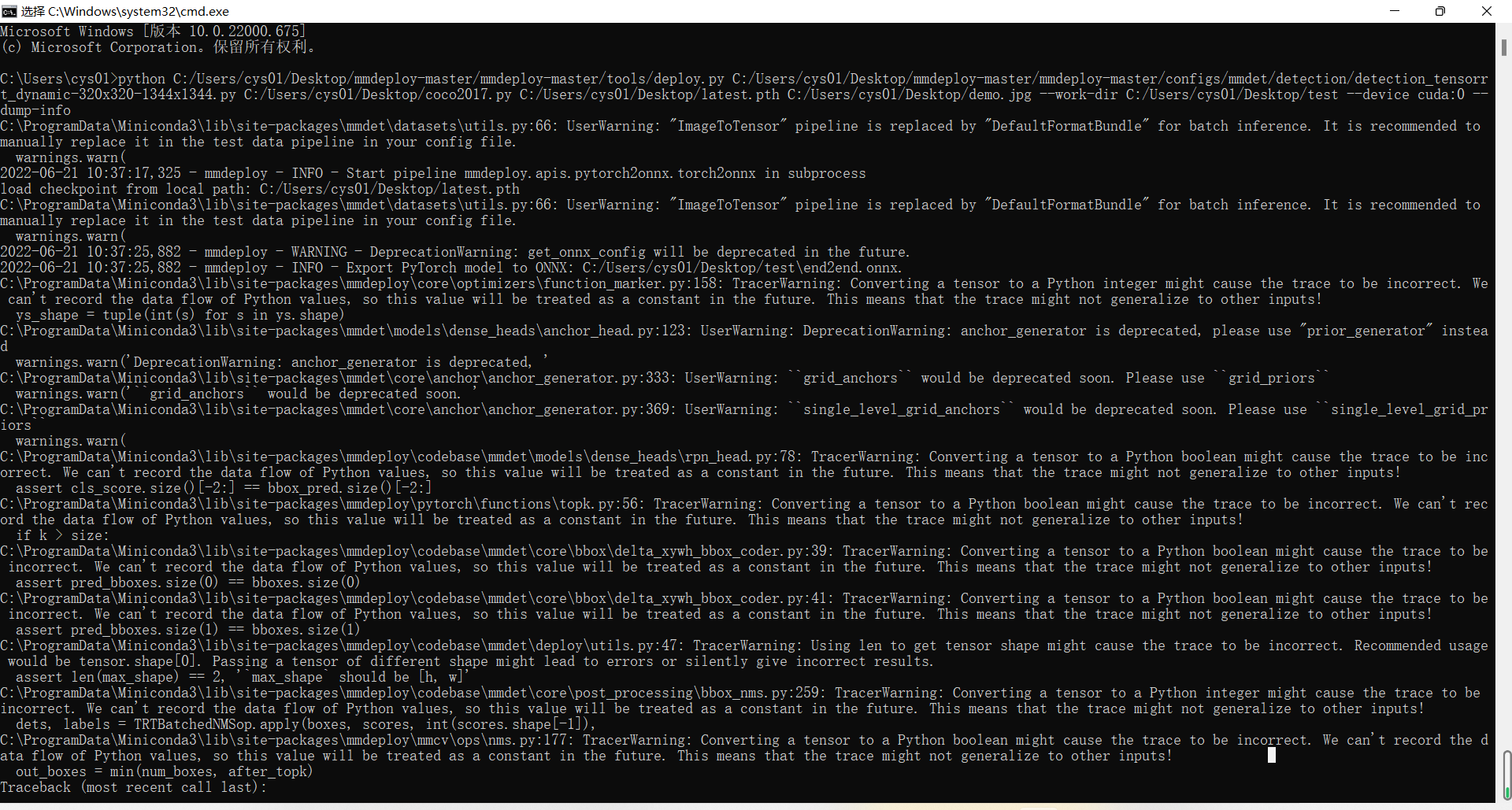
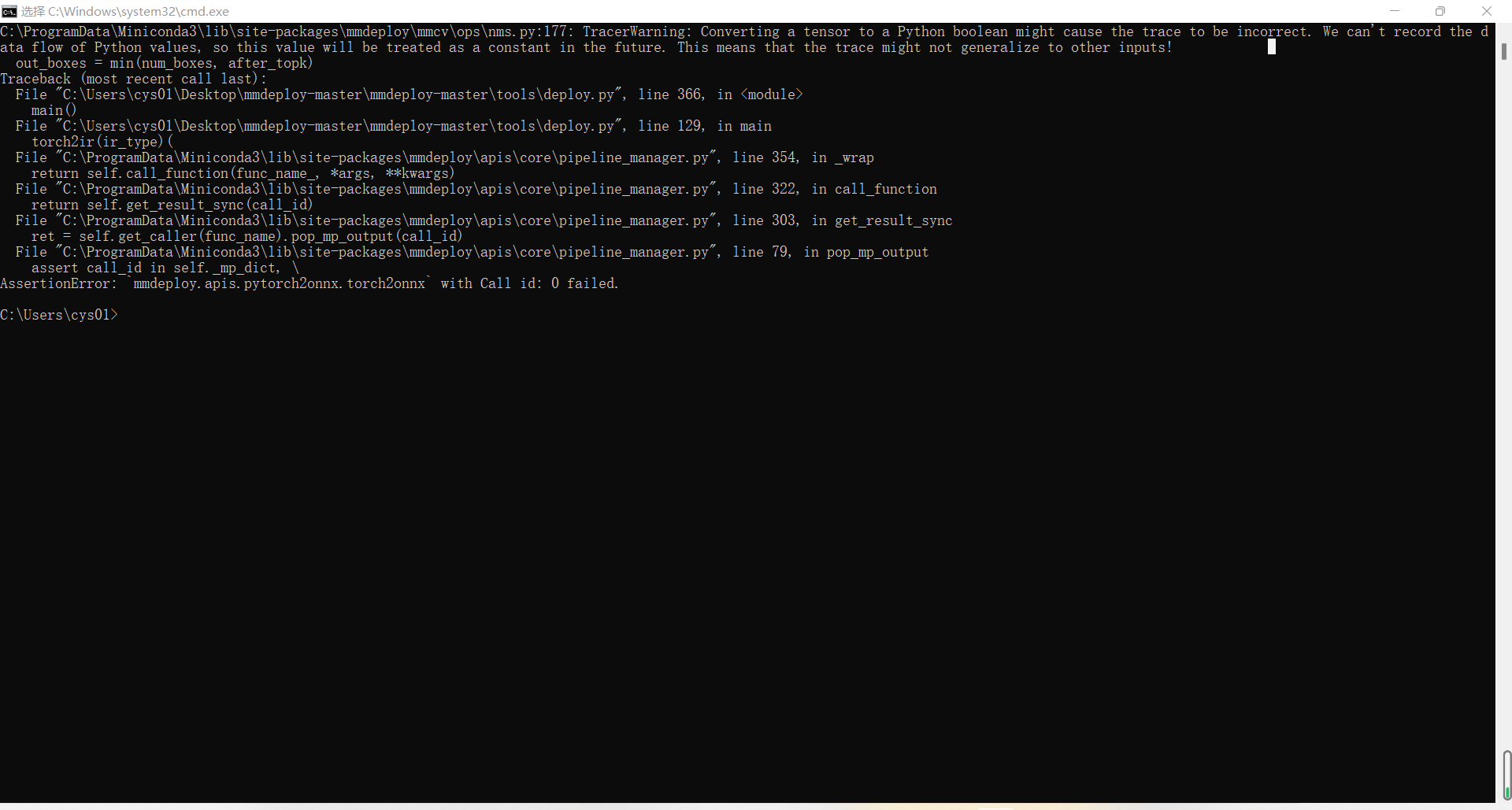
Most models in MMDetection use custom ops in MMCV. I want to known if the error is caused by these ops. So please try convert a simple model like resnet or something like that in MMClassification see if the conversion works.
@grimoire
Thank you for your reply.
When I use pytorch1.11+cuda113,it generates the onnx file.But other versions such as pytorch1.8+cuda111 can only generate three json files.It seems to be a pytorch problem.So I hope mmdeploy in windows supports cuda113 as soon as possible.
Thanks.

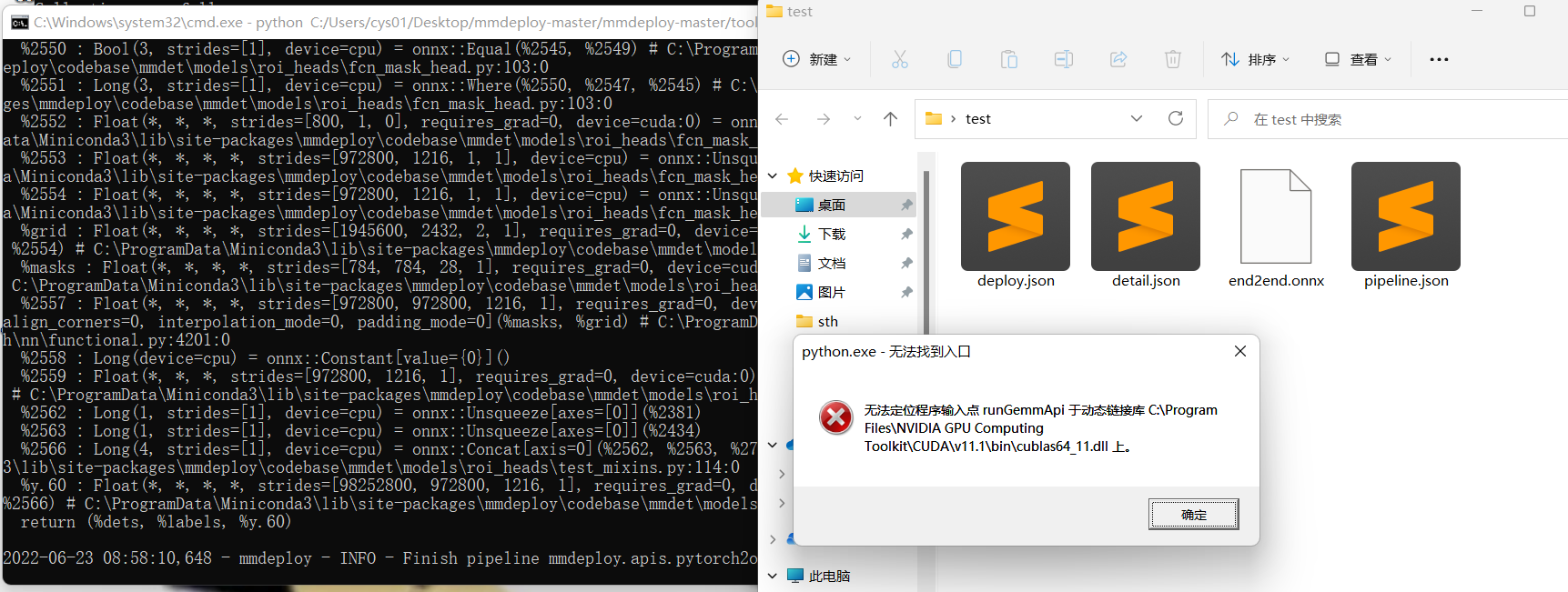

@irexyc Let's check if mmdeploy-cuda11.1 prebuilt package works on cuda11.3. As I tested on Ubuntu platform, it worked.
@irexyc Let's check if mmdeploy-cuda11.1 prebuilt package works on cuda11.3. As I tested on Ubuntu platform, it worked.
I checked, and it worked on windows